

Kalbų modeliai (LMS) labai pažengė per padidėjusią skaičiavimo galią treniruotės metu, pirmiausia dėl didelio masto paties prižiūrimo išankstinio pranešimo. Nors šis požiūris davė galingus modelius, atsirado nauja paradigma, vadinama bandymo laiko masteliu, daugiausia dėmesio skiriant našumo gerinimui, padidinant skaičiavimą išvados metu. „Openai“ O1 modelis patvirtino šį požiūrį, parodydamas patobulintas samprotavimo galimybes per bandymo laiko skaičiavimo mastelį. Tačiau šių rezultatų atkartojimas pasirodė sudėtingas, įvairiais bandymais naudojant tokius metodus kaip „Monte Carlo Tree Search“ (MCT), daugialypės terpės metodus ir mokymąsi armatūros mokymosi. Net tokiuose modeliuose kaip „Deepseek R1“ buvo naudojami milijonai mėginių ir sudėtingų treniruočių stadijų, tačiau nė vienas iš jų neatkartojo bandymo laiko mastelio elgsenos O1.
Buvo sukurti įvairūs metodai, skirti spręsti bandymo laiko mastelio keitimo iššūkį. Nuoseklus mastelio keitimo metodai leidžia modeliams generuoti bandymus iš eilės iš eilės, o kiekviena iteracija remiasi ankstesniais rezultatais. Medžių paieškos metodai sujungia nuoseklųjį ir lygiagrečią mastelio keitimą, įgyvendinimo būdus, tokius kaip MCT ir gidų pluošto paieška. „Rebase“ atsirado kaip pastebimas požiūris, pasinaudojant proceso apdovanojimo modeliu, siekiant optimizuoti medžių paiešką subalansuotame išnaudojime ir genėjant, parodant aukštesnį našumą, palyginti su mėginių ėmimo metodais ir MCT. Šie požiūriai labai priklauso nuo atlygio modelių, kurie pateikiami dviem formomis: rezultato apdovanojimo modeliais už išsamius sprendimus geriausio „-N“ atrankos sprendimų įvertinime, ir apdoroti atlygio modelius už individualių samprotavimo veiksmų vertinimą medžių paieškos metoduose.
Stanfordo universiteto, Vašingtono universiteto, Alleno AI instituto ir kontekstinės AI tyrėjai pasiūlė supaprastintą požiūrį į bandymo laiko mastelio keitimo ir patobulintų samprotavimo galimybes. Jų metodas sutelktas į dvi pagrindines naujoves: kruopščiai kuruojamą S1K duomenų rinkinį, kurį sudaro 1000 klausimų su samprotavimo pėdsakais, pasirinktais atsižvelgiant į sunkumus, įvairovę ir kokybės kriterijus bei naują techniką, vadinamą biudžeto jėga. Šis biudžeto nustatymo mechanizmas kontroliuoja bandymo laiko skaičiavimą, sumažindamas trumpą laiką arba pratęsdamas modelio mąstymo procesą per strateginius „laukimo“ įterpimus, leidžiančius modeliui peržiūrėti ir ištaisyti jo samprotavimus. Šis metodas buvo įgyvendintas patobulinant „QWEN2.5-32B“ kalbos kalbos modelį S1K duomenų rinkinyje.
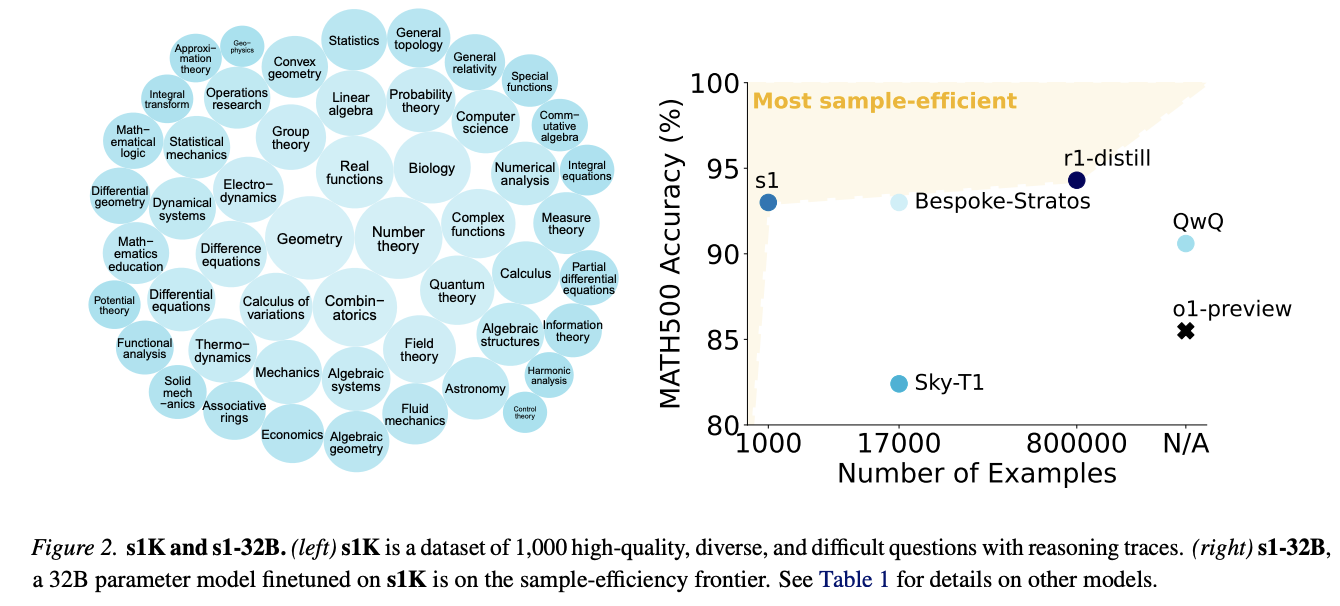
Duomenų atrankos procesas atitinka trijų pakopų filtravimo metodą, pagrįstą kokybės, sunkumų ir įvairovės kriterijais. Kokybės filtravimo etapas prasideda pašalinant pavyzdžius su API klaidomis ir formatavimo problemomis, sumažinant pradinį duomenų rinkinį iki 51 581 pavyzdžių, iš kurių iš pradžių pasirinkta 384 aukštos kokybės pavyzdžiai. Sunkumo įvertinime naudojama dvi pagrindinės metrikos: modelio veikimo įvertinimas naudojant QWEN2.5-7B instrukciją ir QWEN2.5-32B instrukcijų modelius, su teisingumu, patikrintu Claude 3.5 sonnet, ir samprotavimo pėdsakų ilgį, išmatuotą QWEN2.5 tokenizatoriumi. Įvairei klausimai klasifikuojami į konkrečias sritis, naudojant matematikos temų klasifikavimo sistemą per „Claude 3.5 Sonnet“. Šis išsamus filtravimo procesas lemia galutinį 1000 pavyzdžių duomenų rinkinį, apimantį 50 domenų.
S1-32B modelis parodo reikšmingą našumo pagerėjimą per bandymo laiko skaičiavimo mastelį su biudžeto jėga. S1-32B veikia aukštesnėje mastelio keitimo paradigmoje, palyginti su baziniu QWEN2.5-32B instruktoriaus modeliu, naudojant daugumos balsavimą, patvirtindamas nuoseklaus mastelio veiksmingumą lygiagrečiais metodais. Be to, S1-32B išryškėja kaip efektyviausias atvirų duomenų pagrindimo modelis imties efektyvume, parodydamas ryškų pagrindinio modelio pagerėjimą tik 1000 papildomų mokymo pavyzdžių. Nors R1-32B pasiekia geresnį našumą, reikia 800 kartų daugiau mokymo duomenų. Pažymėtina, kad S1-32B artėja prie „Gemini 2.0“ mąstymo AIME24 pasirodymo, siūlančio sėkmingą distiliavimą žiniomis.
Straipsnyje parodyta, kad prižiūrimi tobulinimo (SFT) su vos 1000 kruopščiai parinktų pavyzdžių gali sukurti konkurencinį samprotavimo modelį, kuris atitiktų O1-Preview našumą ir pasiektų optimalų efektyvumą. Įvedama biudžeto priverstinė technika, derinama su samprotavimo modeliu, sėkmingai atkuria „Openai“ bandymo laiko mastelio keitimo elgseną. Tokių minimalių mokymo duomenų veiksmingumas rodo, kad modelio samprotavimo galimybės daugiausia yra išankstinėje trilijonų žetonų trilijonuose, o tikslinimo procesas tik suaktyvina šiuos latentinius sugebėjimus. Tai suderinta su „paviršutiniškos suderinimo hipoteze“ iš Lima tyrimų, kas rodo, kad palyginti nedaug pavyzdžių gali efektyviai suderinti modelio elgesį su norimais rezultatais.
Patikrinkite Popieriaus ir „GitHub“ puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (reklamuojama)

Sajjad Ansari yra paskutinių metų bakalauras iš IIT Kharagpur. Kaip technikos entuziastas, jis gilinasi į AI praktinius pritaikymus, daugiausia dėmesio skirdamas AI technologijų poveikio ir jų realiojo poveikio poveikiui supratimui. Jis siekia aiškiai ir prieinamai išdėstyti sudėtingas AI sąvokas.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo





