

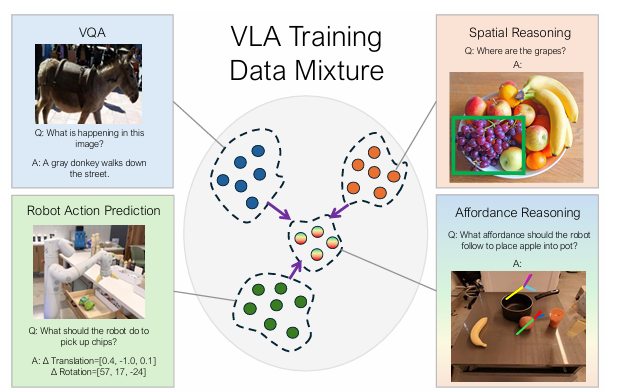
Pastaraisiais metais buvo padaryta didelė pažanga didelių iš anksto parengtų robotų politikos mokymosi modelių srityje. Terminas „politikos atstovavimas“ čia reiškia skirtingus sąsajos su robotų sprendimų priėmimo mechanizmais būdus, kurie gali palengvinti apibendrinimą naujoms užduotims ir aplinkoms. Vizija-kalba-veiksmas (VLA) modeliai yra iš anksto apmokyti naudojant didelio masto robotų duomenis, kad būtų galima integruoti vizualinį suvokimą, kalbos supratimą ir veiksmais pagrįstą sprendimų priėmimą, kad būtų galima vadovauti robotams atliekant įvairias užduotis. Ant viršaus vizijos kalbos modeliai (VLM)jie žada apibendrinti naujus objektus, scenas ir užduotis. Tačiau VLA vis tiek turi būti patikimesni, kad būtų naudojami už siaurų laboratorijų nustatymų, kuriuose jie mokomi. Nors šiuos trūkumus galima sušvelninti plečiant robotų duomenų rinkinių apimtį ir įvairovę, tai reikalauja daug išteklių ir sudėtinga. Paprastais žodžiais tariant, šios politikos nuostatos turi pateikti daugiau konteksto arba per daug apibrėžtą kontekstą, kuris duoda ne tokią patikimą politiką.
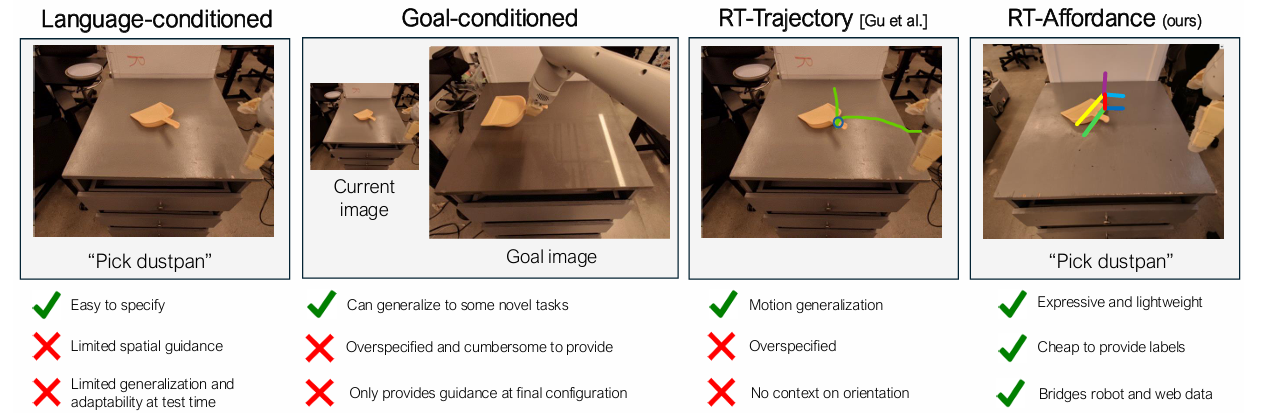
Esamos politikos atstovybės, tokios kaip kalba, tikslo vaizdaiir trajektorijos eskizai yra plačiai naudojami ir yra naudingi. Vienas iš labiausiai paplitusių politikos vaizdų yra kalbos sąlygojimas. Dauguma robotų duomenų rinkinių pažymėti nepakankamai tiksliais užduoties aprašymais, o kalbomis pagrįstos instrukcijos nepateikia pakankamai nurodymų, kaip atlikti užduotį. Tikslo vaizdo sąlygojamoje politikoje pateikiama išsami erdvinė informacija apie galutinę scenos tikslo konfigūraciją. Tačiau tikslo vaizdai yra didelės apimties, o tai kelia mokymosi iššūkių dėl pernelyg didelių specifikacijų. Tarpinis vaizdavimas, pvz., trajektorijos eskizai arba pagrindiniai taškai, kuriais bandoma pateikti erdvinius planus, kuriais vadovaujantis roboto veiksmai. Nors šiuose erdviniuose planuose pateikiamos gairės, juose vis dar trūksta pakankamai informacijos apie konkrečių judėjimų atlikimo politiką.

„Google DeepMind“ tyrėjų komanda atliko išsamų robotų politikos atstovavimo tyrimą ir pasiūlė RT-Affordance Tai yra hierarchinis modelis, kuris pirmiausia sukuria pelningumo planą, atsižvelgiant į užduoties kalbą, o tada naudoja šio pelno plano politiką, kad vadovautų roboto manipuliavimo veiksmams. Robotikoje, pasitenkinimą reiškia galimą sąveiką, kurią objektas įgalina robotui, atsižvelgiant į jo formą, dydį ir kt RT-Affordance modelis gali lengvai sujungti nevienalyčius priežiūros šaltinius, įskaitant didelius žiniatinklio duomenų rinkinius ir robotų trajektorijas.
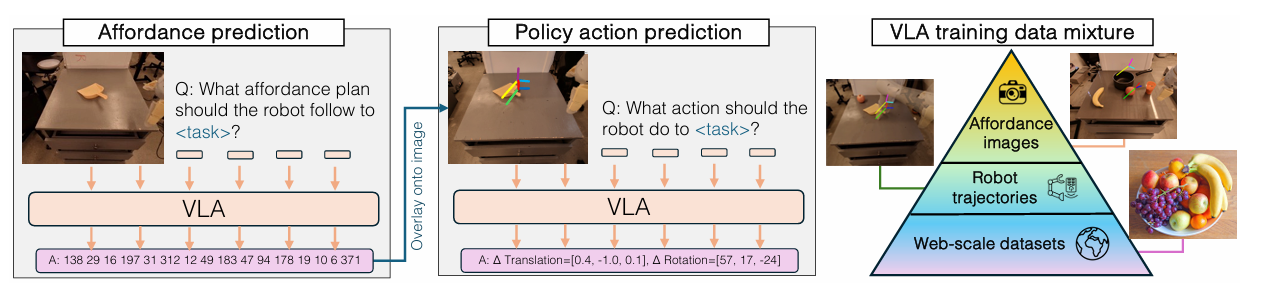
Pirma, numatomas finansavimo planas duotai užduoties kalbai ir pradiniam užduoties įvaizdžiui. Tada šis pelno planas derinamas su kalbinėmis instrukcijomis, kad būtų nustatyta užduoties vykdymo politika. Tada jis projektuojamas ant atvaizdo, o po to politika priklauso nuo vaizdų, padengtų pelno planu. Modelis yra apmokytas žiniatinklio duomenų rinkiniuose (didžiausias duomenų šaltinis), roboto trajektorijos ir nedidelis skaičius pigių vaizdų, pažymėtų affordances. Šis metodas naudingas tuo, kad naudojami roboto trajektorijos duomenys ir dideli žiniatinklio duomenų rinkiniai, todėl modelis gali gerai apibendrinti naujus objektus, scenas ir užduotis.
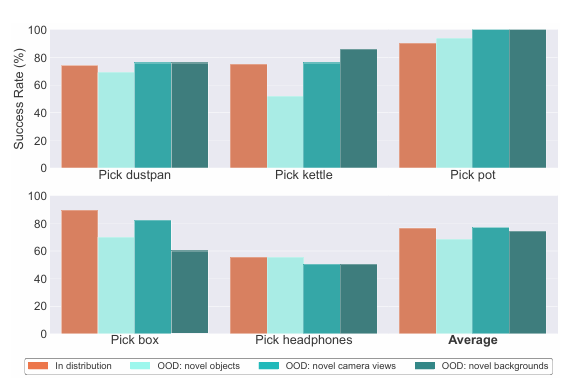
Tyrėjų grupė atliko įvairius eksperimentus, kurių pagrindinis dėmesys buvo skiriamas tam, kaip išlaidos padeda pagerinti robotų sugriebimą, ypač judant sudėtingų formų namų apyvokos daiktus (pvz., virdulius, šiukšliadėžes ir puodus). Išsamus įvertinimas tai parodė RT-A išlieka tvirtas įvairiose srityse neplatinamas (OOD) scenarijai, tokie kaip nauji objektai, kameros kampai ir fonai. RT-A modelis veikė geriau nei RT-2 ir jos tikslo sąlygotas variantas, pasiekiantis sėkmės rodiklius 68–76 % palyginti su RT-2 24–28 proc. Atliekant užduotis, kurių negalima suvokti, pvz., dėti objektus į konteinerius, RT-A parodė reikšmingą našumą 70 % sėkmės rodiklis. Tačiau RT-A našumas šiek tiek sumažėjo, kai susidūrė su visiškai naujais objektais.
Apibendrinant galima pasakyti, kad įperkama politika yra gerai valdoma ir taip pat veikia geriau. RT-Affordance metodas žymiai pagerina roboto politikos patikimumą ir apibendrinimą, todėl jis yra vertingas įrankis įvairioms manipuliavimo užduotims atlikti. Nors ir negali prisitaikyti prie visiškai naujų akimirkų ar įgūdžių, RT-Affordance savo našumu pranoksta tradicinius metodus. Ši pasitenkinimo technika atveria vartus įvairioms būsimoms robotikos tyrimų galimybėms ir gali būti pagrindas būsimoms studijoms!
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Rėmimo galimybė su mumis) Reklamuokite savo tyrimą / produktą / internetinį seminarą su 1 milijonu ir daugiau skaitytojų per mėnesį ir daugiau nei 500 000 bendruomenės narių
Divyesh yra „Marktechpost“ konsultavimo praktikantas. Jis siekia žemės ūkio ir maisto inžinerijos bakalauro laipsnio Indijos technologijos institute Kharagpur. Jis yra duomenų mokslo ir mašininio mokymosi entuziastas, norintis integruoti šias pirmaujančias technologijas į žemės ūkio sritį ir spręsti iššūkius.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️





