

Tradiciniai požiūriai į kalbų modelių mokymą labai priklauso nuo prižiūrimo tobulinimo, kai modeliai mokosi imituodami teisingus atsakymus. Nors šis metodas yra veiksmingas atliekant pagrindines užduotis, jis riboja modelio gebėjimą ugdyti gilų samprotavimo įgūdžius. Toliau tobulėjant dirbtinio intelekto programoms, didėja modelių, galinčių generuoti atsakymus, paklausa ir kritiškai įvertinti savo rezultatus, kad būtų užtikrintas tikslumas ir loginis nuoseklumas.
Rimtai tradicinių mokymo metodų apribojimas yra tas, kad jie grindžiami atsakymų imitacija ir riboja modelius nuo kritinės reakcijų analizės. Dėl to imitacijai pagrįsti metodai nepateikia tinkamo loginio gylio, kai sprendžiami sudėtingos samprotavimo problemos, ir generuojami rezultatai dažnai primena teisingus atsakymus. Dar svarbiau, kad padidėjus duomenų rinkinių dydžiui, automatiškai nesukelia patobulintos sugeneruotos reakcijos kokybės, neigiamai paveikti didelių modelių mokymą. Šie iššūkiai atkreipia dėmesį į įvairių metodų poreikį, kuris geriau pagerintų samprotavimus, o ne padidina skaičiavimus.
Esami sprendimai bando sušvelninti šias problemas, naudodamas sustiprinimo mokymąsi ir instrukcijų derinimą. Stiprinimo mokymasis su žmonių atsiliepimais parodė perspektyvius rezultatus, tačiau reikalauja didelio masto skaičiavimo išteklių. Kitas požiūris apima savikritiką, kai modeliai įvertina jų klaidų rezultatą, tačiau tai dažnai trūksta nuoseklumo. Nepaisant šių patobulinimų, dauguma mokymo būdų vis dar orientuota į našumo optimizavimą per vientisą duomenų apimtį, o ne pagerinti pagrindines samprotavimo galimybes, o tai riboja jų veiksmingumą sudėtinguose problemų sprendimo scenarijuose.
Tyrimų komanda iš Vaterlo universiteto, Carnegie Mellon universiteto ir Vektorių institutas pasiūlė kritikuoti patobulinimą (CFT) kaip alternatyvą įprastiniam prižiūrimam derinimui. Šis požiūris nukreipia dėmesį nuo mokymosi imitacijai pagrįsto mokymosi į kritiką pagrįstą mokymąsi, kai modeliai mokomi įvertinti ir patobulinti atsakymus, o ne juos atkartoti. Norėdami tai pasiekti, tyrėjai sukonstravo 50 000 kritikos pavyzdžių duomenų rinkinį, naudodami GPT-4O, leidžiančius modeliams nustatyti atsako trūkumus ir pasiūlyti patobulinimus. Šis metodas yra ypač efektyvus domenams, reikalaujantiems struktūrizuotų samprotavimų, tokių kaip matematinis problemų sprendimas.
CFT metodika sukasi apie mokymo modelius, naudojant struktūrizuotų kritikos duomenų rinkinius, o ne įprastas klausimų ir atsakymų poras. Mokymo metu modeliams pateikiama užklausa ir pradinis atsakymas, po kurio seka kritika, įvertinanti atsakymo tikslumą ir loginę nuoseklumą. Optimizuodami modelį kritikai generuoti, tyrėjai skatina gilesnį analitinį procesą, kuris pagerina samprotavimo galimybes. Skirtingai nuo tradicinio derinimo, kai modeliai yra apdovanojami už tiesiog teisingų atsakymų atkūrimą, CFT teikia pirmenybę klaidų nustatymui ir siūlant patobulinimus, todėl atsiranda patikimesnių ir paaiškinamų rezultatų.
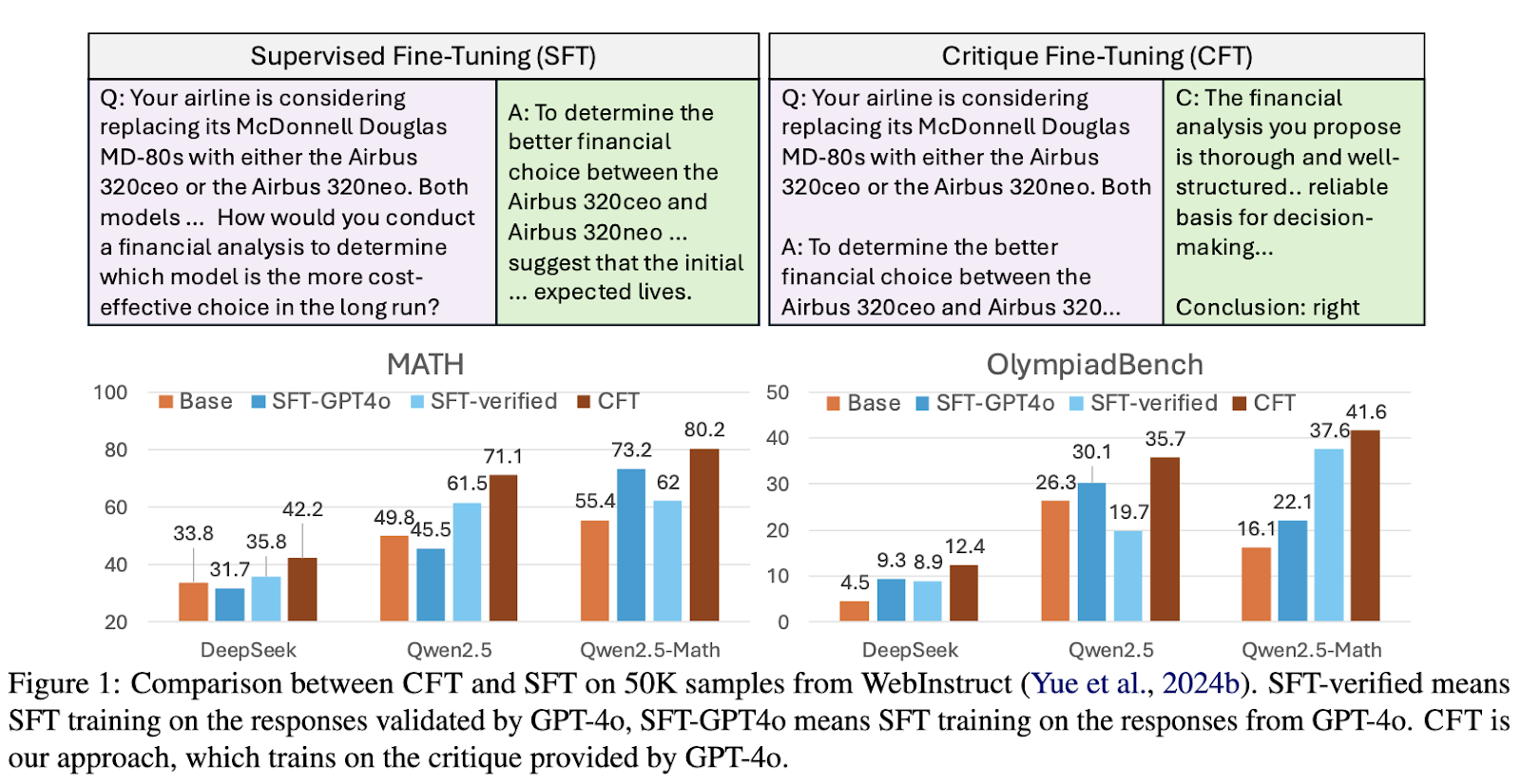
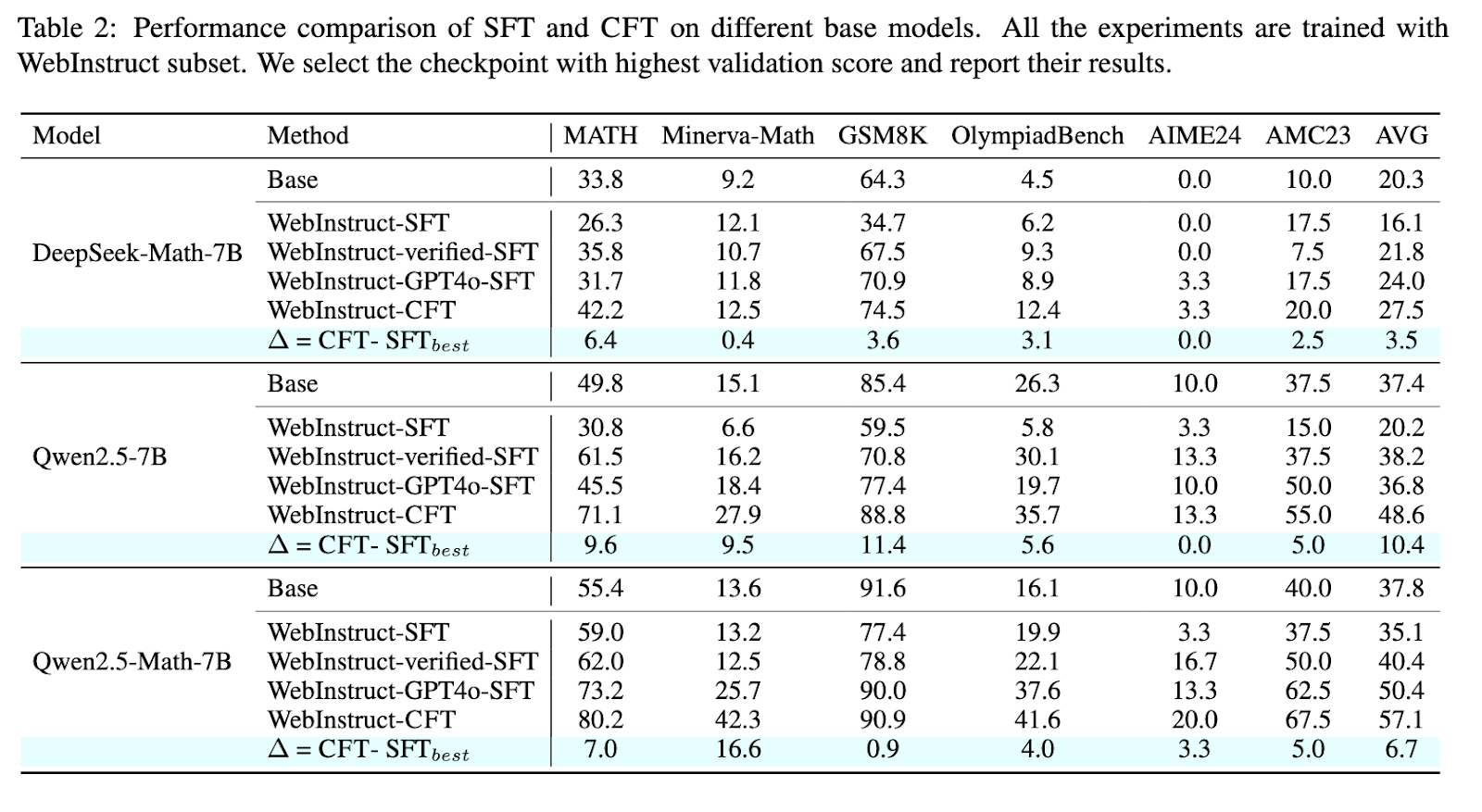
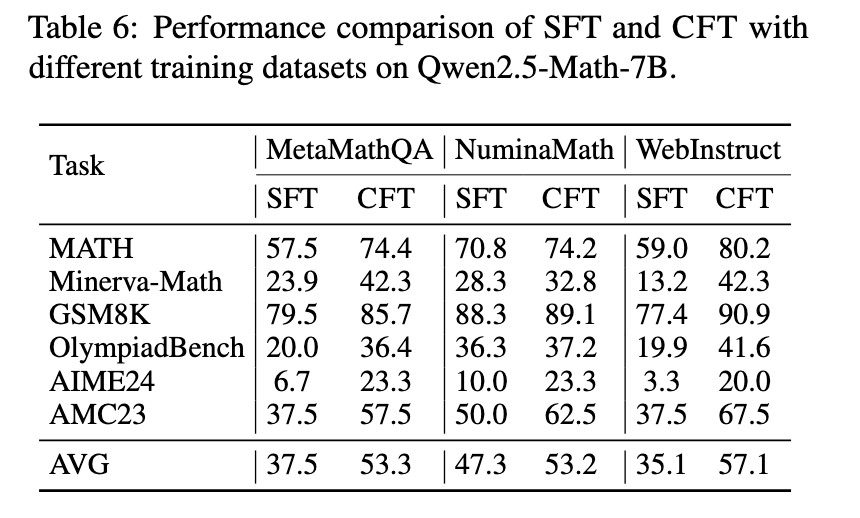
Eksperimentiniai rezultatai rodo, kad CFT treniruoti modeliai nuosekliai lenkia tuos, kurie yra mokomi naudojant įprastus metodus. Tyrėjai įvertino savo požiūrį įvairiais matematiniais samprotavimų etalonais, įskaitant matematiką, „Minerva-Math“ ir „Olympiadbench“. Modeliai, apmokyti naudojant CFT, parodė reikšmingą 4–10% našumo pagerėjimą, palyginti su jų prižiūrimais tiksliai suderintais kolegomis. Tiksliau, „Qwen2.5-Math-CFT“, kuris buvo apmokytas tik su 50 000 pavyzdžių, yra panašus į ir kartais net pranašesnį už modelius, konkuruojančius su daugiau nei 2 milijonai mokymų pavyzdžių. Be to, ši sistema padidino 7,0% matematikos etalono tikslumą ir 16,6% „Minerva-Math“, palyginti su standartiniais tikslinimo metodais. Šis reikšmingas patobulinimas rodo kritikos pagrįsto mokymosi efektyvumą, kuris dažnai skatina gerus rezultatus, turint žymiai mažiau mokymo pavyzdžių ir skaičiavimo išteklių.
Šio tyrimo išvados pabrėžia kritikų pagrįsto mokymosi pranašumus mokant kalbos modelį. Pereinant nuo atsakymo imitacijos prie kritikos kartos, tyrėjai pristatė metodą, kuris padidina modelio tikslumą ir skatina gilesnius samprotavimo įgūdžius. Gebėjimas kritiškai įvertinti ir patobulinti atsakymus, o ne generuoti juos, leidžia modeliams efektyviau atlikti sudėtingų samprotavimo užduotis. Šis tyrimas siūlo perspektyvią kryptį, kaip pagerinti dirbtinio intelekto mokymo metodikas, tuo pačiu sumažinant skaičiavimo išlaidas. Būsimasis darbas galėtų patobulinti požiūrį integruojant papildomus kritikos mechanizmus, siekiant pagerinti modelio patikimumą ir apibendrinimą įvairiose problemų sprendimo srityse.
Patikrinkite Popieriaus ir „GitHub“ puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 „MarkTechPost“ kviečia AI įmones/pradedančiuosius/grupes, kad jie galėtų partnerį už savo būsimus AI žurnalus „Atvirojo kodo AI gamyboje“ ir „Agentic AI“.
Nikhil yra „MarkTechPost“ stažuotės konsultantas. Jis siekia integruoto dvigubo laipsnio medžiagų Indijos technologijos institute, Kharagpur mieste. „Nikhil“ yra AI/ML entuziastas, kuris visada tiria programas tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagos mokslo patirtį, jis tyrinėja naujus pasiekimus ir sukuria galimybes prisidėti.
✅ (rekomenduojama) Prisijunkite prie mūsų „Telegram“ kanalo




