

Įsivaizduokite, kad turite asmeninį pokalbių robotą, kuris gali atsakyti į klausimus tiesiai iš jūsų dokumentų, nesvarbu, ar tai būtų PDF, mokslinių darbų ar knygų. Naudojant „Retrieval-Augmented Generation“ (RAG), tai ne tik įmanoma, bet ir nesudėtinga įgyvendinti. Šioje pamokoje sužinosime, kaip sukurti pokalbių robotą, kuris sąveikauja su dokumentais, pvz., PDF, naudojant Retrieval-Augmented Generation (RAG). Mes naudosime Groq kalbos modelio išvadai, Chroma kaip vektorių saugykla ir Gradio vartotojo sąsajai.
Galų gale turėsite pokalbių robotą, galintį atsakyti į klausimus tiesiai iš jūsų dokumentų, išlaikyti pokalbio kontekstą ir pateikti glaustus, tikslius atsakymus.
Kas yra paieškos papildyta karta (RAG)?
Retrieval-Augmented Generation (RAG) yra AI architektūra, kuri padidina didelių kalbų modelių (LLM) galimybes integruodama informacijos paieškos sistemą. Ši sistema gauna atitinkamus duomenis iš išorinių šaltinių, suteikdama LLM pagrįstą informaciją, kad būtų galima sukurti tikslesnius ir kontekstui tinkamus atsakymus. Sujungus LLM generatyvius gebėjimus su duomenų gavimu realiuoju laiku, RAG sumažina netikslumus ir užtikrina naujausią AI sukurto turinio informaciją.
Būtinos sąlygos
- Python diegimas: Įsitikinkite, kad jūsų sistemoje įdiegta Python 3.9+.
- Groq API raktas: Prisiregistruokite gauti Groq paskyrą ir sugeneruokite API raktą:
- Apsilankykite „Groq Console“.
- Eikite į API raktai ir sukurti naują raktą.
- Nukopijuokite savo API raktą, kad galėtumėte naudoti projekte.
Priklausomybės: Įdiekite reikiamas bibliotekas:
pip install langchain langchain-community langchain-groq gradio sentence-transformers PyPDF2 chromadbŠios bibliotekos padės apdoroti kalbą, kurti vartotojo sąsają, integruoti modelius, tvarkyti PDF ir valdyti vektorines duomenų bazes.
Atsisiunčiamas PDF šaltinis
Šiai mokymo programai naudosime viešai prieinamą PDF failą, kuriame yra informacijos apie ligas, jų simptomus ir gydymą. Atsisiųskite PDF ir išsaugokite jį savo projekto kataloge (galite laisvai naudoti bet kurį pdf).
1 veiksmas: teksto ištraukimas iš PDF
Naudosime PyPDF2, kad ištrauktume tekstą iš PDF:
from PyPDF2 import PdfReader
def extract_text_from_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
pdf_path="diseases.pdf" # Replace with your PDF path
pdf_text = extract_text_from_pdf(pdf_path)2 veiksmas: padalinkite tekstą į dalis
Ilgi dokumentai yra suskirstyti į mažesnius, tvarkomus gabalus, kad būtų galima apdoroti.
from langchain.text_splitter import RecursiveCharacterTextSplitter
def split_text_into_chunks(text, chunk_size=2000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
return text_splitter.split_text(text)
text_chunks = split_text_into_chunks(pdf_text)3 veiksmas: sukurkite vektorinę parduotuvę naudodami „Chroma“.
Įterpsime teksto dalis naudodami iš anksto paruoštą modelį ir išsaugosime juos a Chroma vektorinė duomenų bazė.
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
embedding_model = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(
collection_name="disease_info",
embedding_function=embedding_model,
persist_directory="./chroma_db"
)
vector_store.add_texts(texts=text_chunks)4 veiksmas: inicijuokite Groq kalbos modelį
Norėdami naudoti Groq kalbos modelį, nustatykite API raktą ir inicijuokite ChatGroq pavyzdys.
import os
from langchain_groq import ChatGroq
os.environ("GROQ_API_KEY") = 'your_groq_api_key_here' # Replace with your API key
llm = ChatGroq(model="mixtral-8x7b-32768", temperature=0.1)5 veiksmas: sukurkite pokalbių paieškos grandinę
Su LangChain's ConversationalRetrievalChaingalime susieti kalbos modelį ir vektorinę duomenų bazę.
from langchain.chains import ConversationalRetrievalChain
retrieval_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vector_store.as_retriever(topk=3),
return_source_documents=True
)6 veiksmas: įdiekite „Chatbot“ logiką
Mes nustatome pokalbių istorijos tvarkymo ir atsakymų generavimo logiką.
conversation_history = ()
def get_response(user_query):
response = retrieval_chain({
"question": user_query,
"chat_history": conversation_history
})
conversation_history.append((user_query, response('answer')))
return response('answer')7 veiksmas: sukurkite vartotojo sąsają naudodami „Gradio“.
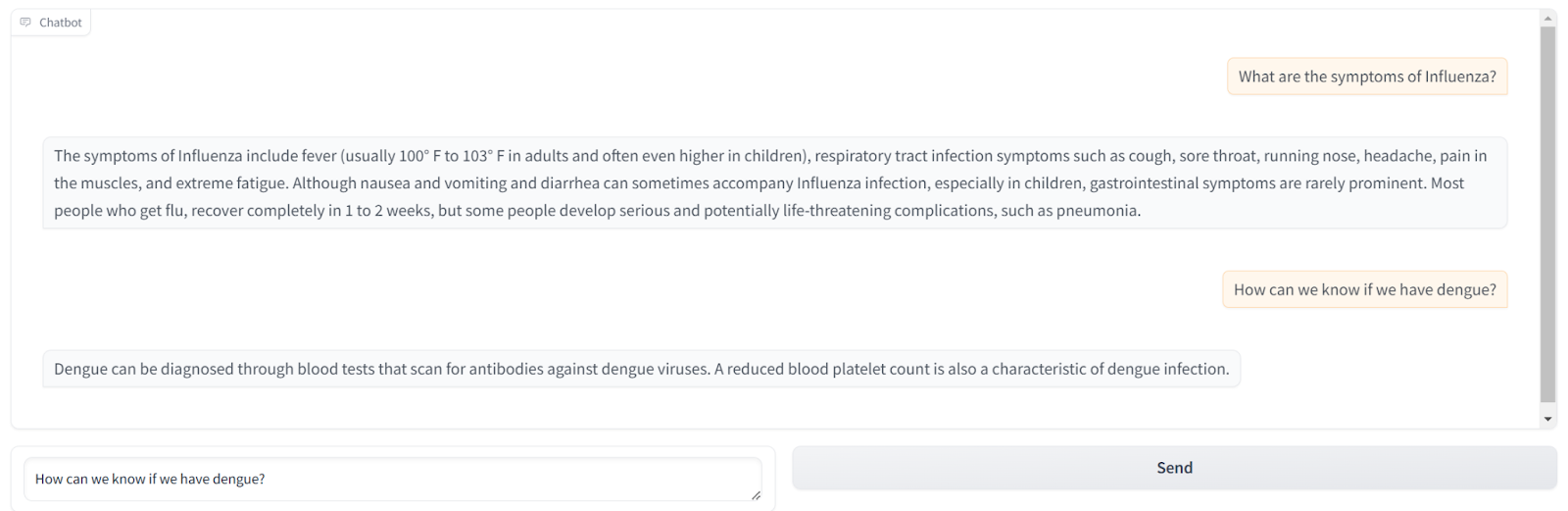
Galiausiai sukurkite Gradio sąsają, kad galėtumėte bendrauti su pokalbių robotu.
import gradio as gr
def chat_interface(user_input, history):
response = get_response(user_input)
history.append((user_input, response))
return history, history
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
state = gr.State(())
with gr.Row():
user_input = gr.Textbox(show_label=False, placeholder="Enter your question...")
submit_btn = gr.Button("Send")
submit_btn.click(chat_interface, inputs=(user_input, state), outputs=(chatbot, state))
Kodo vykdymas
Išsaugokite scenarijų kaip app.py ir bėgti
python app.pyHurray! Jūs baigėte. Bus paleista Gradio sąsaja, leidžianti kalbėtis su dokumentu.
Bet kam čia sustoti? Galite eiti toliau, bandydami sukurti bet kurią iš šių pokalbių roboto funkcijų.
- Patobulinta vektorių parduotuvė: Norėdami padidinti mastelį, naudokite kitas vektorines duomenų bazes, pvz., Milvus arba Pinecone.
- Tiksliai sureguliuoti modeliai: Eksperimentuokite su tiksliai suderintais Groq modeliais, kad pasiektumėte domeno tikslumą.
- Kelių dokumentų palaikymas: Išplėskite sistemą, kad galėtumėte tvarkyti kelis dokumentus.
- Geresnis konteksto valdymas: Patikslinkite pokalbių logiką, kad galėtumėte geriau valdyti ilgesnes pokalbių istorijas.
- Tinkinta vartotojo sąsaja: Sukurkite tobulesnę vartotojo sąsają su pažangiu stiliumi ir funkcijomis.
Sveikiname! Sėkmingai sukūrėte dokumentais pagrįstą pokalbių robotą naudodami Groq ir LangChain. Eksperimentuokite su patobulinimais ir sukurkite ką nors nuostabaus! 🚀
Ištekliai:
- https://nios.ac.in/media/documents/SrSec314NewE/Lesson-29.pdf
- LangChain (https://www.langchain.com/)
- Groq (https://groq.com/)
Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 65k+ ML SubReddit.
🚨 Rekomenduokite atvirojo kodo platformą: „Parlant“ yra sistema, pakeičianti tai, kaip dirbtinio intelekto agentai priima sprendimus klientams skirtuose scenarijuose. (Paaukštintas)
Vineet Kumar yra „MarktechPost“ konsultacinė praktikantė. Šiuo metu jis baigia bakalauro laipsnį Indijos technologijos institute (IIT), Kanpūre. Jis yra mašininio mokymosi entuziastas. Jis aistringai vertina mokslinius tyrimus ir naujausius pasiekimus giluminio mokymosi, kompiuterinės vizijos ir susijusiose srityse.
📄 Susipažinkite su „Aukštis”: vienintelis savarankiškas projektų valdymo įrankis (remiama)




