Įkūnytas dirbtinis intelektas (AI) apima agentų, veikiančių fizinėje arba imituojamoje aplinkoje, kūrimą, savarankiškai vykdančius užduotis pagal iš anksto nustatytus tikslus. Šie agentai, dažnai naudojami robotikoje ir sudėtinguose modeliavimuose, naudoja didelius duomenų rinkinius ir sudėtingus modelius, kad optimizuotų elgesį ir sprendimų priėmimą. Priešingai nei paprastesnėse programose, įkūnytas AI reikalauja modelių, galinčių valdyti didelius sensorinių motorinių duomenų kiekius ir sudėtingą interaktyvią dinamiką. Todėl šioje srityje vis labiau teikiama pirmenybė „mastelio keitimui“ – procesui, kuris koreguoja modelio dydį, duomenų rinkinio apimtį ir skaičiavimo galią, kad būtų pasiektas efektyvus ir efektyvus agento veikimas atliekant įvairias užduotis.
Iššūkis, susijęs su įkūnytų AI modelių masteliu, yra rasti pusiausvyrą tarp modelio dydžio ir duomenų rinkinio apimties, o tai yra procesas, būtinas siekiant užtikrinti, kad šie agentai galėtų optimaliai veikti, atsižvelgiant į skaičiavimo išteklių apribojimus. Skirtingai nuo kalbų modelių, kuriuose mastelio keitimas yra nusistovėjęs, vis dar reikia ištirti tikslią tokių veiksnių, kaip duomenų rinkinio dydis, modelio parametrai ir skaičiavimo sąnaudos įkūnytame AI, sąveiką. Šis aiškumo trūkumas riboja tyrėjų galimybes efektyviai kurti didelio masto modelius, nes lieka neaišku, kaip optimaliai paskirstyti išteklius užduotims, kurioms reikalingas elgsenos ir aplinkos prisitaikymas. Pavyzdžiui, nors modelio dydžio padidinimas pagerina našumą, tai darant proporcingai nepadidinus duomenų, gali sumažėti efektyvumas ar net sumažėti grąža, ypač atliekant tokias užduotis kaip elgesio klonavimas ir pasaulio modeliavimas.
Kalbos modeliai sukūrė tvirtus mastelio keitimo įstatymus, nubrėžiančius modelio dydžio, duomenų ir skaičiavimo reikalavimų ryšį. Šie dėsniai leidžia tyrėjams parengti pagrįstas prognozes apie būtinų konfigūracijų efektyviam modelių mokymui. Tačiau įkūnytas dirbtinis intelektas ne visiškai pritaikė šių principų, iš dalies dėl skirtingo užduočių pobūdžio. Reaguodami į tai, mokslininkai stengėsi perkelti įžvalgas iš kalbos modelių į įkūnytą AI, ypač iš anksto apmokydami didelius neprisijungus naudojamus duomenų rinkinius, kurie fiksuoja įvairius aplinkos ir elgesio duomenis. Tikslas yra nustatyti įstatymus, kurie padėtų agentams pasiekti aukštų rezultatų priimant sprendimus ir sąveikaujant su juos supančia aplinka.
„Microsoft Research“ mokslininkai neseniai sukūrė mastelio keitimo dėsnius, skirtus specialiai įkūnytam AI, įdiegdami metodiką, kuri įvertina, kaip modelio parametrų, duomenų rinkinio dydžio ir skaičiavimo ribų pokyčiai daro įtaką AI agentų mokymosi efektyvumui. Grupės darbas buvo sutelktas į dvi pagrindines užduotis, susijusias su įkūnijamu AI: elgesio klonavimu, kai agentai mokosi pakartoti pastebėtus veiksmus, ir pasaulio modeliavimą, kai agentai prognozuoja aplinkos pokyčius remdamiesi ankstesniais veiksmais ir stebėjimais. Jie naudojo transformatoriumi pagrįstas architektūras, išbandydami savo modelius įvairiomis konfigūracijomis, kad suprastų, kaip žetonų nustatymo strategijos ir modelio suspaudimo greitis veikia bendrą efektyvumą ir tikslumą. Sistemingai koreguodami parametrų ir žetonų skaičių, mokslininkai pastebėjo skirtingus mastelio modelius, kurie galėtų pagerinti modelio našumą ir skaičiavimo efektyvumą.
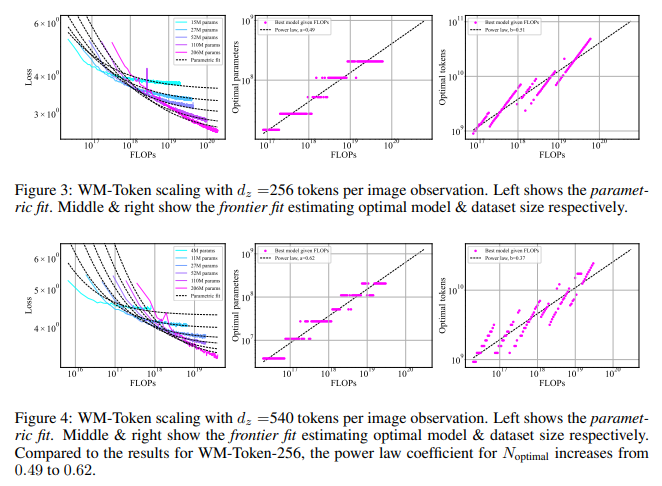
Metodika apėmė transformatorių mokymą su skirtingais tokenizacijos metodais, kad būtų galima subalansuoti modelio ir duomenų rinkinio dydžius. Pavyzdžiui, komanda įdiegė tokenizuotas ir CNN pagrįstas architektūras elgsenos klonavimui, leidžiančią modeliui veikti pagal nuolatinio įterpimo sistemą, o ne atskirus žetonus, o tai žymiai sumažino skaičiavimo poreikius. Tyrimas parodė, kad pasaulio modeliavimo mastelio dėsniai parodė, kad vieno stebėjimo žetonų skaičiaus padidėjimas turėjo įtakos modelio dydžiui, o optimalaus modelio dydžio koeficientas padidėjo nuo 0,49 iki 0,62, kai žetonai padidėjo nuo 256 iki 540 vienam vaizdui. Tačiau elgsenos klonavimui naudojant tokenizuotus stebėjimus, optimalaus modelio dydžio koeficientai buvo nukreipti į didesnius duomenų rinkinius su mažesniais modeliais, o tai rodo, kad reikia didesnio duomenų kiekio, o ne išplėstų parametrų, o tai yra priešinga tendencija, nei pastebima pasaulio modeliavime.
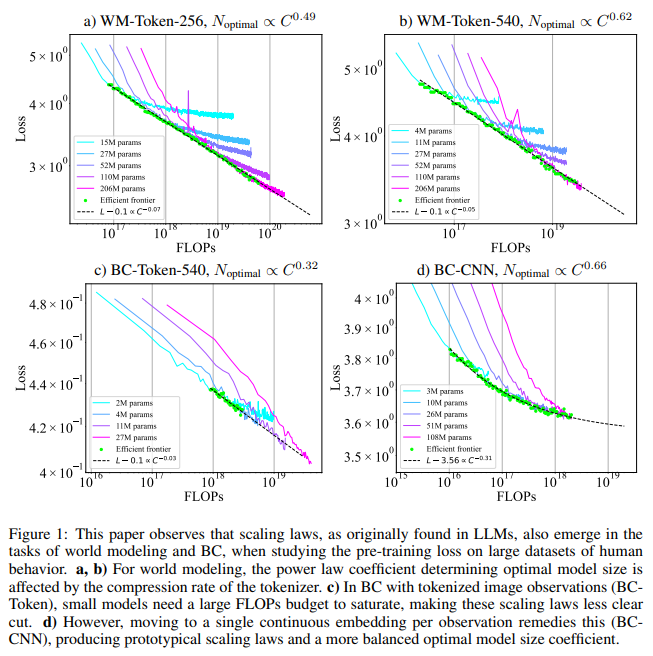
Tyrimas pateikė puikių išvadų, kaip kalbos modelių mastelio keitimo principus būtų galima veiksmingai pritaikyti įkūnytam AI. Optimalus kompromisas įvyko pasaulio modeliavimui, kai tiek modelio, tiek duomenų rinkinio dydis padidėjo proporcingai, sutapdami su LLM mastelio keitimo literatūroje. Tiksliau, naudojant 256 žetonų konfigūraciją, optimali pusiausvyra buvo pasiekta panašiomis proporcijomis keičiant modelį ir duomenų rinkinį. Priešingai, 540 žetonų konfigūracijoje dėmesys buvo perkeltas į didesnius modelius, todėl dydžio koregavimas labai priklausė nuo tokenizuotų stebėjimų suspaudimo greičio.
Pagrindiniai rezultatai parodė, kad modelio architektūra turi įtakos mastelio balansui, ypač elgesio klonavimui. Atliekant užduotis, kuriose agentai naudojo tokenizuotus stebėjimus, modelio koeficientai rodė pirmenybę dideliems duomenims, o ne didesniems modelių dydžiams, kurių optimalus dydžio koeficientas yra 0,32, palyginti su duomenų rinkinio koeficientu 0,68. Palyginimui, elgesio klonavimo užduotys, pagrįstos CNN architektūra, padidino modelio dydį, o optimalus dydžio koeficientas buvo 0, 66. Tai parodė, kad įkūnytas AI gali pasiekti efektyvų mastelį tam tikromis sąlygomis, pritaikydamas modelio ir duomenų rinkinio proporcijas pagal užduoties reikalavimus.
Tikrindama išvestinių mastelio keitimo dėsnių tikslumą, tyrėjų komanda apmokė pasaulinį modeliavimo agentą, kurio modelio dydis yra 894 milijonai parametrų, žymiai didesni nei tie, kurie buvo naudojami ankstesnėse mastelio analizėse. Tyrimo metu nustatyta, kad prognozės ir faktiniai rezultatai yra stipriai suderinti, o nuostolių vertė labai atitiko apskaičiuotus optimalius nuostolių lygius, net ir esant žymiai padidintam skaičiavimo biudžetui. Šis patvirtinimo žingsnis pabrėžė mastelio dėsnių patikimumą, o tai rodo, kad naudojant tinkamą hiperparametrų derinimą mastelio dėsniai gali veiksmingai numatyti modelio veikimą sudėtinguose modeliavimuose ir realaus pasaulio scenarijuose.
Pagrindiniai tyrimo aspektai:
- Subalansuotas mastelio keitimas pasaulio modeliavimui: kad pasaulio modeliavimas veiktų optimaliai, tiek modelio, tiek duomenų rinkinio dydžiai turi būti proporcingai didinami.
- Elgesio klonavimo optimizavimas: Optimalios elgsenos klonavimo konfigūracijos yra palankios mažesniems modeliams, susietiems su dideliais duomenų rinkiniais, kai naudojami tokenizuoti stebėjimai. CNN pagrįstoms klonavimo užduotims pageidautina padidinti modelio dydį.
- Suspaudimo greičio įtaka: didesni žetonų glaudinimo laipsniai iškreipia mastelio dėsnius į didesnius modelius pasaulio modeliavime, o tai rodo, kad žetonų duomenys iš esmės paveikia optimalius modelio dydžius.
- Ekstrapoliacijos patvirtinimas: bandymai su didesniais modeliais patvirtino mastelio dėsnių nuspėjamumą ir palaiko šiuos dėsnius kaip veiksmingo modelio dydžio nustatymo pagrindą įkūnytame AI.
- Skirtingi užduočių reikalavimai: mastelio reikalavimai labai skiriasi elgsenos klonavimo ir pasaulio modeliavimo atveju, todėl pabrėžiama pritaikytų mastelio keitimo metodų svarba skirtingoms AI užduotims atlikti.

Apibendrinant galima pasakyti, kad šis tyrimas patobulina įkūnytą AI, pritaikydamas kalbos modelio mastelio įžvalgas AI agentų užduotims. Tai leidžia mokslininkams tiksliau numatyti ir kontroliuoti išteklių poreikius. Nustačius šiuos pritaikytus mastelio keitimo įstatymus, padedama kurti efektyvesnius, pajėgesnius agentus aplinkoje, kurioje reikalingas didelis skaičiavimo ir duomenų efektyvumas.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(NEMOKAMAS AI internetinis seminaras) Sumanaus dokumentų apdorojimo su GenAI įgyvendinimas finansinių paslaugų ir nekilnojamojo turto sandoriuose
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🐝🐝 Artėjantis tiesioginis LinkedIn renginys „Viena platforma, daugiarūšės galimybės“, kuriame „Encord“ generalinis direktorius Ericas Landau ir produktų inžinerijos vadovas Justinas Sharpsas kalbės, kaip jie iš naujo išranda duomenų kūrimo procesą, kad padėtų komandoms greitai kurti žaidimus keičiančius multimodalinius AI modelius.