

Autoregresyvus išankstinis mokymas pasirodė esąs revoliucinis mašininio mokymosi srityje, ypač kai tai susiję su nuosekliu duomenų apdorojimu. Nuspėjamasis šių sekos elementų modeliavimas buvo labai efektyvus natūralios kalbos apdorojime ir vis dažniau buvo tiriamas kompiuterinio regėjimo srityse. Vaizdo įrašų modeliavimas yra mažai ištirta sritis, suteikianti galimybę išplėsti veiksmų atpažinimą, objektų sekimą ir robotikos programas. Šiuos pokyčius lėmė augantys duomenų rinkiniai ir naujovės transformatorių architektūrose, kurios vaizdinius įvestis traktuoja kaip struktūrinius žetonus, tinkamus autoregresiniam mokymui.
Vaizdo įrašų modeliavimas turi unikalių iššūkių dėl jų laiko dinamikos ir pertekliškumo. Skirtingai nuo teksto su aiškia seka, vaizdo įrašų kadruose paprastai yra perteklinės informacijos, todėl sunku nustatyti ir išmokti tinkamų vaizdų. Tinkamas vaizdo modeliavimas turėtų padėti įveikti šį perteklumą, o erdvėlaikinius santykius užfiksuoti kadruose. Dauguma sistemų buvo sutelktos į vaizdu pagrįstą atvaizdavimą, todėl vaizdo įrašų architektūros optimizavimas liko atviras. Šiai užduočiai atlikti reikalingi nauji efektyvumo ir našumo pusiausvyros metodai, ypač kai atliekama vaizdo prognozė ir manipuliavimas robotais.
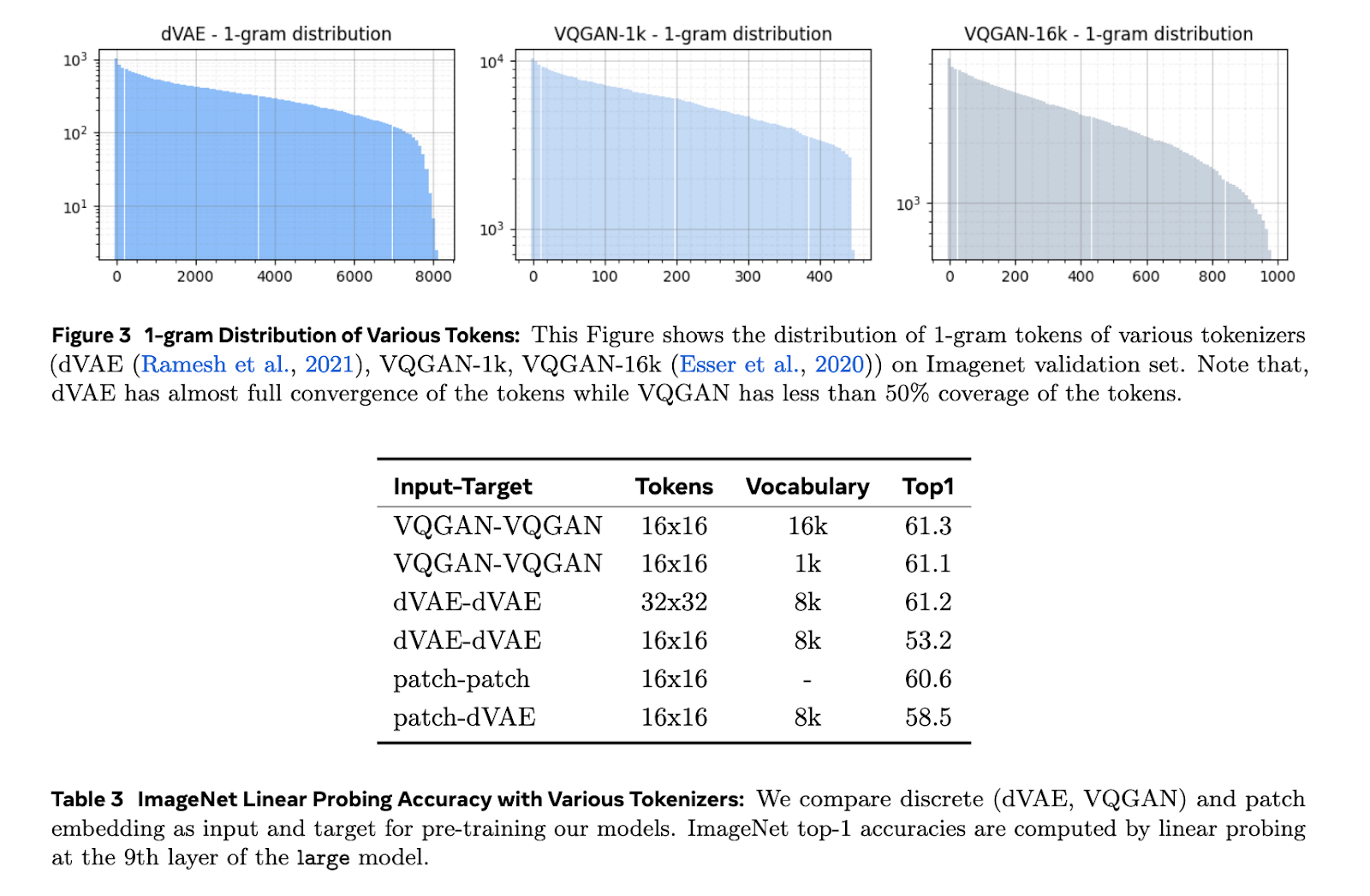
Vaizdo vaizdavimo mokymasis naudojant konvoliucinius tinklus ir užmaskuotus automatinius koduotuvus buvo veiksmingas atliekant vaizdo užduotis. Tokie metodai paprastai nepavyksta naudojant vaizdo įrašų programas, nes jie negali visiškai išreikšti laiko priklausomybių. Tokenizacijos metodai, tokie kaip dVAE ir VQGAN, paprastai vaizdinę informaciją paverčia žetonais. Jie parodė veiksmingumą, tačiau tokio požiūrio mastelio keitimas tampa sudėtingas scenarijuose su mišriais duomenų rinkiniais, kuriuose yra vaizdai ir vaizdo įrašai. Pataisų pagrindu sukurtas prieigos raktas nėra apibendrintas, kad būtų galima efektyviai atlikti įvairias užduotis vaizdo įraše.
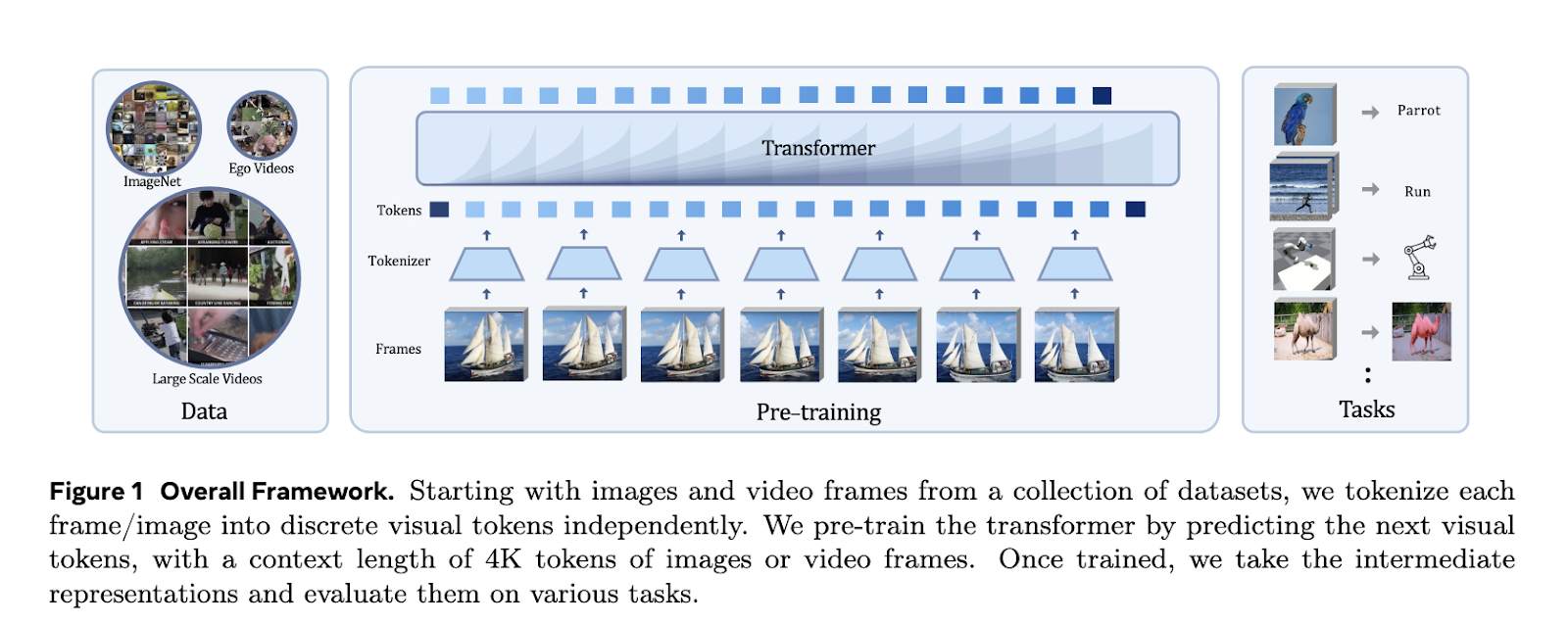
„Meta FAIR“ ir „UC Berkeley“ tyrimų grupė pristatė „Toto“ autoregresyvių vaizdo modelių šeimą. Jų naujovė yra padėti išspręsti tradicinių metodų apribojimus, vaizdo įrašus traktuojant kaip atskirų vaizdinių žetonų sekas ir taikant priežastinių transformatorių architektūrą, kad būtų galima numatyti tolesnius prieigos raktus. Tyrėjai sukūrė modelius, kurie galėtų lengvai sujungti vaizdo ir vaizdo mokymą, treniruodami vieningą duomenų rinkinį, kuriame yra daugiau nei vienas trilijonas žetonų iš vaizdų ir vaizdo įrašų. Vieningas požiūris leido komandai pasinaudoti autoregresinio išankstinio mokymo pranašumais abiejose srityse.
Toto modeliai naudoja dVAE atpažinimą su 8k žetonų žodynu vaizdams ir vaizdo įrašų kadrams apdoroti. Kiekvieno kadro dydis keičiamas ir atpažįstamas atskirai, todėl gaunamos 256 žetonų sekos. Tada šiuos žetonus apdoroja priežastinis transformatorius, kuris naudoja RMSNorm ir RoPE įterpimo funkcijas, kad pagerintų modelio veikimą. Mokymas buvo atliktas naudojant „ImageNet“ ir „HowTo100M“ duomenų rinkinius, ženklinančius 128 × 128 pikselių raiška. Tyrėjai taip pat optimizavo tolesnių užduočių modelius, pakeisdami vidutinį sutelkimą dėmesio sutelkimu, kad užtikrintų geresnę vaizdavimo kokybę.
Modeliai rodo gerą našumą pagal etalonus. Pagal „ImageNet“ klasifikaciją didžiausias „Toto“ modelis pasiekė aukščiausią 75,3 % tikslumą, pralenkdamas kitus generuojančius modelius, tokius kaip MAE ir iGPT. Kinetics-400 veiksmų atpažinimo užduotyje modeliai pasiekia aukščiausią 74,4 % tikslumą, įrodantį jų gebėjimą suprasti sudėtingą laiko dinamiką. DAVIS duomenų rinkinyje, skirtame pusiau prižiūrimam vaizdo stebėjimui, modeliai gauna iki 62,4 J&F balų, taip pagerindami ankstesnius pažangiausius etalonus, kuriuos nustatė DINO ir MAE. Be to, atliekant robotikos užduotis, pvz., manipuliavimą objektu, Toto modeliai mokosi daug greičiau ir yra efektyvesni. Pavyzdžiui, „Toto-base“ modelis atlieka realaus pasaulio „Franka“ roboto kubo paėmimo užduotį 63% tikslumu. Apskritai, tai yra įspūdingi rezultatai, susiję su šių siūlomų modelių su įvairiomis programomis universalumu ir masteliu.

Darbas suteikė reikšmingą vaizdo modeliavimo pažangą, nes buvo sprendžiamas perteklius ir tokenizacijos iššūkiai. Tyrėjai sėkmingai įrodė, kad „vieningi vaizdų ir vaizdo įrašų mokymai parodė, kad ši autoregresinio treniruočių forma paprastai yra veiksminga atliekant įvairias užduotis“. Novatoriška architektūra ir tokenizacijos strategijos yra pagrindas tolesniems tankiems numatymo ir atpažinimo tyrimams. Tai yra vienas reikšmingas žingsnis siekiant išnaudoti visą vaizdo modeliavimo potencialą realiose programose.
Patikrinkite Popieriaus ir projekto puslapyje. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 65k+ ML SubReddit.
🚨 NEMOKAMAS BŪTINAS AI internetinis seminaras (2025 M. SAUSIO 15 d.): padidinkite LLM tikslumą naudodami sintetinius duomenis ir įvertinimo informaciją–Prisijunkite prie šio internetinio seminaro, kad gautumėte veiksmingų įžvalgų, kaip padidinti LLM modelio našumą ir tikslumą, kartu išsaugant duomenų privatumą.
Nikhilas yra „Marktechpost“ konsultantas. Indijos technologijos institute Charagpūre jis siekia integruoto dvigubo medžiagų studijų laipsnio. Nikhilas yra AI / ML entuziastas, kuris visada tiria pritaikymą tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagų mokslo išsilavinimą, jis tyrinėja naujus pasiekimus ir kuria galimybes prisidėti.
✅ (Rekomenduojama skaityti) „Nebius AI Studio“ plečiasi regėjimo modeliais, naujais kalbos modeliais, įterpimais ir LoRA (reklamuojama)




