

Daugiarūšiai didelių kalbų modeliai (MLLM) sparčiai tobulėja, todėl mašinos vienu metu gali interpretuoti ir svarstyti tekstinius ir vaizdinius duomenis. Šie modeliai turi transformuojančias vaizdų analizės programas, vizualinius atsakymus į klausimus ir daugiarūšį samprotavimą. Mažindami atotrūkį tarp vizijos ir kalbos, jie atlieka labai svarbų vaidmenį gerinant dirbtinio intelekto gebėjimą suprasti pasaulį ir visapusiškai su juo bendrauti.
Nepaisant pažadų, šios sistemos turi įveikti didelius iššūkius. Pagrindinis apribojimas yra priklausomybė nuo natūralios kalbos priežiūros treniruočių metu, dėl ko dažnai būna neoptimali vaizdo vaizdavimo kokybė. Nors didėjantis duomenų rinkinio dydis ir skaičiavimo sudėtingumas lėmė nedidelius patobulinimus, juos reikia tikslingiau optimizuoti, kad šiuos modelius būtų galima suprasti, kad būtų užtikrintas norimas našumas atliekant vizija pagrįstas užduotis. Dabartiniais metodais dažnai reikia suderinti skaičiavimo efektyvumą ir geresnį našumą.
Esami MLLM mokymo metodai paprastai apima vaizdinių kodavimo priemonių naudojimą, kad iš vaizdų išskirtų ypatybes ir įtrauktų jas į kalbos modelį kartu su natūralios kalbos duomenimis. Kai kuriuose metoduose naudojami keli vaizdiniai kodavimo įrenginiai arba kryžminio dėmesio mechanizmai, siekiant pagerinti supratimą. Tačiau šie metodai kainuoja žymiai aukštesnius duomenų ir skaičiavimo reikalavimus, todėl ribojamas jų mastelio keitimas ir praktiškumas. Šis neefektyvumas pabrėžia, kad reikia veiksmingesnio būdo optimizuoti MLLM vizualiniam supratimui.
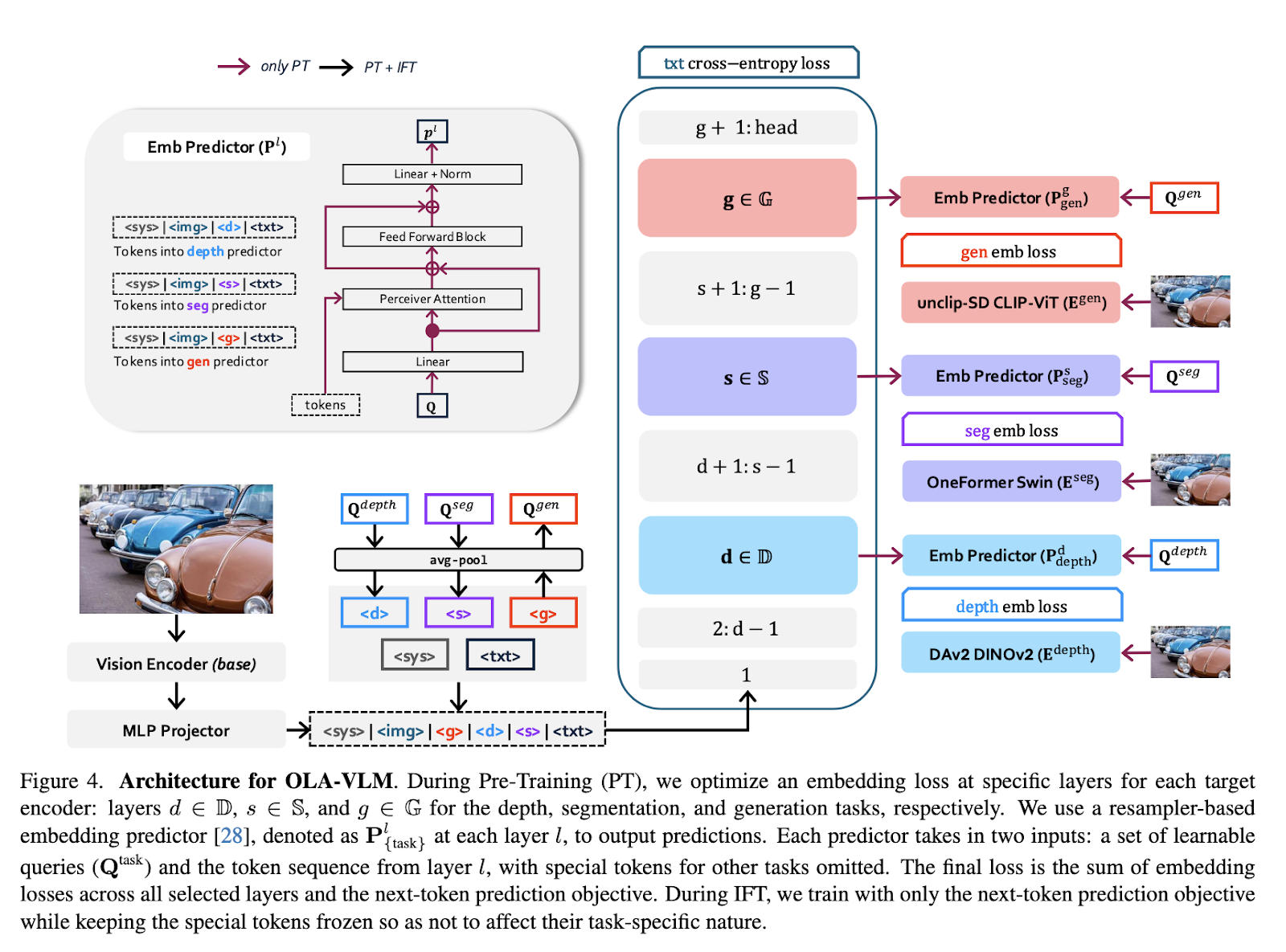
SHI Labs (Georgia Tech) ir „Microsoft Research“ tyrėjai pristatė naują metodą, vadinamą OLA-VLM, kad galėtų išspręsti šiuos iššūkius. Metodu siekiama pagerinti MLLM, distiliuojant pagalbinę vaizdinę informaciją į paslėptus sluoksnius išankstinio mokymo metu. Užuot padidinęs vizualinio kodavimo įrenginio sudėtingumą, OLA-VLM naudoja įterpimo optimizavimą, kad pagerintų vaizdinių ir tekstinių duomenų derinimą. Šio optimizavimo įdiegimas į tarpinius kalbos modelio sluoksnius užtikrina geresnį vaizdinį samprotavimą be papildomų skaičiavimo išlaidų darant išvadą.
OLA-VLM technologija apima praradimo funkcijų įterpimą, siekiant optimizuoti specializuotų vaizdo kodavimo įrenginių vaizdus. Šie koduotuvai yra apmokyti vaizdų segmentavimo, gylio įvertinimo ir vaizdo generavimo užduotims atlikti. Distiliuotos funkcijos yra susietos su tam tikrais kalbos modelio sluoksniais, naudojant nuspėjamojo įterpimo optimizavimo metodus. Be to, prie įvesties sekos pridedami specialūs konkrečios užduoties žetonai, leidžiantys modeliui sklandžiai įtraukti pagalbinę vaizdinę informaciją. Šis dizainas užtikrina, kad vaizdinės funkcijos būtų veiksmingai integruotos į MLLM reprezentacijas, nepažeidžiant pagrindinio mokymo tikslo – kito žetono numatymo. Rezultatas yra modelis, kuris išmoksta tvirtesnių ir į viziją orientuotų vaizdų.
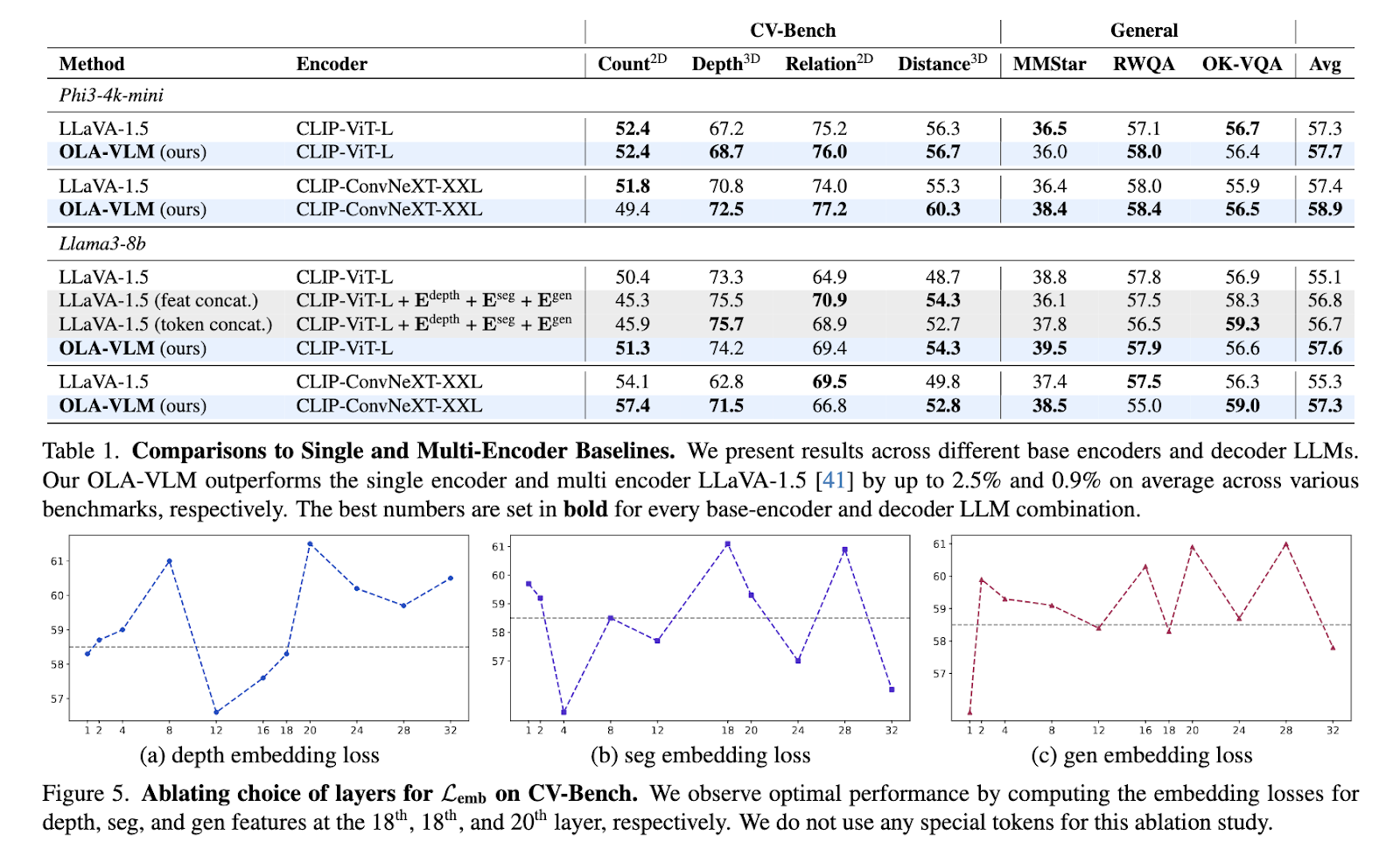
OLA-VLM našumas buvo griežtai išbandytas įvairiais etalonais, o tai rodo esminius patobulinimus, palyginti su esamais vieno ir kelių kodavimo įrenginių modeliais. CV-Bench, į regėjimą orientuotame etaloniniame rinkinyje, OLA-VLM, atlikdama išsamų įvertinimą, pralenkė LLaVA-1.5 bazinę liniją iki 8,7 % ir pasiekė 77,8 % tikslumą. Atliekant segmentavimo užduotis, vidutinis susikirtimo virš Sąjungos (mIoU) balas buvo 45,4%, o tai žymiai pagerėjo, palyginti su pradine 39,3%. Modelis taip pat parodė nuoseklų 2D ir 3D regėjimo užduočių naudą, pasiekdamas vidutiniškai iki 2,5 % pagerėjimą pagal tokius etalonus kaip atstumas ir santykio samprotavimai. OLA-VLM pasiekė šiuos rezultatus naudodamas tik vieną vizualinį kodavimo įrenginį išvados metu, todėl jis yra daug efektyvesnis nei kelių kodavimo sistemų.
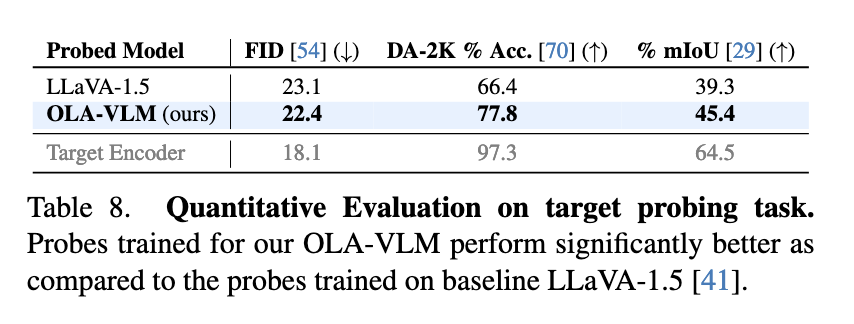
Norėdami dar labiau patvirtinti jo veiksmingumą, mokslininkai išanalizavo OLA-VLM gautus vaizdus. Zondavimo eksperimentai atskleidė, kad modelis pasiekė puikų vizualinių savybių suderinimą tarpiniuose sluoksniuose. Šis suderinimas žymiai pagerino modelio našumą atliekant įvairias užduotis. Pavyzdžiui, mokslininkai pažymėjo, kad specialių konkrečioms užduotims skirtų žetonų integravimas treniruočių metu padėjo geriau optimizuoti gylio, segmentavimo ir vaizdo generavimo užduotis. Rezultatai pabrėžė nuspėjamojo įterpimo optimizavimo metodo efektyvumą, įrodantį jo gebėjimą suderinti aukštos kokybės vaizdinį supratimą su skaičiavimo efektyvumu.
OLA-VLM nustato naują vaizdinės informacijos integravimo į MLLM standartą, daugiausia dėmesio skiriant optimizavimo įterpimui išankstinio mokymo metu. Šiuo tyrimu siekiama išspręsti esamų mokymo metodų spragą, įvedant į viziją orientuotą perspektyvą, siekiant pagerinti vizualinių vaizdų kokybę. Siūlomas metodas pagerina vizijos kalbos užduočių našumą ir tai pasiekiama naudojant mažiau skaičiavimo išteklių, palyginti su esamais metodais. OLA-VLM parodo, kaip tikslingas optimizavimas išankstinio mokymo metu gali žymiai pagerinti daugiarūšio modelio veikimą.
Apibendrinant galima pasakyti, kad „SHI Labs“ ir „Microsoft Research“ atliktas tyrimas pabrėžia novatorišką multimodalinio AI pažangą. Optimizuodamas vaizdinius vaizdus MLLM, OLA-VLM užpildo kritinę našumo ir efektyvumo spragą. Šis metodas parodo, kaip įterpiant optimizavimą galima veiksmingai spręsti vizijos ir kalbos derinimo problemas, atveriant kelią tvirtesnėms ir keičiamo dydžio daugiarūšėms sistemoms ateityje.
Patikrinkite į Popierius ir „GitHub“ puslapis. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Nikhilas yra „Marktechpost“ konsultantas. Indijos technologijos institute Charagpūre jis siekia integruoto dvigubo medžiagų studijų laipsnio. Nikhilas yra AI / ML entuziastas, kuris visada tiria pritaikymą tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagų mokslo išsilavinimą, jis tyrinėja naujus pasiekimus ir kuria galimybes prisidėti.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)




