

LLM įrodė išskirtines galimybes, tačiau jų esminiai skaičiavimo reikalavimai kelia didelių iššūkių didelio masto diegimui. Ankstesni tyrimai rodo, kad tarpinius sluoksnius giliuose nervų tinkluose galima pertvarkyti ar pašalinti, nedarant didelės įtakos našumui, šios įžvalgos nebuvo sistemingai panaudotos, kad būtų sumažintos išvadų išlaidos. Atsižvelgiant į greitą LLM, kuriame dažnai yra šimtai milijardų parametrų, išplėtimas, išvadų optimizavimas yra labai svarbus siekiant pagerinti efektyvumą, sumažinti delsą ir sumažinti veiklos išlaidas. Aukšto srauto programos, susijusios su debesų pagrindu pagamintais LLM išvadomis, gali patirti mėnesines išlaidas milijonams, todėl efektyviai pagrįsti sprendimai yra būtini. Be to, dėl galimybės diegti šiuos modelius su prietaisais suvaržytais prietaisais reikia strategijų, kurios išlaikytų našumą, tuo pačiu sumažinant skaičiavimo pridėtines išlaidas. Nepaisant architektūrinių modernių transformatorių ir gilių liekamųjų tinklų panašumų, kur sluoksnio gylis kartais gali būti nereikalingas, tyrimai dar turi ištirti šiuos atleidimus, kad būtų galima visiškai optimizuoti išvadų efektyvumą.
Yra keletas būdų, kaip pagerinti LLM skaičiavimo efektyvumą, įskaitant genėjimą, kiekybinį ir paralelizavimą. Genėjimas pašalina nereikalingus parametrus, kad būtų galima įvesti daugybę, gerinant atminties panaudojimą ir apdorojimo greitį. Kita vertus, kvantizavimas sumažina tikslumą, kai slankiojo kablelio skaičiavimai konvertuoja į mažesnio bitų sveikus formatus, tokius kaip INT8 ar INT4, padidindamas aparatinės įrangos efektyvumą ir taupant energiją. Be to, paralelizacijos metodai, tokie kaip „Tensor“ ir „Pipeline Parallelim“, paskirsto darbo krūvius keliuose apdorojimo įrenginiuose, kad paspartintų išvadas, tuo pačiu sprendžiant komunikacijos pridėtines išlaidas. Naujausios naujovės taip pat ištyrė architektūrines modifikacijas sluoksnio lygyje, įskaitant sluoksnių suliejimą ir dinaminį pasikartojantį vykdymą, siekiant supaprastinti skaičiavimo grafikus. Tačiau tyrimai dar turi sutelkti dėmesį į iš eilės suliejimą iš eilės per tensorių paralelizmą, pateikiant atvirą prospektą, kad būtų galima dar labiau optimizuoti išvadą.
Ženevos universiteto, EPFL ir „Meta Fair“ tyrėjai siūlo metodą, kaip sumažinti iš anksto išmokytų LLM gylį, tuo pačiu išsaugodami rezultatus. Modifikavus skaičiavimo grafiką, galima lygiagrečiai atlikti sugrupuotų sluoksnių porų vykdymą, padidindamas išvadų greitį maždaug 1,20 × nereikalaujant perkvalifikavimo. Jų požiūris išlaiko 95–99% tikslumą tarpusavio ir konteksto mokymosi (ICL) etalonuose. Be to, derinimas padeda atkurti nedidelius našumo nuostolius. Šis metodas žymiai padidina didelio masto LLM diegimo efektyvumą, parodydamas, kad struktūrinės transformacijos, tokios kaip sluoksnių sujungimas ir pertvarkymas, gali optimizuoti skaičiavimo darbo krūvį, išlaikant modelio efektyvumą.
Tyrime nagrinėjamas efektyvus LLM gylis, pritaikant transformacijas, tokias kaip maišymas, sujungimas ir genėjimo sluoksniai. Rezultatai rodo silpną tarpinių sluoksnių priklausomybes, leidžiančias tam tikrus sluoksnius pertvarkyti ar lygiagreti su minimaliu pasipiktinimo praradimu. Vykdydami gretimus sluoksnius lygiagrečiai, sumažėja gylis, išlaikant našumą, pabrėždamas sluoksnio nepriklausomybę. Be to, sluoksnio paralelizmas paskirsto skaičiavimus visame GPU, optimizuodamas efektyvumą per tensorių paralelizmą. Dėmesio modifikacijos ir tiekimo į priekį tinklai užtikrina veiksmingą lygiagrečią vykdymą. Sluoksnio normalizavimo koregavimas padeda išlaikyti stabilumą. Šie duomenys rodo, kad transformatorių modeliai gali panaudoti paralelizmą, kad padidintų skaičiavimo efektyvumą, nereikalaujant esminių architektūrinių modifikacijų.
Tyrime įvertinamas sluoksnio paralelizmas, susijęs su išvadų greičiu, ICL tikslumu ir tobulinimo derinimu, norint atkurti našumą. Eksperimentuose naudojami llama2 7b ir llama3.2 3b ant dvigubo A100 GPU. Sluoksnio paralelizmas taikomas sujungtoms sluoksniams, o tenzoriaus paralelizmas kitur. Rezultatai rodo, kad daugiau nei 14 LLAMA2 7B ir 10 sluoksnių, skirtų llama3.2 3b, ICL tikslumas mažėja. Greitis pagerėja proporcingai, pasiekiant 1,38x padidėjimą agresyvaus paralelizmo metu. Patobulinant lygiagretus „RedPajama“ duomenų sluoksnius žymiai atkuriamas tikslumas, pagerindamas MMLU nuo 83,6% iki 94,4%, išlaikant greičio padidėjimą, parodant sluoksnio lygiagretumo gyvybingumą su tiksliniais koregavimais.
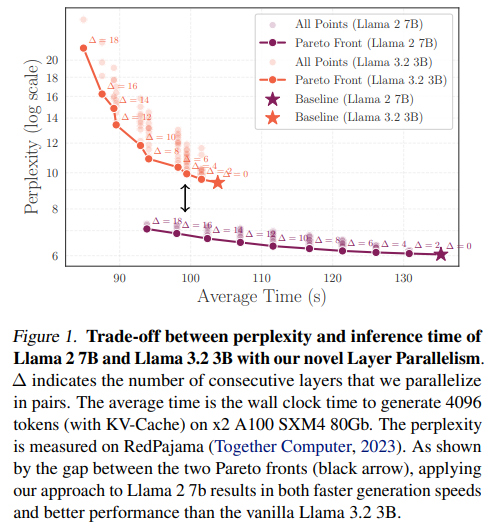
Apibendrinant galima pasakyti, kad tyrimas pristato sluoksnio paralelizmą (LP), kuris pertvarko transformatoriaus skaičiavimą vykdant sluoksnių poras lygiagrečiai, pagerindamas išvadų greitį be perkvalifikavimo. Taikoma LLAMA2 7B ir LLAMA3.2 3B, LP sumažino modelio gylį 21% ir 18%, atitinkamai padidindamas 1,29x ir 1,22x greitį. Patobulinimas atgavo 10,8% prarasto tikslumo, įrodydamas jo efektyvumą. Šios išvados ginčija nuostatą, kad transformatoriaus sluoksniai turi apdoroti nuosekliai, o tai rodo, kad selektyvi paralelizacija yra perspektyvi. LP padidina LLM efektyvumą gamyboje, būsimame darbe tiria optimalų sluoksnių grupavimą, sąveiką su kvantalizacija ir gilesnės teorinės įžvalgos apie sluoksnio nepriklausomybę ir skaičiavimo efektyvumą.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
„MarktechPost“ ir „IIT Madras“ dvigubo laipsnio studentė konsultacinė Sana Hassan aistringai taiko technologijas ir AI, kad galėtų spręsti realaus pasaulio iššūkius. Turėdamas didelį susidomėjimą išspręsti praktines problemas, jis pateikia naują perspektyvą AI ir realaus gyvenimo sprendimų sankryžai.
✅ (rekomenduojama) Prisijunkite prie mūsų „Telegram“ kanalo





