

Dirbtinis intelektas (AI) daro didelę pažangą natūralios kalbos apdorojimo (NLP) srityje, sutelkdamas dėmesį į modelių, galinčių tiksliai interpretuoti ir generuoti žmogaus kalbą, tobulinimą. Tyrėjai stengiasi sukurti modelius, kurie suvoktų sudėtingas kalbines struktūras ir generuotų nuoseklius, kontekstui svarbius atsakymus per išplėstinius dialogus. Pažanga šioje srityje yra gyvybiškai svarbi programoms, tokioms kaip automatizuotas klientų aptarnavimas, turinio kūrimas ir mašininis vertimas, kur kalbos tikslumas ir nuoseklumas yra labai svarbūs. Augant AI galimybių poreikiui šiose programose, vis svarbiau tobulinti modelių gebėjimą tvarkyti niuansuotą kalbą ir išlaikyti kontekstą.
Pagrindinė problema, su kuria susiduria NLP, yra ilgų tekstų nuoseklumo palaikymas. Kalbos modeliai linkę prarasti ilgalaikes priklausomybes tekste, todėl atsakymuose atsiranda nenuoseklumų ir konteksto trūkumo. Šis apribojimas yra ypač problemiškas programose, kurioms reikalingas išplėstinis interaktyvus dialogas, nes atsakymus gali tekti suderinti su ankstesniu kontekstu. Šios problemos sprendimas yra labai svarbus siekiant tobulinti AI programas, kurios priklauso nuo natūralios kalbos supratimo ir generavimo, kad jos veiktų efektyviai ir patikimai.
Dabartiniai kalbų modeliai, daugiausia pagrįsti transformatorių architektūromis, tokiomis kaip GPT ir BERT, padarė didelę pažangą, tačiau dažnai juos riboja dideli skaičiavimo reikalavimai ir ribota galimybė išlaikyti kontekstą per išplėstinį tekstą. Šie transformatoriai apdoroja tekstą tokiu būdu, kuriam reikia daug atminties ir apdorojimo galios, todėl jų taikymas yra nepraktiškas nustatymuose su ribotais skaičiavimo ištekliais. Be to, transformatorių modeliams kartais reikia pagalbos dėl ilgo teksto nuoseklumo, o tai riboja jų efektyvumą atliekant sudėtingas kalbos užduotis. Todėl mokslininkai tiria būdus, kaip suderinti našumą su skaičiavimo efektyvumu.
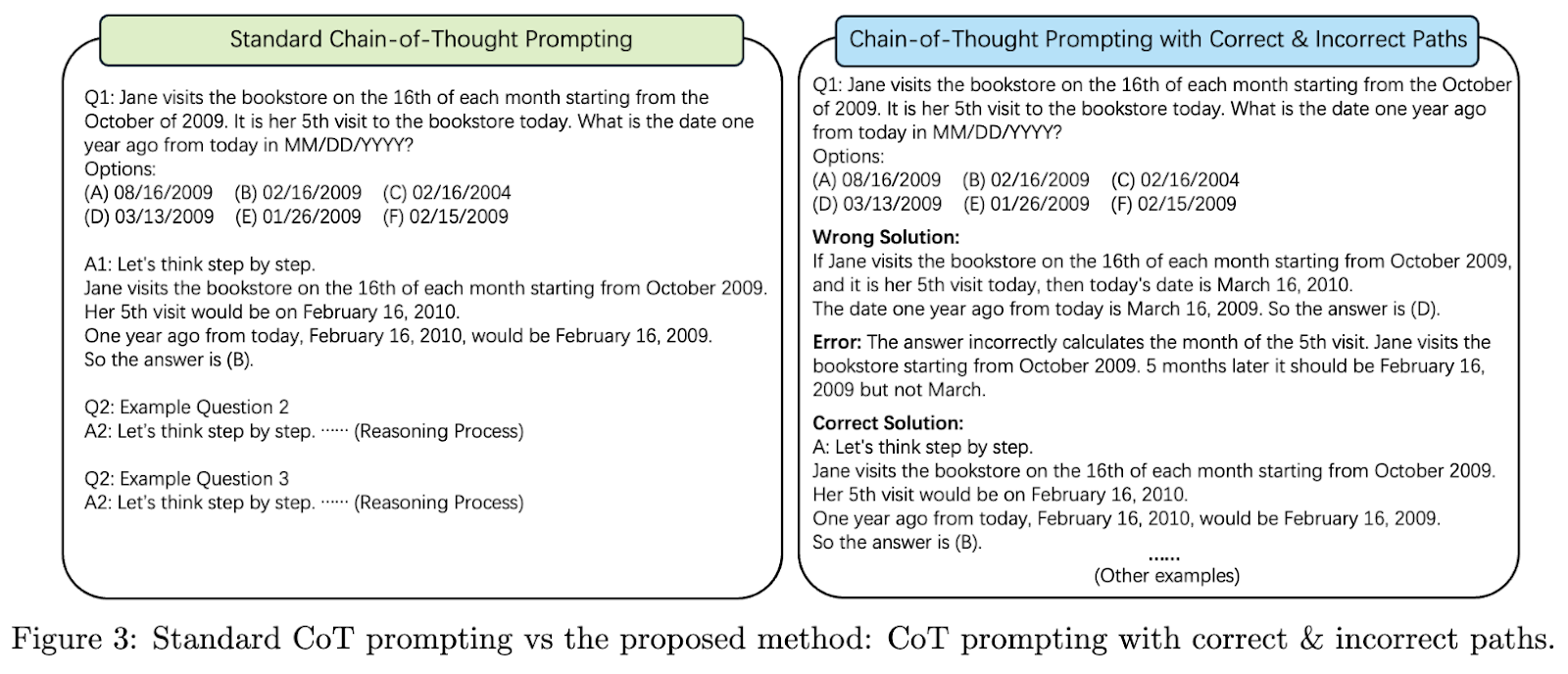
Tyrėjai iš Amazon ir Mičigano valstijos universiteto pristatė naują modelį, skirtą šiems iššūkiams spręsti, tobulinant transformatoriaus architektūrą. Šiuo modeliu siekiama sumažinti skaičiavimo apkrovą išsaugant nuoseklumą ilguose teksto segmentuose, naudojant naują segmentavimo metodą, kad būtų išlaikytas kontekstui svarbių atsakymų tikslumas. Įdiegęs klaidų suvokimo samprotavimą segmentuojant tekstą į mažesnius vienetus, modelis gali apdoroti didelius fragmentus nepažeidžiant nuoseklumo, o tai yra didelė pažanga NLP srityje. Šis segmentavimas taip pat leidžia keisti modulinius koregavimus, todėl modelis yra universalus atliekant kalbos užduotis, įskaitant atsakymus į klausimus ir pokalbio AI.
Šiame modelyje yra klaidų suvokimo demonstravimo mechanizmas, leidžiantis koreguoti prognozes pagal aptiktus netikslumus atliekant tarpinius samprotavimo veiksmus. Užuot apdorojęs tekstą viename dideliame vienete, šis modelis suskirsto įvestis į mažesnius segmentus, kuriuose palaikomos kontekstinės nuorodos, kad būtų galima nuosekliai apdoroti ilgas dalis. Modulinis dizainas taip pat leidžia mokslininkams pritaikyti konkrečius modelio parametrus, kad jie atitiktų skirtingų programų poreikius, nereikalaujant visiškai pertvarkyti sistemos. Dėl šio mastelio modelis yra lankstus ir efektyvus sprendimas įvairioms NLP programoms.
Eksperimentuose šis modelis parodė ryškius patobulinimus įvairiuose etalonuose. Pavyzdžiui, duomenų rinkinyje „Sumaišytų objektų stebėjimas“ modelio tikslumas padidėjo nuo 56,53% iki 61,20%, o duomenų rinkinyje „Pingvinai lentelėje“ našumas pagerėjo nuo 81,34% iki 82,19%. Šie rezultatai pabrėžia patobulintą modelio gebėjimą valdyti sudėtingas samprotavimo užduotis. Modelis taip pat parodė reikšmingą našumo padidėjimą pagal konkrečius etalonus; Kai kuriais atvejais tikslumas pagerėjo daugiau nei 2%, o tai įrodo, kad jis gali nuolat pranokti standartinius transformatorius, tiksliai valdydamas tarpinius samprotavimo veiksmus.
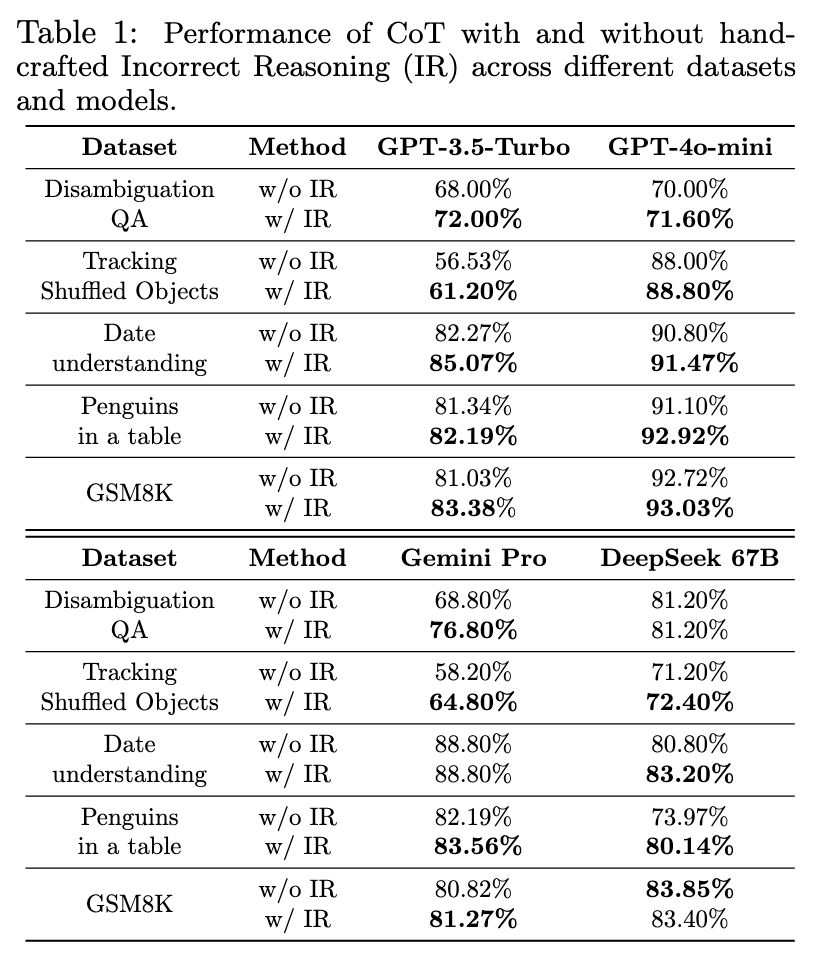
Tyrimas taip pat pabrėžia, kaip modelis sumažina skaičiavimo išlaidas, išlaikant nuoseklumą. Pavyzdžiui, tikslumas pagerėjo maždaug 2 % pagal konkrečius scenarijus, kai kelių etapų užduotims pritaikomas klaidų suvokimas. Tyrimas parodė, kad įtraukus teisingus ir neteisingus samprotavimo būdus, modelis padidino gebėjimą aptikti ir ištaisyti samprotavimo klaidas, o tai ypač naudinga sudėtinguose dialoguose ar išplėstiniuose samprotavimo scenarijuose. Šios išvados rodo, kad dėl tvirtos modelio architektūros jis gali tapti idealiu pasirinkimu programoms, kurioms reikalingas nuolatinis ir tikslus kalbos supratimas per ilgalaikę sąveiką.
Apskritai, šis „Amazon“ ir Mičigano valstijos universiteto atliktas tyrimas rodo reikšmingą NLP pažangą, nes sprendžiami kritiniai iššūkiai palaikant nuoseklumą ir mažinant skaičiavimo įtampą. Siūlomas modelis suderina tikslumą ir efektyvumą, žadėdamas didelę naudą įvairioms kalbų programoms. Modulinė ir pritaikoma struktūra leidžia jį atlikti kaip universalų įrankį realaus pasaulio AI užduotims, kurioms reikalingas tikslus, kontekstą suvokiantis kalbos apdorojimas įvairiose srityse.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Būsimas tiesioginis internetinis seminaras – 2024 m. spalio 29 d.) Geriausia platforma, skirta tiksliai suderintiems modeliams aptarnauti: „Predibase Inference Engine“ (reklamuojama)
Nikhilas yra „Marktechpost“ konsultantas. Indijos technologijos institute Charagpūre jis siekia integruoto dvigubo medžiagų studijų laipsnio. Nikhilas yra AI / ML entuziastas, kuris visada tiria pritaikymą tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagų mokslo išsilavinimą, jis tyrinėja naujus pasiekimus ir kuria galimybes prisidėti.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️




