

Mašininio mokymosi raida padarė didelę pažangą kalbos modeliuose, kurie yra esminiai tokiems uždaviniams kaip teksto generavimas ir atsakymas į klausimus. Tarp jų transformatoriai ir būsenos erdvės modeliai (SSM) yra labai svarbūs, tačiau jų efektyvumas tvarkant ilgas sekas sukėlė iššūkių. Didėjant sekos ilgiui, tradiciniai transformatoriai kenčia nuo kvadratinio sudėtingumo, todėl atsiranda pernelyg didelių atminties ir skaičiavimo reikalavimų. Siekdami išspręsti šias problemas, mokslininkai ir organizacijos ištyrė alternatyvias architektūras, tokias kaip Mamba – tiesinio sudėtingumo būsenos erdvės modelis, užtikrinantis mastelio keitimą ir efektyvumą atliekant ilgo konteksto užduotis.
Didelio masto kalbų modeliai dažnai susiduria su sunkumais valdydami skaičiavimo išlaidas, ypač dėl to, kad jie apima milijardus parametrų. Pavyzdžiui, nors Mamba siūlo linijinio sudėtingumo pranašumus, dėl didėjančio dydžio jos sunaudojama daug energijos ir patiriamos mokymo išlaidos, o tai apsunkina diegimą. Šiuos apribojimus dar labiau padidina dideli modelių, pvz., GPT pagrindu sukurtų architektūrų, išteklių poreikiai, kurie tradiciškai mokomi ir daromos išvados visu tikslumu (pvz., FP16 arba BF16). Be to, augant veiksmingo ir keičiamo DI poreikiui, itin svarbu ištirti ekstremalius kvantavimo metodus, kad būtų užtikrintas praktiškas jų panaudojimas ribotų išteklių sąlygomis.
Tyrėjai ištyrė tokius metodus kaip genėjimas, mažo bitų kvantavimas ir pagrindinės vertės talpyklos optimizavimas, kad sumažintų šiuos iššūkius. Kvantifikavimas, kuris sumažina modelio svorių bitų plotį, parodė daug žadančius rezultatus suglaudinant modelius be esminio veikimo pablogėjimo. Tačiau dauguma šių pastangų sutelktos į transformatorių modelius. Vis dar reikia ištirti SSM, ypač Mamba, elgseną esant ekstremaliam kvantavimui, sukuriant spragą kuriant keičiamo dydžio ir efektyvius būsenos erdvės modelius, skirtus realaus pasaulio programoms.
Mohamedo bin Zayedo dirbtinio intelekto universiteto ir Carnegie Mellon universiteto mokslininkai pristatė Bi-Mamba1 bito keičiamo dydžio Mamba architektūra, sukurta mažai atminties turintiems ir didelio efektyvumo scenarijams. Šis novatoriškas metodas taiko dvejetainį mokymą „Mamba“ būsenos erdvės sistemai, leidžiančią ekstremalią kvantavimą išlaikant konkurencingą našumą. Bi-Mamba buvo sukurta 780 milijonų, 1,3 milijardų ir 2,7 milijardų parametrų modelių ir buvo apmokyta nuo nulio naudojant autoregresinį distiliavimo nuostolį. Modelyje naudojami didelio tikslumo mokytojų modeliai, tokie kaip LLaMA2-7B, kad būtų galima vadovauti mokymui, užtikrinant tvirtą našumą.
Bi-Mamba architektūroje naudojamas selektyvus linijinių modulių dvejetainis sujungimas, kartu išlaikant kitus komponentus visiškai tiksliai, kad būtų subalansuotas efektyvumas ir našumas. Įvesties ir išvesties projekcijos yra dvejetainės, naudojant FBI-Linear modulius, kurie integruoja išmokstamus mastelio keitimo ir poslinkio veiksnius, kad būtų galima optimaliai parodyti svorį. Tai užtikrina, kad dvejetainiai parametrai glaudžiai atitiktų jų visiško tikslumo atitikmenis. Modelio mokymuose buvo naudojami 32 NVIDIA A100 GPU dideliems duomenų rinkiniams apdoroti, įskaitant 1,26 trilijonus žetonų iš tokių šaltinių kaip „RefinedWeb“ ir „StarCoder“.
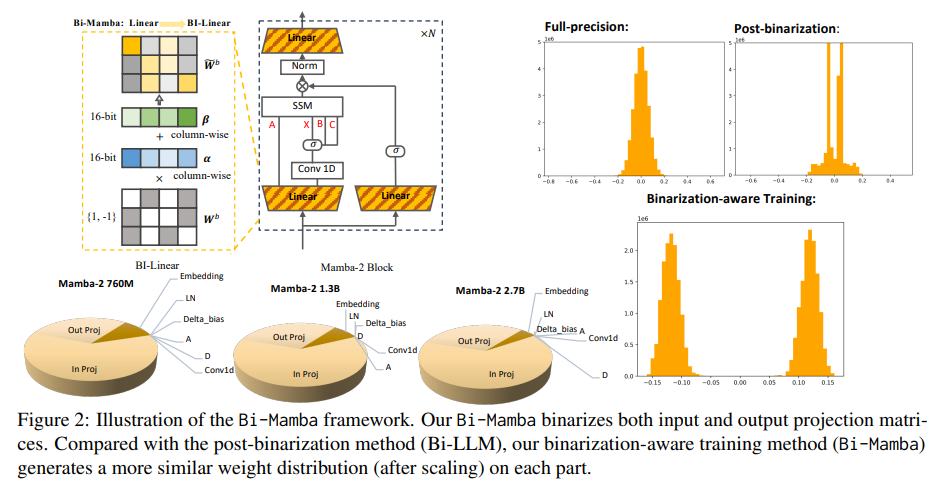
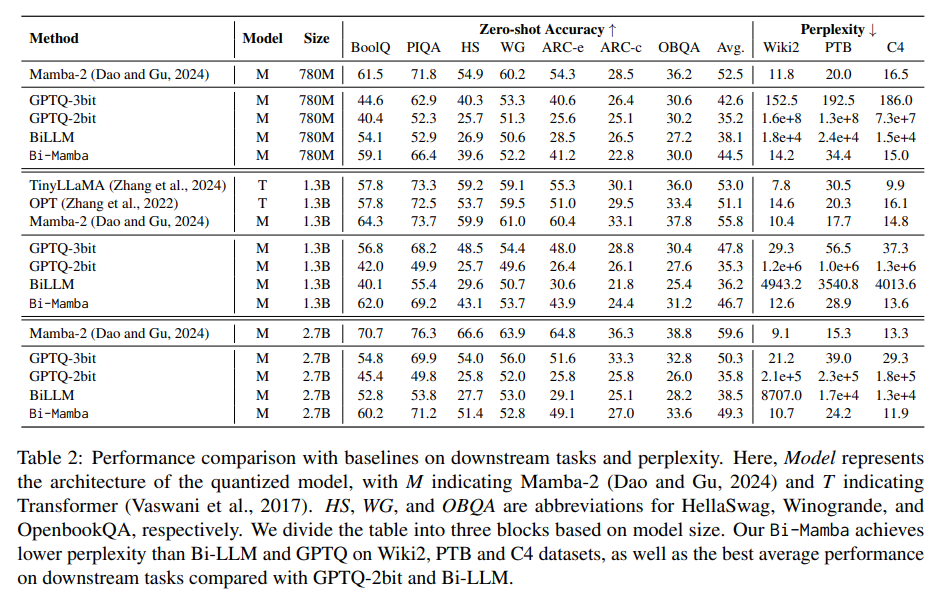
Išsamūs eksperimentai parodė Bi-Mamba konkurencinį pranašumą prieš esamus modelius. Duomenų rinkiniuose, tokiuose kaip Wiki2, PTB ir C4, „Bi-Mamba“ sumišimo balai buvo 14,2, 34,4 ir 15,0, žymiai pranokdami tokias alternatyvas kaip GPTQ ir Bi-LLM, kurių sumišimas buvo net 10 kartų didesnis. Be to, „Bi-Mamba“ pasiekė 44,5% 780M modelio, 49,3% 2,7B modelio ir 46,7% 1,3B varianto nulinio kadrų tikslumą atlikdama tokias užduotis kaip „BoolQ“ ir „HellaSwag“. Tai parodė savo patikimumą atliekant įvairias užduotis ir duomenų rinkinius, kartu išlaikant efektyvų energiją.
Tyrimo išvados pabrėžia keletą pagrindinių dalykų:
- Efektyvumo padidėjimas: Bi-Mamba pasiekia daugiau nei 80% saugyklos suspaudimo, palyginti su visiško tikslumo modeliais, sumažindama saugyklos dydį nuo 5,03 GB iki 0,55 GB 2,7 B modeliui.
- Našumo nuoseklumas: Modelis išlaiko panašų našumą kaip ir visiškai tikslūs modeliai su žymiai mažesniais atminties reikalavimais.
- Mastelio keitimas: „Bi-Mamba“ architektūra leidžia efektyviai treniruotis naudojant įvairius modelių dydžius, o net ir didžiausių variantų rezultatai yra konkurencingi.
- Binarizacijos tvirtumas: Selektyviai binarizuodamas linijinius modulius, Bi-Mamba išvengia našumo pablogėjimo, paprastai siejamo su naiviais dvejetainiais metodais.

Apibendrinant, „Bi-Mamba“ yra reikšmingas žingsnis į priekį sprendžiant dvigubus didelių kalbų modelių mastelio ir efektyvumo iššūkius. Pasitelkę dvejetainį mokymą ir sutelkdami dėmesį į pagrindinius architektūros optimizavimus, mokslininkai parodė, kad būsenos erdvės modeliai gali pasiekti aukštą našumą esant ekstremaliam kvantavimui. Ši naujovė padidina energijos vartojimo efektyvumą, sumažina išteklių sunaudojimą ir sudaro sąlygas būsimiems mažo bitų AI sistemų tobulinimams, atverdama galimybes diegti didelio masto modelius praktiškoje, ribotų išteklių aplinkoje. Tvirti Bi-Mamba rezultatai pabrėžia jos, kaip transformuojančio požiūrio į tvaresnes ir efektyvesnes AI technologijas, potencialą.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(NEMOKAMA AI VIRTUALI KONFERENCIJA) „SmallCon“: nemokama virtuali „GenAI“ konferencija „Meta“, „Mistral“, „Salesforce“, „Harvey AI“ ir kt.. Prisijunkite prie mūsų gruodžio 11 d. šiame nemokamajame virtualiame renginyje ir sužinokite, ko reikia norint sukurti didelius mažus modelius iš AI pirmtakų, tokių kaip Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face ir kt.
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
🐝🐝 Perskaitykite šią „Kili Technology“ AI tyrimo ataskaitą „Didelių kalbos modelio pažeidžiamumo įvertinimas: lyginamoji raudonųjų komandų sudarymo metodų analizė“




