Natūralios kalbos apdorojimas (NLP) labai pažengė į priekį giliai mokydamasis, kurį paskatino naujovės, pvz., žodžių įterpimas ir transformatorių architektūra. Savarankiškai prižiūrimas mokymasis naudoja didžiulius kiekius nepaženklintų duomenų, kad būtų sukurtos priešmokymosi užduotys, ir tapo pagrindiniu mokymo modelių metodu, ypač daug išteklių reikalaujančiomis kalbomis, tokiomis kaip anglų ir kinų. NLP išteklių ir našumo skirtumai svyruoja nuo daug išteklių turinčių kalbų sistemų, tokių kaip anglų ir kinų, iki mažai išteklių turinčių kalbų sistemų, pvz. portugalųir daugiau nei 7000 kalbų visame pasaulyje. Toks atotrūkis trukdo NLP programoms, skirtoms mažai išteklių naudojančioms kalboms, augti ir būti tvirtesnėms bei prieinamesnėms. Be to, mažai išteklių reikalaujantys vienakalbiai modeliai išlieka mažo masto ir nedokumentuoti, jiems trūksta standartinių etalonų, todėl sudėtinga kurti ir įvertinti.

Dabartiniai kūrimo metodai dažnai naudoja didelius duomenų kiekius ir skaičiavimo išteklius, lengvai prieinamus daug išteklių turinčioms kalboms, tokioms kaip anglų ir kinų. Portugalijos NLP dažniausiai naudoja daugiakalbius modelius, pvz., mBERT, mT5 ir BLOOM, arba tiksliai suderina anglų kalba parengtus modelius. Tačiau šie metodai dažnai praleidžia unikalius portugalų kalbos aspektus. Vertinimo gairės yra senos arba pagrįstos anglų kalbos duomenų rinkiniais, todėl jie mažiau naudingi portugalų kalbai.
Norėdami tai išspręsti, mokslininkai iš Bonos universitetas išsivystė GigaVerbodidelio masto portugalų teksto korpusas, susidedantis iš 200 milijardų žetonų, ir apmokyta daugybė dekoderių-transformatorių, pavadintų Tucano. Šiais modeliais siekiama pagerinti portugalų kalbos modelių našumą, panaudojant didelį ir aukštos kokybės duomenų rinkinį.
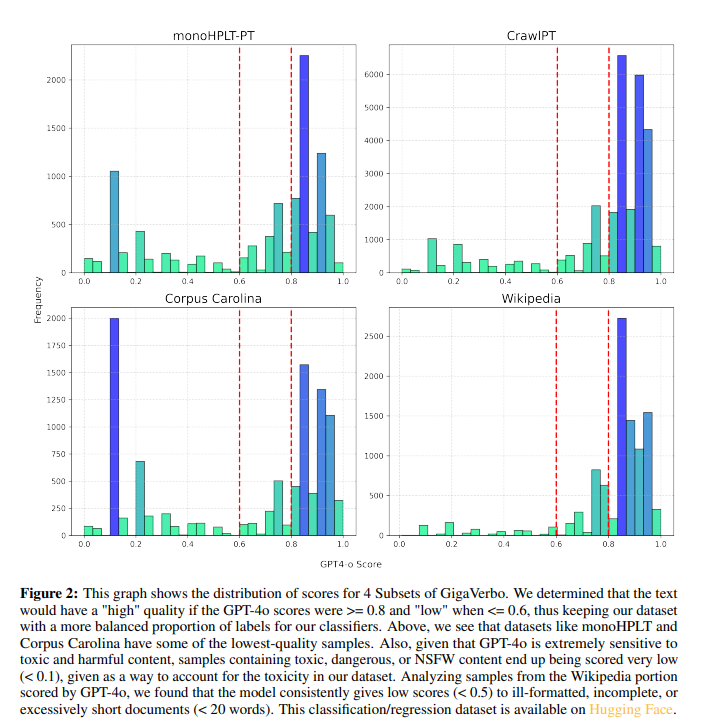
The GigaVerbo duomenų rinkinys yra kelių aukštos kokybės portugališko teksto korpusų sankaupa, patobulinta naudojant tinkintus filtravimo metodus, pagrįstus GPT-4 vertinimais. Filtravimo procesas pagerino išankstinį teksto apdorojimą, išlaikant 70 % modelio duomenų rinkinio. Remiantis Llama architektūra, Tucano modeliai buvo įgyvendinti naudojant Hugging Face, kad būtų lengviau pasiekti bendruomenę. Vietoj SwiGLU buvo naudojami tokie metodai kaip RoPE įterpimas, vidutinio kvadrato normalizavimas ir Silu aktyvinimas. Mokymai buvo atlikti naudojant priežastinio kalbos modeliavimo metodą ir kryžminės entropijos praradimą. Modelių parametrai svyruoja nuo 160 M iki 2,4 B, o didžiausias apmokytas 515 milijardų žetonų.
Šių modelių įvertinimas rodo, kad pagal kelis portugalų etalonus jie yra tokie patys arba geresni nei kiti panašaus dydžio portugalų ir daugiakalbių kalbų modeliai. Keturių bazinių modelių mokymo praradimo ir patvirtinimo sutrikimo kreivės parodė, kad didesni modeliai paprastai veiksmingiau sumažino nuostolius ir sumišimą, o poveikį sustiprino didesni partijos dydžiai. Kontroliniai taškai buvo išsaugoti kas 10,5 milijardo žetonų, o našumas buvo stebimas pagal kelis etalonus. Pearsono koreliacijos koeficientai rodė skirtingus rezultatus: kai kurie etalonai, pvz., CALAME-PT, LAMBADA ir HellaSwag, pagerėjo keičiant mastelį, o kiti, pavyzdžiui, OAB egzaminai, neparodė jokios koreliacijos su žetonų įsisavinimu. Atvirkštinis mastelio keitimas buvo pastebėtas submilijardų parametrų modeliuose, o tai rodo galimus apribojimus. Tai atskleidžia ir našumo etalonai Tucano lenkia daugiakalbius ir ankstesnius portugališkus modelius pagal vietinius vertinimus, pvz CALAME-PT ir mašininio vertimo testai, tokie kaip LAMBADA.
Apibendrinant galima pasakyti, kad „GigaVerbo“ ir „Tucano“ serijos pagerina portugalų kalbos modelių našumą. Siūlomas darbas apėmė kūrimo procesą, kuris apėmė duomenų rinkinio kūrimą, filtravimą, hiperparametrų derinimą ir įvertinimą, daugiausia dėmesio skiriant atvirumui ir atkuriamumui. Tai taip pat parodė, kad naudojant didelio masto duomenų rinkimą ir pažangius mokymo metodus galima tobulinti mažai išteklių reikalaujančius kalbų modelius. Šių mokslininkų indėlis bus naudingas teikiant šiuos būtinus išteklius būsimiems tyrimams vadovauti.
Patikrinkite Puslapis „Popierius ir apsikabinęs veidas“. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
🎙️ 🚨 „Didelių kalbos modelio pažeidžiamumų įvertinimas: lyginamoji raudonųjų komandų sudarymo metodų analizė“ Skaitykite visą ataskaitą (Paaukštintas)
Nazmi Syed yra „MarktechPost“ konsultacinė praktikantė ir siekia mokslų bakalauro laipsnio Indijos technologijos institute (IIT) Kharagpur. Ji labai domisi duomenų mokslu ir aktyviai tyrinėja platų dirbtinio intelekto pritaikymą įvairiose pramonės šakose. Sužavėtas technologijų pažangos, Nazmi yra įsipareigojęs suprasti ir įgyvendinti pažangiausias naujoves realiame pasaulyje.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)