

LLM vertinimas atliekant medicinines užduotis tradiciškai buvo pagrįstas daugelio atsakymų klausimų etalonais. Tačiau šie etalonai yra ribotos apimties, dažnai duoda prisotintus rezultatus, pasikartojančius didelius LLM rezultatus, ir tiksliai neatspindi realaus pasaulio klinikinių scenarijų. Klinikinis samprotavimas, kognityvinis procesas, kurį gydytojai naudoja analizuodami ir sintezuodami medicininius duomenis diagnozei ir gydymui, yra prasmingesnis etalonas vertinant modelio veikimą. Naujausi LLM įrodė, kad gali pranokti gydytojus atliekant įprastines ir sudėtingas diagnostikos užduotis, pranokstančias ankstesnes AI pagrįstas diagnostikos priemones, kuriose buvo naudojami regresijos modeliai, Bajeso metodai ir taisyklėmis pagrįstos sistemos.
LLM pažanga, įskaitant pagrindinius modelius, gerokai aplenkė medicinos specialistus pagal diagnostikos etalonus, o tokios strategijos kaip CoT paskatino dar labiau pagerinti jų mąstymo gebėjimus. „OpenAI“ o1 peržiūros modelis, pristatytas 2024 m. rugsėjį, integruoja įprastą CoT mechanizmą, leidžiantį labiau apgalvoti sudėtingas problemų sprendimo užduotis. Šis modelis pranoko GPT-4 sprendžiant sudėtingas problemas, tokias kaip informatika ir medicina. Nepaisant šių pažangų, kelių pasirinkimų etalonai nesugeba užfiksuoti klinikinių sprendimų priėmimo sudėtingumo, nes jie dažnai leidžia modeliams panaudoti semantinius modelius, o ne tikrą samprotavimą. Reali klinikinė praktika reikalauja dinamiško, daugiapakopio samprotavimo, kai modeliai turi nuolat apdoroti ir integruoti įvairius duomenų šaltinius, patikslinti diferencines diagnozes ir priimti svarbius sprendimus esant neapibrėžtumui.
Mokslininkai iš pirmaujančių institucijų, įskaitant Beth Israel Deaconess medicinos centrą, Stanfordo universitetą ir Harvardo medicinos mokyklą, atliko tyrimą, siekdami įvertinti OpenAI o1 peržiūros modelį, skirtą patobulinti samprotavimus per minčių grandinės procesus. Modelis buvo išbandytas atliekant penkias užduotis: diferencinės diagnozės generavimas, samprotavimų paaiškinimas, triažo diagnozė, tikimybinis samprotavimas ir valdymo samprotavimas. Gydytojai ekspertai įvertino modelio rezultatus naudodami patvirtintas metrikas ir palygino juos su ankstesniais LLM ir žmogaus etalonais. Rezultatai parodė reikšmingą diagnostikos ir valdymo samprotavimų pagerėjimą, tačiau tikimybinio samprotavimo ar skirstymo pažangos nepagerėjo. Tyrimas pabrėžia, kad norint įvertinti LLM galimybes klinikinėje aplinkoje, reikia tvirtų etalonų ir realaus pasaulio tyrimų.
Tyrime buvo įvertintas OpenAI o1 peržiūros modelis naudojant įvairius medicininės diagnostikos atvejus, įskaitant NEJM Clinicopathologic Conference (CPC) atvejus, NEJM Healer atvejus, pilkųjų medžiagų valdymo atvejus, svarbius diagnostikos atvejus ir tikimybines samprotavimo užduotis. Rezultatai buvo skirti diferencinės diagnostikos kokybei, testavimo planams, klinikinių motyvų dokumentacijai ir kritinių diagnozių nustatymui. Gydytojai įvertino balus naudodami patvirtintas metrikas, tokias kaip Bondo balai, R-IDEA ir normalizuotos rubrikos. Modelio našumas buvo lyginamas su istoriniais GPT-4 valdikliais, žmogaus etalonais ir papildomais ištekliais. Statistinė analizė, įskaitant McNemaro testą ir mišraus poveikio modelius, buvo atlikta R. Rezultatai išryškino o1-preview pranašumus, tačiau nustatė tokias sritis kaip tikimybinis samprotavimas, kurį reikia tobulinti.
Tyrimo metu buvo įvertintos o1-preview diagnostikos galimybės naudojant New England Journal of Medicine (NEJM) atvejus ir palygintos su GPT-4 ir gydytojais. o1 peržiūra teisingai įtraukė diagnozę 78,3 % NEJM atvejų, pranokdama GPT-4 (88,6 % ir 72,9 %). Jis pasiekė aukštą testo atrankos tikslumą (87,5 %) ir puikiai įvertino klinikinius argumentus (R-IDEA) 78/80 NEJM Healer atvejų, pranokdamas GPT-4 ir gydytojus. Valdymo vinjetėse „o1-preview“ viršijo GPT-4 ir gydytojų rezultatus daugiau nei 40%. Jis pasiekė 97% reikšmingų diagnostinių atvejų vidutinį balą, palyginti su GPT-4, bet aukštesnis nei gydytojų. Tikimybinis samprotavimas buvo atliktas panašiai kaip GPT -4, su didesniu tikslumu atliekant koronarinius testus.
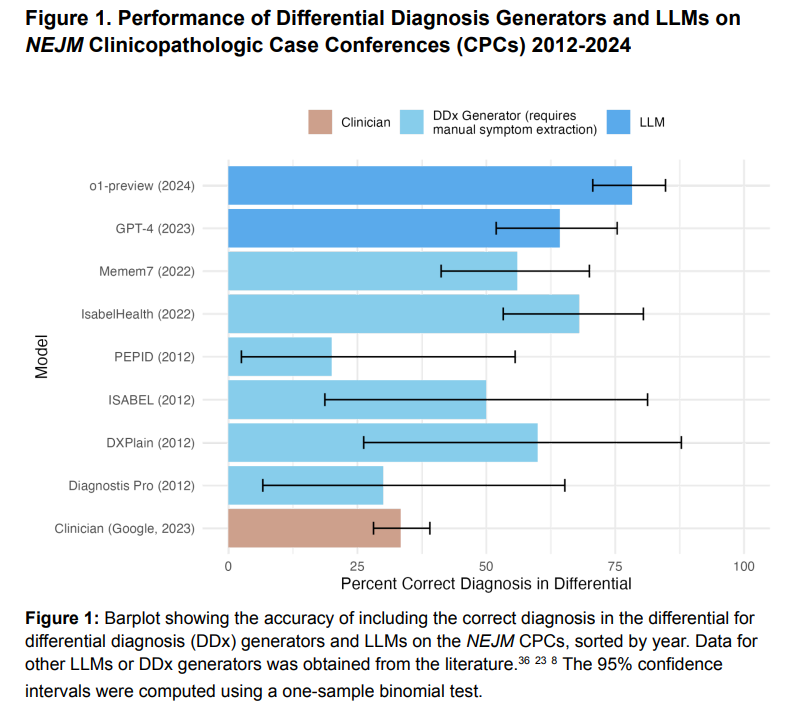
Apibendrinant galima pasakyti, kad o1 peržiūros modelis parodė puikų medicininį samprotavimą per penkis eksperimentus, pranokdamas GPT-4 ir žmogaus pradinius lygius atliekant tokias užduotis kaip diferencinė diagnozė, diagnostikos samprotavimai ir valdymo sprendimai. Tačiau tai neparodė reikšmingo pagerėjimo, palyginti su GPT-4, tikimybinio samprotavimo ar kritinės diagnozės nustatymo srityje. Tai pabrėžia LLM potencialą palaikant klinikinius sprendimus, nors norint patvirtinti jų integraciją į pacientų priežiūrą, būtini realaus pasaulio tyrimai. Dabartiniai etalonai, tokie kaip NEJM MUP, artėja prie prisotinimo, todėl reikia atlikti realistiškesnius ir sudėtingesnius vertinimus. Apribojimai apima daugžodiškumą, žmogaus ir kompiuterio sąveikos tyrimų trūkumą ir susitelkimą į vidaus ligą, pabrėždami platesnių vertinimų poreikį.
Patikrinkite į Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)





