

Medprompt, vykdymo laiko valdymo strategija, parodo, kad bendros paskirties LLM gali padėti pasiekti naujausių rezultatų specializuotose srityse, pvz., medicinoje. Naudodama struktūrizuotus, daugiapakopius raginimo metodus, tokius kaip minties grandinės (CoT) samprotavimas, kuruoti kelių kadrų pavyzdžiai ir pasirinkimų maišymas, „Medprompt“ sumažina atotrūkį tarp bendrųjų ir specifinių sričių modelių. Šis metodas žymiai pagerina medicininių etalonų, pvz., MedQA, našumą ir beveik 50 % sumažina klaidų lygį be modelio koregavimo. „OpenAI“ o1 peržiūros modelis dar labiau parodo pažangą LLM projektavimo srityje, įtraukdamas vykdymo laiko samprotavimus, kad dinamiškai patikslintų rezultatus, peržengiant tradicines CoT strategijas sudėtingoms užduotims spręsti.
Istoriškai tam tikros srities išankstinis mokymas buvo būtinas norint pasiekti aukštą našumą specializuotose srityse, kaip matyti iš tokių modelių kaip PubMedBERT ir BioGPT. Tačiau didelių apibendrintų modelių, tokių kaip GPT-4, atsiradimas pakeitė šią paradigmą, nes tokie modeliai pralenkė konkrečiam domenui būdingus analogus atliekant tokias užduotis kaip USMLE. Tokios strategijos kaip „Medprompt“ pagerina bendrojo modelio veikimą integruodamos dinaminius raginimo metodus, leidžiančius tokiems modeliams kaip GPT-4 pasiekti geresnių medicinos etalonų rezultatų. Nepaisant tobulų medicinos modelių, pvz., Med-PaLM ir Med-Gemini, pažangos, bendrieji metodai su patobulintomis išvados laiko strategijomis, pavyzdžiui, Medprompt ir o1-preview, siūlo keičiamo dydžio ir veiksmingus sprendimus didelės apimties domenams.
„Microsoft“ ir „OpenAI“ mokslininkai įvertino o1 peržiūros modelį, atspindintį AI dizaino pokytį, įtraukiant CoT samprotavimus treniruočių metu. Šis „samprotavimo“ metodas leidžia žingsnis po žingsnio spręsti problemas darant išvadas, sumažinant priklausomybę nuo greitų inžinerinių metodų, tokių kaip „Medprompt“. Jų tyrimas parodė, kad o1-preview viršijo GPT-4, net ir naudojant Medprompt, pagal medicininius etalonus, o kelių kartų raginimai trukdė jos veikimui, o tai rodo, kad mokymasis kontekste tokiems modeliams yra mažiau efektyvus. Nors daug išteklių reikalaujančios strategijos, pvz., derinimas, išlieka perspektyvios, o1-preview pasiekia naujausių rezultatų už didesnę kainą. Šios išvados pabrėžia naujų etalonų poreikį, kad būtų galima iššūkį samprotavimo vietiniams modeliams ir patobulinti išvados laiko optimizavimą.
Medprompt yra sistema, skirta optimizuoti bendrosios paskirties modelius, pvz., GPT-4, specializuotose srityse, pvz., medicinoje, derinant dinaminius kelių kadrų raginimus, CoT samprotavimus ir derinimą. Ji dinamiškai atrenka atitinkamus pavyzdžius, naudoja CoT nuosekliam samprotavimui ir padidina tikslumą daugumos balsų deriniu sujungiant kelis modelius. Metareasoning strategijos vadovauja skaičiavimo išteklių paskirstymui darant išvadas, o išorinių išteklių integravimas, pvz., Retrieval-Augmented Generation (RAG), užtikrina realiojo laiko prieigą prie svarbios informacijos. Pažangūs raginimo metodai ir pasikartojančios samprotavimo sistemos, tokios kaip savamokslis svarstytojas (STAR), toliau tobulina modelio išvestis, pabrėžiant išvados laiko mastelį, palyginti su išankstiniu mokymu. Kelių agentų orkestravimas siūlo bendradarbiavimo sprendimus sudėtingoms užduotims atlikti.
Tyrime vertinamas o1 peržiūros modelis pagal medicininius etalonus, lyginant jo našumą su GPT-4 modeliais, įskaitant Medprompt patobulintas strategijas. Tikslumas, pagrindinė metrika, vertinamas naudojant tokius duomenų rinkinius kaip MedQA, MedMCQA, MMLU, NCLEX ir JMLE-2024, taip pat USMLE paruošiamąją medžiagą. Rezultatai rodo, kad „o1-preview“ dažnai pranoksta GPT-4, puikiai tinka atliekant daug samprotavimus reikalaujančias užduotis ir daugiakalbius atvejus, pvz., JMLE-2024. Raginimo strategijos, ypač derinimas, pagerina našumą, nors kelių kartų raginimas gali tam trukdyti. Naudojant o1 peržiūrą pasiekiamas didelis tikslumas, bet patiriamos didesnės sąnaudos, palyginti su GPT-4o, kuri siūlo geresnį sąnaudų ir našumo balansą. Tyrime pabrėžiami kompromisai tarp tikslumo, kainos ir skatinančių metodų optimizuojant didelius medicinos kalbos modelius.
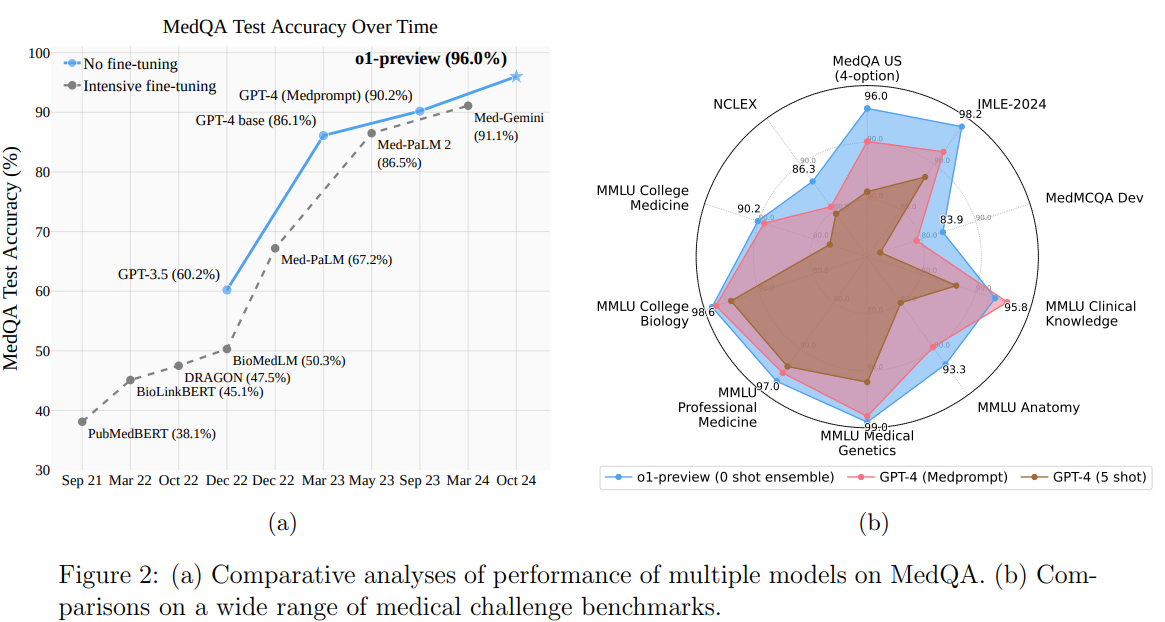
Apibendrinant galima pasakyti, kad „OpenAI“ o1 peržiūros modelis žymiai pagerina LLM našumą, pasiekdamas puikų medicinos etalonų tikslumą, nereikalaujant sudėtingų raginimo strategijų. Skirtingai nuo GPT-4 su Medprompt, o1 peržiūra sumažina pasitikėjimą tokiais metodais kaip kelių kadrų raginimas, kuris kartais neigiamai veikia našumą. Nors komplektavimas išlieka efektyvus, tam reikia kruopštaus sąnaudų ir efektyvumo kompromisų. Modelis nustato naują Pareto ribą, siūlydamas aukštesnės kokybės rezultatus, o GPT-4o yra ekonomiškesnė alternatyva tam tikroms užduotims atlikti. Kadangi o1 peržiūra artėja prie esamų etalonų prisotinimo, skubiai reikia atlikti sudėtingesnius vertinimus, kad būtų galima toliau tirti jos galimybes, ypač naudojant realaus pasaulio programas.
Patikrinkite Detalės ir popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 (Privalai dalyvauti internetiniame seminare): „Paverskite koncepcijos įrodymus į gamybai paruoštas AI programas ir agentus“ (Paaukštintas)
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🚨🚨NEMOKAMAS AI INTERNETINĖS SEMINARAS: „Fast Track your LLM Apps with deepset & Haystack“ (reklamuojama)





