

LLM išvados yra labai reikalaujančios ištekliams, reikalaujanti didelės atminties ir skaičiavimo galios. Norėdami tai išspręsti, įvairios modelio paralelizmo strategijos paskirsto darbo krūvius keliais GPU, sumažina atminties apribojimus ir padidina greitį. Tensor Parallelim (TP) yra plačiai naudojama technika, kuri padalija svorius ir aktyvacijas visame GPU, leidžiančiai jiems apdoroti vieną užklausą bendradarbiaujant. Skirtingai nuo duomenų ar dujotiekio paralelizmo, kuris apdoroja nepriklausomas duomenų partijas atskiruose įrenginiuose, TP užtikrina efektyvų mastelį, sinchronizuodamas tarpines aktyvacijas visame GPU. Tačiau ši sinchronizacija priklauso nuo „Allreduce“ operacijų blokavimo, sukurdamas ryšio kliūtį, kuri gali žymiai sulėtinti išvadą, kartais prisidedant prie beveik 38% viso latencijos, net ir esant didelėms tarpusavio ryšiams, tokiems kaip „NVLink“.
Ankstesni tyrimai bandė sušvelninti komunikacijos vėlavimus, sutampant skaičiavimu su duomenų perdavimu. Tokie metodai kaip sulieti GPU branduoliai, skirti „Matrix“ operacijoms ir naudojant domenams skirtas kalbas (DSL), siekiant optimizuoti paskirstytus darbo krūvius, parodė pažadą. Tačiau šiems metodams dažnai reikia išsamų žemo lygio optimizavimo, todėl juos sunku įgyvendinti standartiniuose ML sistemose, tokiose kaip „Pytorch“ ir „Jax“. Be to, atsižvelgiant į greitą aparatūros greitintuvų ir sujungimų raidą, tokius optimizavimus dažnai reikia pertvarkyti naujoms architektūroms. Buvo ištirtos alternatyvios strategijos, įskaitant sekos paralelizmą ir smulkiagrūdį veikimo skilimą, siekiant pagerinti TP efektyvumą, tačiau komunikacijos vėlavimas išlieka esminiu didelio masto paskirstytų išvadų apribojimu.
Tyrėjai iš tokių institucijų kaip USC, MIT ir Princetonas pristatė kopėčių liekanas – modelio modifikaciją, kuri padidina tensorių paralelizmo efektyvumą, atsiejant skaičiavimą nuo komunikacijos. Užuot pakeitę žemo lygio branduolius, kopėčių likučių liekanos jungtys, leidžiančios sutapti ir mažinti ryšio kliūtis. Taikomas 70B parametro transformatoriui, jis pasiekia 30% išvadų greitį per aštuonis GPU. 1B ir 3B kopėčių transformatorių modeliai nuo nulio palaiko našumo paritetą su standartiniais transformatoriais. Be to, adaptuojant LLAMA-3.1-8B su minimaliu perkvalifikavimo konservų tikslumu. Šis keičiamas požiūris palengvina kelių GPU ir kryžminio mazgo diegimą ir plačiai taikomas liekanoms pagrįstoms architektūroms.
Naudojant kopėčių liekanos architektūrą, kopėčių transformatorius padidina transformatoriaus efektyvumą, įgalindamas komunikacijos ir kompakcijos sutapimą. Jis nukreipia likusius jungtis skirtingai, leisdamas asinchronines operacijas, sumažinančias ryšio kliūtis. Įvairių modelių dydžių, įskaitant „LLAMA-3 70B“, bandymai rodo iki 29% greičio, kurio išvados pralaidumas yra 29%, o padidėjimas siekia 60% lėtesnių ryšių nustatymų. Įtraukus kopėčių likučius, architektūra pasiekia greitesnį žetonų apdorojimą ir mažesnį latenciją, neprarandant modelio tikslumo. Šis požiūris įrodo, kad naudingas net ir įvairių mazgų sąrankose, parodant daugiau nei 30% didelio masto modelių, tokių kaip „LLAMA 3.1 405B“, pagerėjimą, todėl jis yra efektyvus daugiagyslių GPU diegimui.
Tyrime įvertinamas kopėčių liekanos poveikis modelio našumui, atliekant kopėčių transformatorius (1B ir 3B) nuo nulio ir palyginus juos su standartiniais ir lygiagrečiais transformatoriais 100B žetonuose iš „Fineweb-Edu“. Rezultatai rodo, kad kopėčių transformatoriai veikia panašiai kaip standartiniai modeliai 1B skalėje, bet šiek tiek blogiau – 3B. Mes taip pat taikome kopėčių likučius LLAMA-3.1-8B-Instruct viršutiniams sluoksniams, radę pradinį generatyvinių užduočių našumo kritimą, atkuriamą pertvarkant. Po priėmimo, išvados greitis pagerėja 21%, kai prarandama minimaliai. Rezultatai rodo, kad kopėčių likučiai gali pagreitinti modelius be reikšmingo skilimo, nes gali būti tolesnis optimizavimas naudojant pažangių adaptacijos metodus.
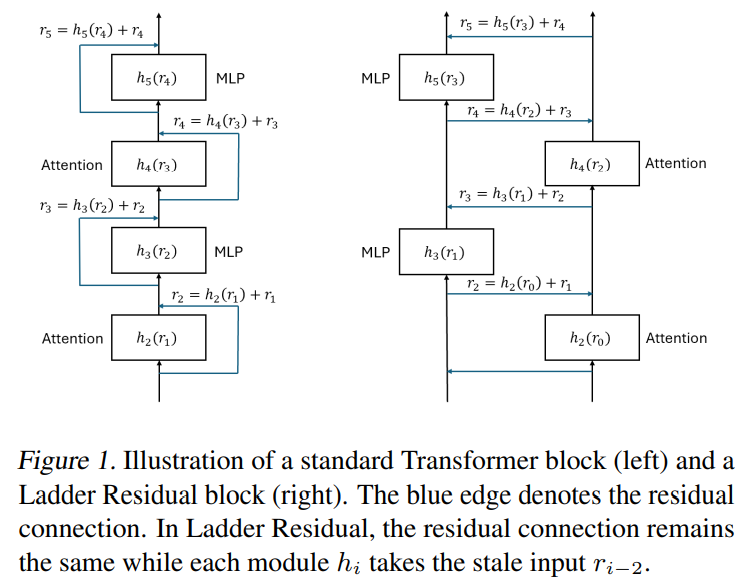
Apibendrinant galima pasakyti, kad tyrimas siūlo kopėčių liekaną-architektūrinę modifikaciją, leidžiančią efektyviai komunikacijos ir komputacijos sutapimui modelio paralelizme, pagerinant greitį nepakenkiant našumui. Taikoma tensoriaus paralelizmui, jis sustiprina didelius modelio išvadas, atsiejant komunikaciją iš skaičiavimo. Kopėčių transformatorių bandymai (1B ir 3B modeliai) rodo, kad jie veikia panašiai kaip standartiniai transformatoriai, pasiekdami daugiau nei 55% greitį. Taikant kopėčių likučius lama-3.1-8b, reikia tik lengvo perkvalifikavimo, kad būtų galima gauti 21% išvadų greitį, ir išlaikyti originalų našumą. Šis požiūris sumažina brangius sujungimus, o tai rodo, kad kartu galima optimizuoti modelio architektūrą ir išvadų sistemas. Pateikiamas replikacijos kodas.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
„MarktechPost“ ir „IIT Madras“ dvigubo laipsnio studentė konsultacinė Sana Hassan aistringai taiko technologijas ir AI, kad galėtų spręsti realaus pasaulio iššūkius. Turėdamas didelį susidomėjimą išspręsti praktines problemas, jis pateikia naują perspektyvą AI ir realaus gyvenimo sprendimų sankryžai.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo






