

Ilgo konteksto LLM įgalina pažangias programas, tokias kaip saugyklos lygio kodo analizė, ilgo dokumento klausimų atsakymas ir daugelio kadrų kontekstinis mokymasis, palaikydami išplėstinius konteksto langus nuo 128 000 iki 10 M žetonų. Tačiau šios galimybės yra susijusios su skaičiavimo efektyvumu ir atminties naudojimo iššūkiais darant išvadas. Siekiant išspręsti šias problemas, atsirado optimizacijų, naudojančių raktinės vertės (KV) talpyklą, daugiausia dėmesio skiriant talpyklos pakartotinio panaudojimo bendriems kontekstams kelių posūkių sąveikose gerinimui. Tokiomis technikomis kaip PagedAttention, RadixAttention ir CacheBlend siekiama sumažinti atminties sąnaudas ir optimizuoti talpyklos panaudojimą, tačiau jos dažnai vertinamos tik vieno posūkio scenarijuose, neatsižvelgiant į realaus pasaulio kelių pasukimų programas.
Pastangos pagerinti ilgalaikio konteksto išvadas sutelktos į skaičiavimo ir atminties kliūčių mažinimą išankstinio užpildymo ir dekodavimo etapuose. Išankstinio užpildymo optimizavimas, pvz., mažas dėmesys, linijinis dėmesys ir greitas suspaudimas, sumažina didelių konteksto langų tvarkymo sudėtingumą. Dekodavimo strategijomis, įskaitant statinį ir dinaminį KV glaudinimą, talpyklos iškrovimą ir spekuliacinį dekodavimą, siekiama efektyviai valdyti atminties apribojimus. Nors šie metodai padidina efektyvumą, daugelis remiasi nuostolingais glaudinimo būdais, kurie gali pakenkti našumui kelių pasukimų nustatymuose, kur būtina išsaugoti priešdėlį talpykloje. Esamuose pokalbio etalonuose pirmenybė teikiama vieno posūkio vertinimams, paliekant spragą vertinant bendrų kontekstų sprendimus realaus pasaulio scenarijuose.
„Microsoft“ ir Surėjaus universiteto mokslininkai pristatė „SCBench“ – etaloną, skirtą ilgalaikio konteksto metodams LLM įvertinti naudojant KV talpyklą orientuotą metodą. „SCBench“ įvertina keturis KV talpyklos etapus: generavimą, glaudinimą, gavimą ir įkėlimą per 12 užduočių ir du bendrus konteksto režimus (kelių posūkių ir kelių užklausų). Lyginamoji analizė analizuoja tokius metodus kaip mažas dėmesys, suspaudimas ir atkūrimas tokiuose modeliuose kaip Llama-3 ir GLM-4. Rezultatai rodo, kad sub-O (n) atminties metodai sunkiai veikia kelių posūkių scenarijuose, o O (n) atminties metodai veikia tvirtai. „SCBench“ suteikia įžvalgų apie retumo efektus, užduočių sudėtingumą ir iššūkius, pvz., platinimo pokyčius ilgos kartos scenarijuose.
Į KV talpyklą orientuota sistema suskirsto ilgo konteksto metodus LLM į keturis etapus: generavimą, glaudinimą, gavimą ir įkėlimą. Sukūrimas apima tokius metodus kaip mažas dėmesys ir greitas glaudinimas, o glaudinimas apima tokius metodus kaip KV talpyklos pašalinimas ir kvantavimas. Gaunant daugiausia dėmesio skiriama atitinkamų KV talpyklos blokų gavimui, siekiant optimizuoti našumą, o įkėlimas apima dinamišką KV duomenų perdavimą skaičiavimams. SCBench etalonas įvertina šiuos metodus atliekant 12 užduočių, įskaitant eilučių ir semantinį atkūrimą, kelių užduočių atlikimą ir visuotinį apdorojimą. Ji analizuoja našumo metriką, pvz., tikslumą ir efektyvumą, kartu pateikdama įžvalgų apie algoritmų naujoves, įskaitant „Tri-shape“ nedidelį dėmesį, o tai pagerina kelių užklausų scenarijus.
Tyrėjai įvertino šešis atvirojo kodo ilgo konteksto LLM, įskaitant Llama-3.1, Qwen2.5, GLM-4, Codestal-Mamba ir Jamba, atstovaujančius įvairioms architektūroms, tokioms kaip Transformer, SSM ir SSM-Attention hibridai. Eksperimentuose buvo naudojamas BFloat16 tikslumas NVIDIA A100 GPU su tokiomis sistemomis kaip HuggingFace, vLLM ir FlashAttention-2. Buvo išbandyti aštuoni ilgo konteksto sprendimai, įskaitant nedidelį dėmesį, KV talpyklos valdymą ir greitą glaudinimą. Rezultatai parodė, kad „MInference“ pranoko paieškos užduotis, o „A“ ir „Tri“ formos – atliekant kelių eilių užduotis. KV glaudinimo metodai ir greitas glaudinimas davė įvairių rezultatų, dažnai prasčiau atlikdami paieškos užduotis. SSM dėmesio hibridai sunkiai sąveikauja su keliais posūkiais, o linijiniai modeliai iš viso rodė prastą našumą.
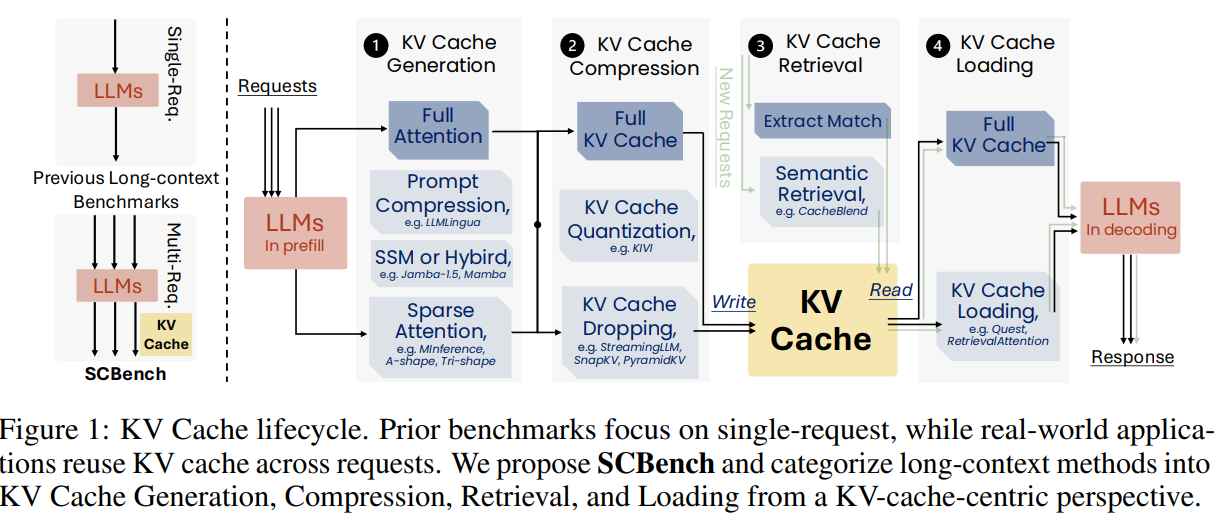
Apibendrinant galima teigti, kad tyrime pabrėžiama kritinė spraga vertinant ilgo konteksto metodus, kurie tradiciškai orientuoti į vieno posūkio sąveiką, nepaisant kelių posūkių, bendro konteksto scenarijų, vyraujančių realaus pasaulio LLM programose. SCBench etalonas pristatomas siekiant išspręsti šią problemą, įvertinant ilgo konteksto metodus iš KV talpyklos gyvavimo ciklo perspektyvos: generavimas, glaudinimas, gavimas ir įkėlimas. Jį sudaro 12 užduočių dviem bendrai naudojamo konteksto režimais ir keturios pagrindinės galimybės: eilučių paieška, semantinė paieška, visuotinis informacijos apdorojimas ir kelių užduočių atlikimas. Įvertinus aštuonis ilgo konteksto metodus ir šešis pažangiausius LLM, paaiškėja, kad sub-O(n) metodai sunkiai veikia kelių pasukimų nustatymuose. Priešingai, O (n) požiūris į „Excel“ suteikia vertingų įžvalgų, kaip pagerinti ilgo konteksto LLM ir architektūras.
Patikrinkite į Popierius ir Duomenų rinkinys. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)



