

Apjungtas mokymasis atsirado kaip medicinos įstaigų mokymosi bendradarbiaujant metodas išsaugant duomenų privatumą. Tačiau ne IID duomenų pobūdis, atsirandantis dėl institucinių specializacijų ir regioninės demografijos skirtumų, kelia didelių iššūkių. Šis nevienalytiškumas lemia klientų dreifą ir neoptimalų pasaulinio modelio veikimą. Esami jungtiniai mokymosi metodai pirmiausia sprendžia šią problemą taikant į modelį orientuotus metodus, pvz., keičiant vietinius mokymo procesus arba visuotines agregavimo strategijas. Vis dėlto šie sprendimai dažnai siūlo nežymius patobulinimus ir reikalauja dažno bendravimo, o tai padidina išlaidas ir kelia susirūpinimą dėl privatumo. Dėl to auga tvirtų, ryšiui efektyvių metodų, kurie galėtų veiksmingai valdyti sunkius ne IID scenarijus, poreikis.
Pastaruoju metu į duomenis orientuoti jungtiniai mokymosi metodai sulaukė dėmesio, siekiant sumažinti duomenų lygio skirtumus sintezuojant ir dalijantis virtualiais duomenimis. Šiais metodais, įskaitant „FedGen“, „FedMix“ ir „FedGAN“, bandoma apytiksliai nustatyti tikrus duomenis, generuoti virtualias reprezentacijas arba dalytis GAN parengtais duomenimis. Tačiau jie susiduria su tokiais iššūkiais kaip žemos kokybės sintezuoti duomenys ir perteklinės žinios. Pavyzdžiui, maišymo metodai gali iškraipyti duomenis, o atsitiktinis duomenų sintezės pasirinkimas dažnai lemia pasikartojančius ir mažiau reikšmingus pasaulinio modelio atnaujinimus. Be to, kai kurie metodai kelia pavojų privatumui ir išlieka neveiksmingi komunikacijos apribotoje aplinkoje. Norint išspręsti šias problemas, reikia pažangių sintezės metodų, kurie užtikrina aukštos kokybės duomenis, sumažina dubliavimą ir optimizuoja žinių gavimą, kad būtų užtikrintas geresnis našumas ne IID sąlygomis.
Tyrėjai iš Pekino universiteto siūlo FedVCK (Federated learning through Valuable Condensed Knowledge) – į duomenis orientuotą jungtinio mokymosi metodą, pritaikytą bendrai medicininių vaizdų analizei. FedVCK sprendžia su IID nesusijusius iššūkius ir sumažina ryšio išlaidas, sutraukdama kiekvieno kliento duomenis į mažą aukštos kokybės duomenų rinkinį, naudodama latentinius platinimo apribojimus. Modeliuojantis metodas užtikrina, kad atrenkamos tik esminės, neperteklinės žinios. Serverio pusėje reliaciniu požiūriu prižiūrimas kontrastinis mokymasis pagerina visuotinio modelio atnaujinimus, nustatydamas griežtas neigiamas klases. Eksperimentai rodo, kad FedVCK pranašesnis už pažangiausius metodus numatymo tikslumu, komunikacijos efektyvumu ir privatumo išsaugojimu, net esant ribotam komunikacijos biudžetui ir esant rimtiems ne IID scenarijams.
FedVCK yra sujungta mokymosi sistema, susidedanti iš dviejų pagrindinių komponentų: kliento pusės žinių kondensavimo ir serverio pusės reliacinio prižiūrimo mokymosi. Kliento pusėje jis naudoja paskirstymo suderinimo metodus, kad sutelktų svarbias žinias iš vietinių duomenų į nedidelį duomenų rinkinį, kurį galima išmokti, vadovaujantis latentiniais paskirstymo apribojimais ir sunkiai nuspėjamų pavyzdžių svarbos atranka. Tai užtikrina, kad sutrumpintas duomenų rinkinys pašalina pasaulinio modelio spragas. Tarptautinis modelis atnaujinamas serverio pusėje naudojant kryžminės entropijos praradimą ir prototipu pagrįstą kontrastinį mokymąsi. Tai pagerina klasių atskyrimą, suderindama funkcijas su jų prototipais ir atitraukdama jas nuo griežtų, neigiamų klasių. Šis kartotinis procesas pagerina našumą.
Siūlomas FedVCK metodas yra į duomenis orientuotas jungtinis mokymosi metodas, skirtas spręsti ne IID duomenų paskirstymo iššūkius atliekant bendradarbiavimo medicininių vaizdų analizę. Jis buvo įvertintas naudojant įvairius duomenų rinkinius, įskaitant storosios žarnos patologiją, tinklainės UŠT nuskaitymus, pilvo kompiuterinę tomografiją, krūtinės ląstos rentgeno spindulius ir bendruosius duomenų rinkinius, tokius kaip CIFAR10 ir ImageNette, apimančius įvairias skiriamąsias gebas ir būdus. Eksperimentai parodė, kad FedVCK duomenų rinkinių tikslumas yra geresnis, palyginti su devyniais baziniais jungtiniais mokymosi metodais. Skirtingai nuo į modelį orientuotų metodų, kurių našumas buvo vidutiniškas, arba į duomenis orientuotus metodus, kurie kovojo su sintezės kokybe ir masteliu, FedVCK efektyviai sutraukė aukštos kokybės žinias, kad pagerintų pasaulinio modelio našumą, išlaikant mažas ryšio išlaidas ir tvirtumą esant rimtiems ne IID scenarijams. .
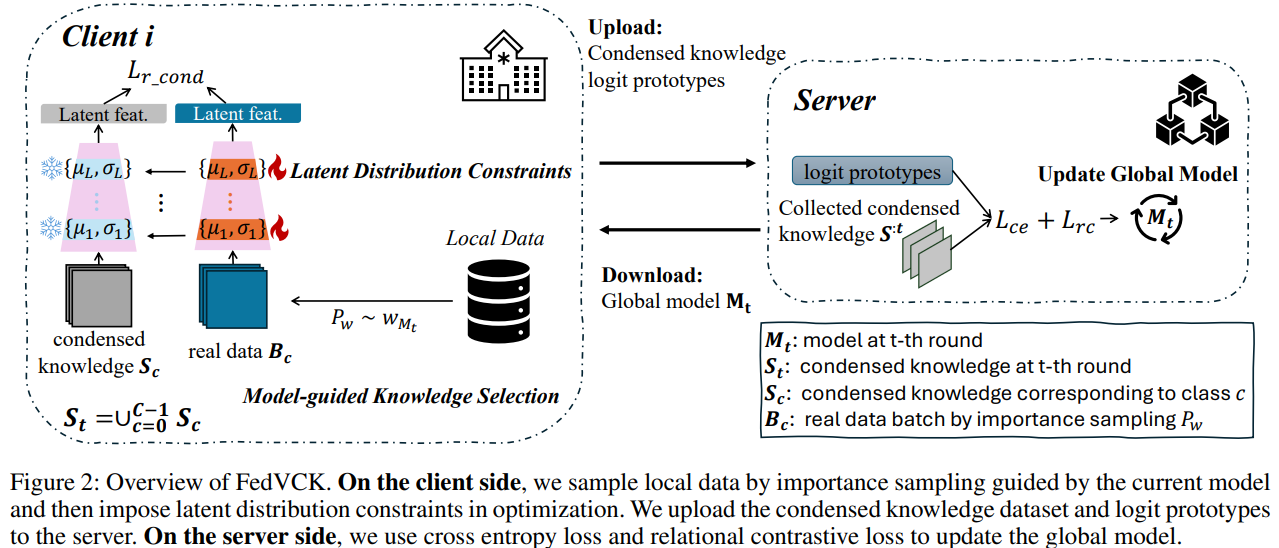
Šis metodas taip pat parodė reikšmingą privatumo išsaugojimą, kaip rodo narystės išvados atakų eksperimentai, kur jis pralenkė tradicinius metodus, tokius kaip FedAvg. Sumažėjęs komunikacijos raundų skaičius, FedVCK sumažino laikinų atakų riziką, pasiūlydama geresnius gynybos rodiklius. Be to, abliacijos tyrimai patvirtino pagrindinių jo komponentų, pvz., modeliu valdomo atrankos, veiksmingumą, kuris optimizavo žinių kondensavimą heterogeniniams duomenų rinkiniams. Vertinimo išplėtimas iki natūralių duomenų rinkinių dar labiau patvirtino jo bendrumą ir tvirtumą. Būsimas darbas skirtas išplėsti FedVCK pritaikomumą papildomiems duomenų būdams, įskaitant 3D KT nuskaitymą, ir patobulinti kondensavimo metodus, kad būtų užtikrintas didesnis efektyvumas ir efektyvumas.
Patikrinkite į Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)




