

Grafinės vartotojo sąsajos (GUI) atlieka esminį žmogaus ir kompiuterio sąveikos vaidmenį, suteikdamos terpę, per kurią vartotojai atlieka užduotis žiniatinklyje, darbalaukyje ir mobiliosiose platformose. Automatizavimas šioje srityje yra transformuojantis, potencialiai drastiškai pagerinantis našumą ir įgalinantis sklandų užduočių vykdymą nereikalaujant rankinio įsikišimo. Savarankiški agentai, galintys suprasti GUI ir su jomis sąveikauti, gali pakeisti darbo eigą, ypač pasikartojančių ar sudėtingų užduočių nustatymuose. Tačiau GUI būdingas sudėtingumas ir kintamumas įvairiose platformose kelia didelių iššūkių. Kiekviena platforma naudoja skirtingus vizualinius išdėstymus, veiksmų erdves ir sąveikos logiką, todėl sunku kurti keičiamo dydžio ir patikimus sprendimus. Šios srities tyrėjams tebėra nuolatinis iššūkis sukurti sistemas, kurios galėtų savarankiškai naršyti šioje aplinkoje, kartu apibendrinant platformas.
Šiuo metu GUI automatizavimo srityje yra daug techninių kliūčių; vienas yra natūralios kalbos instrukcijų derinimas su įvairiais vaizdiniais GUI vaizdais. Tradiciniai metodai dažnai remiasi tekstiniais vaizdais, tokiais kaip HTML arba pritaikymo neįgaliesiems medžiai, modeliuojant GUI elementus. Šie metodai yra riboti, nes GUI iš esmės yra vizualios, o tekstinės abstrakcijos nesugeba užfiksuoti vizualinio dizaino niuansų. Be to, skirtingose platformose tekstiniai vaizdai skiriasi, todėl duomenys yra suskaidyti ir veikimas nenuoseklus. Dėl šio vaizdinio GUI pobūdžio ir automatizavimo sistemose naudojamų tekstinių įvesties neatitikimų sumažėja mastelio keitimas, ilgesnis išvadų laikas ir ribotas apibendrinimas. Be to, dauguma dabartinių metodų nesugeba veiksmingo daugiarūšio samprotavimo ir įžeminimo, kurie yra būtini norint suprasti sudėtingą vaizdinę aplinką.
Esami įrankiai ir metodai bandė spręsti šiuos iššūkius įvairiais būdais. Daugelis sistemų priklauso nuo uždarojo kodo modelių, kad pagerintų samprotavimo ir planavimo galimybes. Šie modeliai dažnai naudoja bendravimą natūralia kalba, kad derintų pagrindimo ir samprotavimo procesus, tačiau šis metodas praranda informaciją ir trūksta mastelio. Kitas dažnas apribojimas yra suskaidytas mokymo duomenų rinkinių pobūdis, kuris nesuteikia visapusiškos paramos pagrindimo ir argumentavimo užduotims. Pavyzdžiui, duomenų rinkiniai paprastai pabrėžia pagrindimą arba samprotavimą, bet ne abu, todėl sukuriami modeliai, kurie vienoje srityje yra puikūs, o kitose sunku. Šis padalijimas trukdo kurti vieningus autonominės GUI sąveikos sprendimus.
Honkongo universiteto mokslininkai ir „Salesforce Research“ pristatė AGUVIS (7B ir 72B), vieninga sistema, sukurta siekiant įveikti šiuos apribojimus, naudojant grynai regėjimu pagrįstus stebėjimus. AGUVIS pašalina priklausomybę nuo tekstinių vaizdų ir vietoj to sutelkia dėmesį į vaizdu pagrįstą įvestį, suderindama modelio struktūrą su vaizdiniu GUI pobūdžiu. Sistema apima nuoseklią veiksmų erdvę įvairiose platformose, palengvinančią kelių platformų apibendrinimą. AGUVIS integruoja aiškų planavimą ir daugiarūšį samprotavimą, kad naršytų sudėtingoje skaitmeninėje aplinkoje. Tyrėjai sukūrė didelio masto GUI agentų trajektorijų duomenų rinkinį, kuris buvo naudojamas AGUVIS mokyti dviejų etapų procese. Sistemos modulinė architektūra, apimanti prijungiamą veiksmų sistemą, leidžia sklandžiai prisitaikyti prie naujos aplinkos ir užduočių.
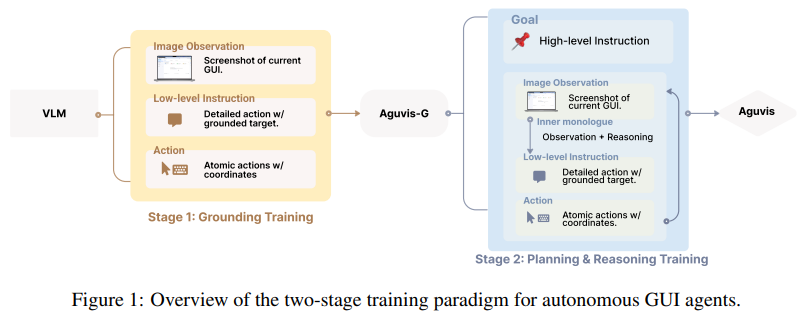
AGUVIS sistemoje naudojama dviejų pakopų mokymo paradigma aprūpinti modelį įžeminimo ir samprotavimo galimybėmis:
- Pirmajame etape modelis sutelkia dėmesį į įžeminimą ir natūralios kalbos instrukcijų susiejimą su vaizdiniais elementais GUI aplinkoje. Šiame etape naudojama įžeminimo pakavimo strategija, sujungiant kelias instrukcijų ir veiksmų poras į vieną GUI ekrano kopiją. Šis metodas pagerina treniruočių efektyvumą, padidindamas kiekvieno vaizdo naudingumą neprarandant tikslumo.
- Antrasis etapas supažindina su planavimu ir argumentavimu, modelio mokymu, kad būtų galima atlikti kelių etapų užduotis įvairiose platformose ir scenarijuose. Šis etapas apima išsamius vidinius monologus, apimančius stebėjimo aprašymus, mintis ir žemo lygio veiksmų nurodymus. Palaipsniui didindamas mokymo duomenų sudėtingumą, modelis išmoksta tiksliai ir lengvai atlikti niuansuotas užduotis.
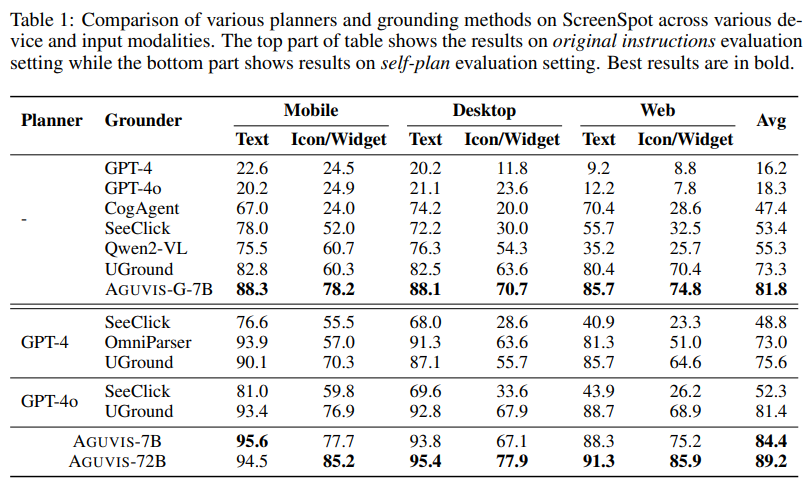
AGUVIS parodė puikius rezultatus tiek neprisijungus, tiek realiame internetiniame vertinime. Naudojant GUI įžeminimą, modelis pasiekė vidutinį 89,2 tikslumą, viršijantį moderniausius mobiliųjų, stalinių ir žiniatinklio platformų metodus. Pagal internetinius scenarijus AGUVIS pranoko konkuruojančius modelius ir 51,9 % pagerino žingsnių sėkmės rodiklį atliekant planavimo neprisijungus užduotis. Be to, modelis sumažino išvadų sąnaudas 93%, palyginti su GPT-4o. Sutelkdama dėmesį į vizualinius stebėjimus ir integruodama vieningą veiksmų erdvę, AGUVIS nustato naują GUI automatizavimo etaloną, todėl jis yra pirmasis visiškai autonomiškas grynai vizija pagrįstas agentas, galintis atlikti realaus pasaulio užduotis nepasikliaujant uždarojo kodo modeliais.
Pagrindinės AGUVIS tyrimų GUI automatizavimo srityje išvados:
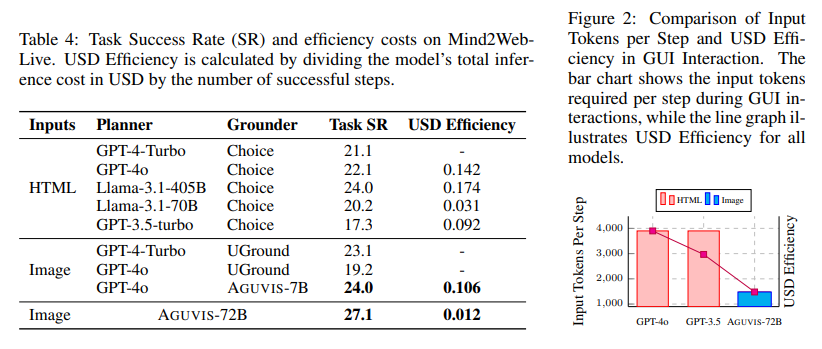
- AGUVIS naudoja vaizdu pagrįstą įvestį, žymiai sumažindama žetonų sąnaudas ir suderindama modelį su vaizdiniu GUI pobūdžiu. Taikant šį metodą, 720p vaizdo stebėjimų simbolinė kaina yra tik 1 200, palyginti su 6 000 prieinamumo medžių ir 4 000 HTML stebėjimų.
- Modelis sujungia įžeminimo ir planavimo etapus, leidžiančius efektyviai atlikti vieno ir kelių žingsnių užduotis. Vien tik įžeminimo mokymas suteikia modeliui galimybę apdoroti kelias instrukcijas viename vaizde, o samprotavimo etapas pagerina jo gebėjimą vykdyti sudėtingas darbo eigas.
- AGUVIS kolekcija sujungia ir papildo esamus duomenų rinkinius sintetiniais duomenimis, kad palaikytų daugiarūšį samprotavimą ir įžeminimą. Taip gaunamas įvairus ir keičiamo dydžio duomenų rinkinys, leidžiantis treniruoti tvirtus ir pritaikomus modelius.
- Naudojant pyautogui komandas ir prijungiamą veiksmų sistemą, modelis gali apibendrinti įvairiose platformose, tuo pačiu prisitaikant prie konkrečios platformos veiksmų, tokių kaip perbraukimas mobiliuosiuose įrenginiuose.
- AGUVIS pasiekė puikių GUI įžeminimo etalonų rezultatų: 88,3% tikslumo rodikliai žiniatinklio platformose, 85,7% mobiliuosiuose ir 81,8% staliniuose kompiuteriuose. Be to, jis parodė puikų efektyvumą ir sumažino USD išvadų sąnaudas 93%, palyginti su esamais modeliais.
Apibendrinant, AGUVIS sistema sprendžia esminius GUI automatizavimo įžeminimo, argumentavimo ir apibendrinimo iššūkius. Jo grynai vizija pagrįstas požiūris pašalina neefektyvumą, susijusį su tekstiniu vaizdavimu, o vieninga veiksmų erdvė leidžia sklandžiai sąveikauti įvairiose platformose. Tyrimas suteikia patikimą savarankiškų GUI užduočių sprendimą, naudojant programas nuo produktyvumo įrankių iki pažangių AI sistemų.
Patikrinkite į Popierius, „GitHub“ puslapisir Projektas. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)






