

LLM suteikė mums galimybę labai efektyviai, patikimai ir greitai apdoroti didelius tekstinių duomenų kiekius. Vienas iš populiariausių naudojimo atvejų, atsiradusių per pastaruosius dvejus metus, yra „Retrieval-Augmented Generation“ (RAG).
RAG leidžia paimti daugybę dokumentų (nuo poros iki net šimto tūkstančių), sukurti žinių duomenų bazę su dokumentais, o tada atlikti jos užklausas ir pagal dokumentus gauti atsakymus su atitinkamais šaltiniais.
Užuot tekę ieškoti rankiniu būdu, o tai užtruktų valandas ar net dienas, galime priversti LLM mūsų ieškoti per kelias sekundes.
Debesis pagrįstas vs vietinis
Kad RAG sistema veiktų, yra dvi dalys: žinių duomenų bazė ir LLM. Pagalvokite apie pirmąjį kaip apie biblioteką, o apie antrąjį kaip apie labai efektyvų bibliotekos darbuotoją.
Pirmasis dizaino sprendimas kuriant tokią sistemą yra tai, ar norite ją talpinti debesyje, ar vietoje. Vietinis diegimas turi didelių sąnaudų pranašumą ir taip pat padeda apsaugoti jūsų privatumą. Kita vertus, debesys gali pasiūlyti mažas paleidimo išlaidas ir mažai priežiūros arba visai jos nereikia.
Siekdami aiškiai parodyti su RAG susijusias koncepcijas, šiame vadove pasirinksime debesies diegimą, tačiau pabaigoje taip pat paliksime pastabų apie vietinį naudojimą.
Žinių (vektorių) duomenų bazė
Taigi pirmas dalykas, kurį turime padaryti, yra sukurti žinių duomenų bazę (techniškai vadinamą vektorine duomenų baze). Tai atliekama paleidžiant dokumentus per įdėjimo modelį, kuris iš kiekvieno sukurs vektorių. Įdėjimo modeliai labai gerai supranta tekstą, o sugeneruoti vektoriai turės panašius dokumentus vektorinėje erdvėje.
Tai nepaprastai patogu, ir mes galime tai iliustruoti nubraižydami keturių hipotetinės organizacijos dokumentų vektorius 2D vektorių erdvėje:
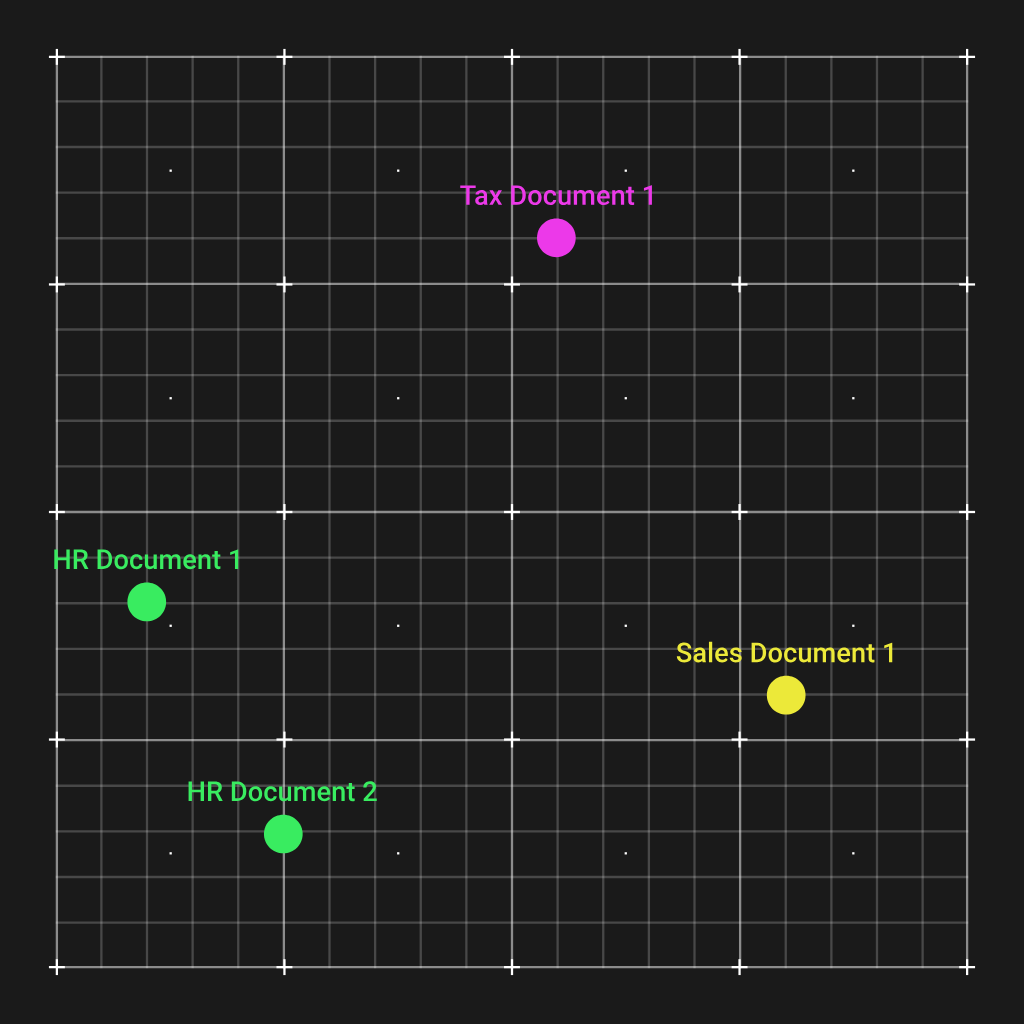
Kaip matote, du žmogiškųjų išteklių dokumentai buvo sugrupuoti ir yra toli nuo kitų dokumentų tipų. Dabar tai mums padeda tai, kad kai gauname klausimą dėl HR, galime apskaičiuoti šio klausimo įdėjimo vektorių, kuris taip pat bus artimas dviems HR dokumentams.
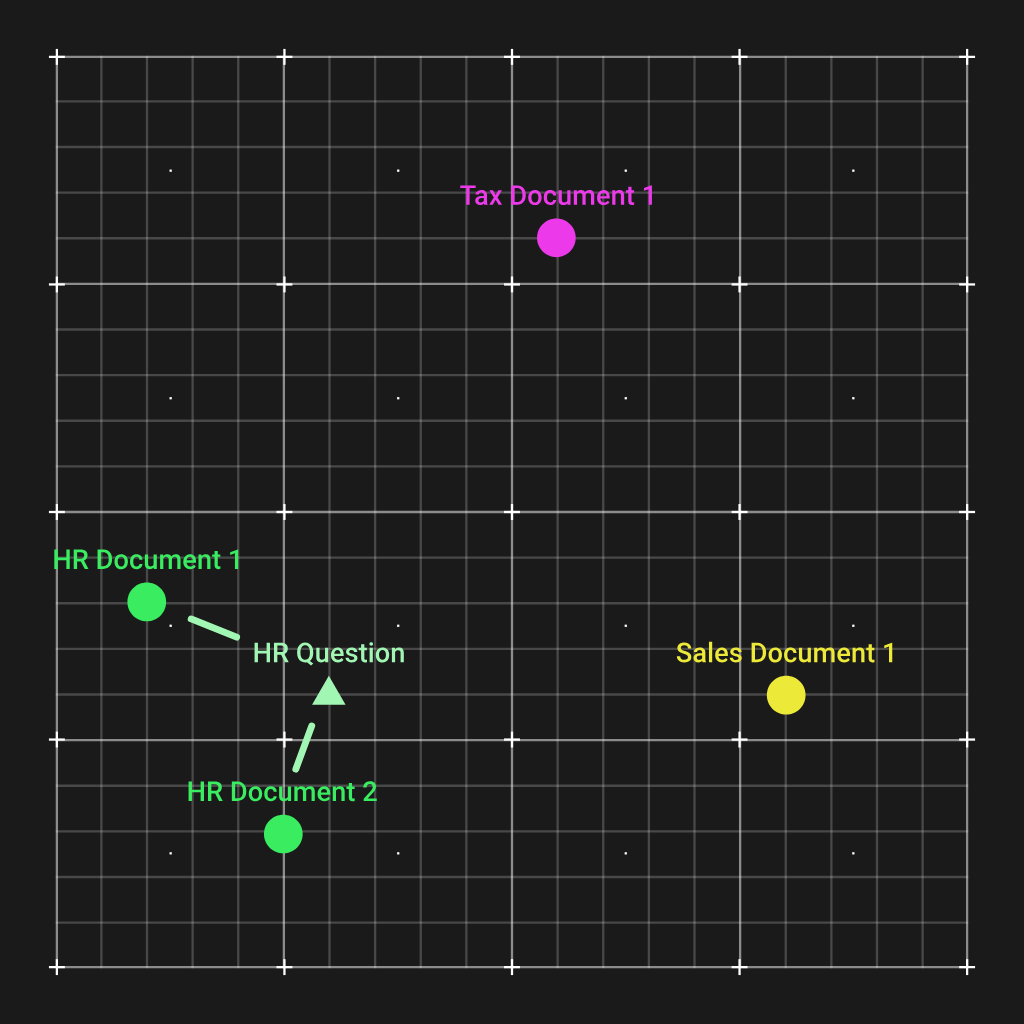
Ir atlikdami paprastą euklido atstumo apskaičiavimą, galime suderinti svarbiausius dokumentus, kuriuos reikia pateikti LLM, kad jis galėtų atsakyti į klausimą.
Galima rinktis iš daugybės įterpimo algoritmų, iš kurių visi lyginami MTEB pirmaujančiųjų sąraše. Įdomus faktas yra tai, kad daugelis atvirojo kodo modelių pirmauja, palyginti su patentuotais teikėjais, tokiais kaip OpenAI.
Be bendro balo, dar du stulpeliai, į kuriuos reikia atsižvelgti pirmaujančiųjų sąraše, yra modelio dydis ir maksimalus kiekvieno modelio prieigos raktas.
Modelio dydis lems, kiek V (RAM) reikės modeliui įkelti į atmintį, taip pat kaip greitai bus atliekami įdėjimo skaičiavimai. Kiekvienas modelis gali įterpti tik tam tikrą žetonų kiekį, todėl prieš įterpiant labai didelius failus gali tekti padalyti.
Galiausiai, modeliai gali įterpti tik tekstą, todėl visus PDF failus reikės konvertuoti, o turtingi elementai, pvz., vaizdai, turėtų būti su antraštėmis (naudojant AI vaizdo antraštės modelį) arba išmesti.
Atvirojo kodo vietinio įterpimo modelius galima paleisti vietoje naudojant transformatorius. Jei naudojate OpenAI įterpimo modelį, jums reikės OpenAI API rakto.
Čia yra „Python“ kodas, skirtas sukurti įterpimus naudojant „OpenAI“ API ir paprastą rinkmenų failų sistema pagrįstą vektorinę duomenų bazę:
import os
from openai import OpenAI
import pickle
openai = OpenAI(
api_key="your_openai_api_key"
)
directory = "doc1"
embeddings_store = {}
def embed_text(text):
"""Embed text using OpenAI embeddings."""
response = openai.embeddings.create(
input=text,
model="text-embedding-3-large"
)
return response.data(0).embedding
def process_and_store_files(directory):
"""Process .txt files, embed them, and store in-memory."""
for filename in os.listdir(directory):
if filename.endswith(".txt"):
file_path = os.path.join(directory, filename)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
embedding = embed_text(content)
embeddings_store(filename) = embedding
print(f"Stored embedding for {filename}")
def save_embeddings_to_file(file_path):
"""Save the embeddings dictionary to a file."""
with open(file_path, 'wb') as f:
pickle.dump(embeddings_store, f)
print(f"Embeddings saved to {file_path}")
def load_embeddings_from_file(file_path):
"""Load embeddings dictionary from a file."""
with open(file_path, 'rb') as f:
embeddings_store = pickle.load(f)
print(f"Embeddings loaded from {file_path}")
return embeddings_store
process_and_store_files(directory)
save_embeddings_to_file("embeddings_store.pkl")
LLM
Dabar, kai turime duomenų bazėje saugomus dokumentus, sukurkime funkciją, kuri pagal užklausą gautų 3 svarbiausius dokumentus:
import numpy as np
def get_top_k_relevant(query, embeddings_store, top_k=3):
"""
Given a query string and a dictionary of document embeddings,
return the top_k documents most relevant (lowest Euclidean distance).
"""
query_embedding = embed_text(query)
distances = ()
for doc_id, doc_embedding in embeddings_store.items():
dist = np.linalg.norm(np.array(query_embedding) - np.array(doc_embedding))
distances.append((doc_id, dist))
distances.sort(key=lambda x: x(1))
return distances(:top_k)
Ir dabar, kai turime dokumentus, ateina paprasta dalis, kuri ragina mūsų LLM, šiuo atveju GPT-4o, pateikti atsakymą, pagrįstą jais:
from openai import OpenAI
openai = OpenAI(
api_key="your_openai_api_key"
)
def answer_query_with_context(query, doc_store, embeddings_store, top_k=3):
"""
Given a query, find the top_k most relevant documents and prompt GPT-4o
to answer the query using those documents as context.
"""
best_matches = get_top_k_relevant(query, embeddings_store, top_k)
context = ""
for doc_id, distance in best_matches:
doc_content = doc_store.get(doc_id, "")
context += f"--- Document: {doc_id} (Distance: {distance:.4f}) ---\n{doc_content}\n\n"
completion = openai.chat.completions.create(
model="gpt-4o",
messages=(
{
"role": "system",
"content": (
"You are a helpful assistant. Use the provided context to answer the user’s query. "
"If the answer isn't in the provided context, say you don't have enough information."
)
},
{
"role": "user",
"content": (
f"Context:\n{context}\n"
f"Question:\n{query}\n\n"
"Please provide a concise, accurate answer based on the above documents."
)
}
),
temperature=0.7
)
answer = completion.choices(0).message.content
return answer
Išvada
Štai jūs tai turite! Tai intuityvus RAG įgyvendinimas, kurį galima tobulinti. Štai keletas idėjų, kur eiti toliau:



