

Mašininis mokymasis, ypač didelių pamatų modelių mokymas, labai priklauso nuo duomenų įvairovės ir kokybės. Šie modeliai, iš anksto paruošti naudoti didžiulius duomenų rinkinius, yra daugelio šiuolaikinių AI programų, įskaitant kalbos apdorojimą, vaizdų atpažinimą ir kt., pagrindas. Pamatų modelių efektyvumas priklauso nuo to, kaip gerai jie yra apmokyti, o tai įtakoja į juos įvesti duomenys. Duomenų atrankos ir naudojimo optimizavimas mokymo proceso metu yra nuolatinis iššūkis, ypač kai skaičiavimo ištekliai riboti. Išankstinio mokymo duomenų sudėtis, paskirstymas ir galimybė keisti modelius nepatiriant didelių papildomų išlaidų yra esminiai aspektai šioje srityje.
Pagrindinė šių modelių mokymo problema yra ribotų skaičiavimo išteklių paskirstymas įvairiems duomenų rinkiniams arba duomenų domenams. Pagrindinis iššūkis yra tai, kad nėra aiškių gairių, kaip atrinkti ir subalansuoti duomenis, siekiant maksimaliai padidinti modelio mokymąsi. Tradiciniai metodai remiasi mažesniais modeliais, kad būtų galima eksperimentuoti su skirtingu duomenų paskirstymu arba naudoti dinaminius duomenų koregavimo metodus, kurie priklauso nuo tarpinio serverio modelių. Abu metodai reikalauja didelių papildomų išlaidų laiko ir skaičiavimo galios požiūriu. Didėjant modelių mastui, šie metodai tampa mažiau veiksmingi ir juos sunkiau apibendrinti, todėl didesnių modelių našumas yra neoptimalus. Šis neefektyvumas sukuria didelę kliūtį rengiant didelio masto modelius.
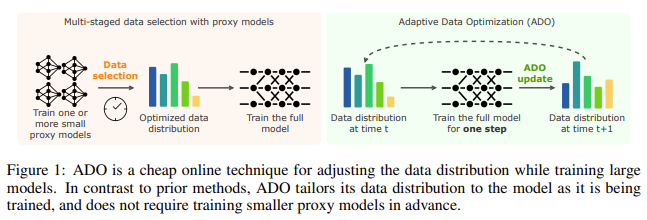
Esami duomenų atrankos tvarkymo metodai paprastai apima išankstinį mažesnių tarpinių modelių mokymą, kad būtų informuojamas pagrindinio modelio mokymo procesas. Šie tarpinio serverio modeliai įvertina optimalų duomenų pasiskirstymą įvairiose srityse. Tačiau šis metodas turi savo trūkumų. Pirma, tai reikalauja papildomų darbo eigos veiksmų, todėl mokymo procesas tampa sudėtingesnis. Antra, šie mažesni modeliai ne visada patikimai prognozuoja, kaip elgsis didesnis modelis, o tai padidina išlaidas ir neveiksmingumą. Pavyzdžiui, norint išmokyti tarpinio serverio modelį pasirinkti duomenis, gali prireikti 760 GPU valandų naudojant 8 Nvidia A100 GPU ir dažnai reikia kelių tarpinio serverio mokymo etapų, kad būtų galima pritaikyti įžvalgas didesniems modeliams.
Tyrėjai iš Carnegie Mellon universiteto, Stanfordo universiteto ir Prinstono universiteto pristatė Adaptyvusis duomenų optimizavimas (ADO)naujas metodas, dinamiškai koreguojantis duomenų paskirstymą treniruotės metu. ADO yra internetinis algoritmas, kuriam nereikia mažesnių tarpinių serverių modelių ar papildomų išorinių duomenų. Jis naudoja mastelio keitimo dėsnius, kad realiuoju laiku įvertintų kiekvieno duomenų srities mokymosi potencialą ir atitinkamai koreguotų duomenų mišinį. Dėl to ADO žymiai lengviau keičiamas ir lengviau integruojamas į esamas darbo eigas, nereikalaujant sudėtingų pakeitimų. Tyrimo grupė parodė, kad ADO gali pasiekti panašų ar net geresnį našumą nei ankstesni metodai, išlaikant skaičiavimo efektyvumą.
ADO esmė slypi gebėjime taikyti mastelio keitimo dėsnius, kad būtų galima numatyti, kokią vertę tam tikras duomenų rinkinys ar domenas suteiks modeliui mokymosi eigoje. Šie mastelio dėsniai įvertina galimą mokymosi iš kiekvieno domeno pagerėjimą ir leidžia ADO koreguoti duomenų paskirstymą. Užuot pasikliavę statinių duomenų politika, ADO patikslina duomenų mišinį, remdamasis realiuoju laiku gaunamu mokymo modelio atsiliepimu. Sistema stebi du pagrindinius rodiklius: domeno mokymosi potencialą, kuris parodo, kiek modelis vis dar gali gauti naudos iš tolesnio optimizavimo tam tikrame domene, ir kreditų priskyrimo balą, kuris matuoja domeno indėlį mažinant mokymo nuostolius. Dėl šio dinaminio koregavimo ADO yra efektyvesnis įrankis, palyginti su tradicine statinių duomenų politika.
ADO našumas buvo išbandytas naudojant įvairius didelio masto kalbų modelius, įskaitant modelius su 124 milijonais ir 1,3 milijardo parametrų. Šie eksperimentai atskleidė, kad ADO gali pagerinti modelio našumą keliuose etalonuose, tuo pačiu pridėdamas tik minimalią skaičiavimo naštą. Pavyzdžiui, viename iš pagrindinių eksperimentų ADO prie 1,3 milijardo parametrų modelio 3,5 dienos mokymo proceso pridėjo mažiau nei 0,4 % papildomo sieninio laikrodžio laiko. Kalbant apie našumą, ADO pagerino modelio tikslumą atliekant nulinio šūvio paskesnes užduotis, viršydama pradinius metodus šešiuose iš septynių etalonų pagal 124 mln. skalę ir keturis iš septynių 1,3 mlrd. skalės etalonų. Pažymėtina, kad ADO pasiekė šį našumą nereikalaujant mažesnių tarpinių modelių ar didelių mokymo proceso modifikacijų, todėl tai yra praktiškesnis ir ekonomiškesnis sprendimas didelio masto modelių mokymui.

Pagrindiniai ADO tyrimo aspektai:
- ADO pašalina tarpinių modelių poreikį, todėl mokymo procesas supaprastinamas.
- Duomenų paskirstymo reguliavimas realiuoju laiku pagal mastelio dėsnius užtikrina optimalų modelio veikimą.
- ADO prie 1,3 milijardo parametrų modelio mokymo laiko pridėjo tik 0,4%.
- Pasiektas geriausias 6 iš 7 etalonų 124M modeliams ir 4 iš 7 1,3B modelių našumo.
- Žymiai sumažina skaičiavimo sąnaudas, susijusias su duomenų atranka didelio masto modelių mokymuose.

Apibendrinant galima pasakyti, kad ADO pristato reikšmingą proveržį optimizuojant duomenų pasirinkimą treniruojant didelius modelius. ADO supaprastina mokymo procesą ir pagerina bendrą modelio našumą, nes nebereikia tarpinių modelių ir dinamiškai koreguoja duomenų paskirstymą naudojant grįžtamąjį ryšį realiuoju laiku. Metodo gebėjimas efektyviai pritaikyti įvairaus dydžio modelius nuo 124 milijonų iki 1,3 milijardo parametrų, todėl jis yra labai pritaikomas. Be to, ADO sumažina skaičiavimo išlaidas, paprastai susijusias su didelių modelių mokymu, todėl tai yra praktiškas sprendimas tobulinti pamatų modelius be papildomų išlaidų. Šis tyrimas pabrėžia pažangaus duomenų optimizavimo svarbą didinant mašininio mokymosi efektyvumą.
Patikrinkite Popierius ir GitHub. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Būsimas tiesioginis internetinis seminaras – 2024 m. spalio 29 d.) Geriausia platforma, skirta tiksliai suderintiems modeliams aptarnauti: „Predibase Inference Engine“ (reklamuojama)
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️






