

Daugiarūšių kalbų modeliai (OLM) yra sparčiai besivystanti AI sritis, leidžianti suprasti ir mąstyti apie kelių tipų duomenis, įskaitant tekstą, garsą, vaizdo įrašus ir vaizdus. Šiais modeliais siekiama imituoti į žmogų panašų supratimą vienu metu apdorojant įvairias įvestis, todėl jie yra labai naudingi sudėtingose realaus pasaulio programose. Šios srities tyrimais siekiama sukurti AI sistemas, kurios galėtų sklandžiai integruoti šiuos įvairius duomenų tipus ir generuoti tikslius atsakymus atliekant įvairias užduotis. Tai rodo šuolį į priekį, kaip dirbtinio intelekto sistemos sąveikauja su pasauliu, todėl jos labiau suderinamos su žmonių bendravimu, kai informacija retai apsiriboja vienu būdu.
Nuolatinis iššūkis kuriant OLM yra nenuoseklus jų veikimas, kai susiduriama su multimodaliniais įvestimis. Pavyzdžiui, modeliui gali reikėti analizuoti duomenis, kuriuose yra teksto, vaizdų ir garso, kad galėtų atlikti užduotį realiose situacijose. Tačiau daugeliui dabartinių modelių reikia pagalbos efektyviai derinant šias įvestis. Pagrindinė problema yra ta, kad šios sistemos nesugeba visapusiškai samprotauti įvairiais būdais, o tai lemia jų rezultatų neatitikimus. Daugeliu atvejų modeliai pateikia skirtingus atsakymus, kai pateikiama ta pati informacija įvairiais formatais, pvz., matematinė problema, rodoma kaip vaizdas, o ne garsiai ištartas kaip garsas.
Esami OLM etalonai dažnai apsiriboja paprastais dviejų būdų, tokių kaip tekstas ir vaizdai arba vaizdo įrašas ir tekstas, deriniais. Šiuose vertinimuose turi būti įvertintos visos galimybės, reikalingos realaus pasaulio programoms, dažnai apimančioms sudėtingesnius scenarijus. Pavyzdžiui, daugelis dabartinių modelių gerai veikia atliekant dvigubo modalumo užduotis. Vis dėlto jie turi gerokai patobulinti, kai prašoma pagrįsti trijų ar daugiau būdų derinius, pvz., integruoti vaizdo įrašą, tekstą ir garsą, kad būtų gautas sprendimas. Šis apribojimas sukuria spragą vertinant, kaip šie modeliai iš tikrųjų supranta ir pagrįstai naudoja kelių tipų duomenis.
Sukūrė „Google DeepMind“, „Google“ ir Merilendo universiteto mokslininkai Omni×Rnauja vertinimo sistema, skirta griežtai išbandyti OLM argumentavimo galimybes. Ši sistema išsiskiria tuo, kad įveda sudėtingesnius multimodalinius iššūkius. „Omni×R“ vertina modelius, naudodamas scenarijus, kai jie turi integruoti kelių formų duomenis, pvz., atsakyti į klausimus, kuriuos reikia pagrįsti tekste, vaizdais ir garsu vienu metu. Sistema apima du duomenų rinkinius:
- Omni×Rsynth yra sintetinis duomenų rinkinys, sukurtas automatiškai konvertuojant tekstą į kitus būdus.
- Omni×Rreal yra realaus pasaulio duomenų rinkinys, kruopščiai kuruojamas iš tokių šaltinių kaip „YouTube“.
Šie duomenų rinkiniai suteikia išsamesnę ir sudėtingesnę bandymo aplinką nei ankstesni etalonai.
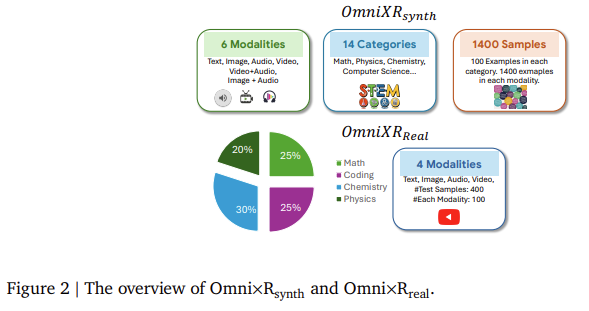
Omni×Rsynth, sintetinis sistemos komponentas, skirtas modeliams išstumti iki jų ribų, paverčiant tekstą vaizdais, vaizdo įrašais ir garsu. Pavyzdžiui, tyrėjų komanda sukūrė „Omnify!“ – įrankį tekstui paversti įvairiais būdais, sukurdama 1400 pavyzdžių duomenų rinkinį, paskirstytą šešiose kategorijose, įskaitant matematiką, fiziką, chemiją ir kompiuterių mokslą. Kiekvienoje kategorijoje yra 100 pavyzdžių, skirtų šešiems variantams: tekstas, vaizdas, vaizdo įrašas, garsas, vaizdo įrašas + garsas ir vaizdas + garsas, o tai yra sudėtingi modeliai, skirti valdyti sudėtingus įvesties derinius. Tyrėjai naudojo šį duomenų rinkinį norėdami išbandyti įvairius OLM, įskaitant Gemini 1.5 Pro ir GPT-4o. Šių testų rezultatai atskleidė, kad dabartinių modelių našumas smarkiai sumažėja, kai prašoma integruoti informaciją iš skirtingų būdų.
Omni×Rreal, realaus pasaulio duomenų rinkinys, apima 100 vaizdo įrašų, apimančių tokias temas kaip matematika ir mokslas, kur klausimai pateikiami skirtingais būdais. Pavyzdžiui, vaizdo įraše matematinė problema gali būti rodoma vizualiai, o atsakymo variantai ištariami garsiai, todėl modelis turi integruoti vaizdinę ir garsinę informaciją, kad išspręstų problemą. Realaus pasaulio scenarijai dar labiau išryškino modelių sunkumus samprotaujant įvairiais būdais, nes rezultatai parodė neatitikimus, panašius į tuos, kurie buvo pastebėti sintetiniame duomenų rinkinyje. Pažymėtina, kad modelių, kurie gerai veikė naudojant teksto įvestį, tikslumas smarkiai sumažėjo, kai jiems buvo pavesta naudoti vaizdo ar garso įvestį.

Tyrimo grupė atliko išsamius eksperimentus ir rado keletą pagrindinių įžvalgų. Pavyzdžiui, „Gemini 1.5 Pro“ modelis veikė gerai naudojant daugumą būdų, o teksto samprotavimo tikslumas buvo 77,5%. Tačiau jo našumas sumažėjo iki 57,3% vaizdo įrašų ir 36,3% vaizdo įvestyje. Priešingai, GPT-4o pademonstravo geresnius rezultatus tvarkydamas teksto ir vaizdo užduotis, tačiau susidūrė su vaizdo įrašais, o našumas sumažėjo 20 %, kai buvo pavesta integruoti teksto ir vaizdo duomenis. Tai pabrėžia iššūkius, kylančius siekiant nuoseklaus našumo įvairiais būdais, o tai yra esminis žingsnis siekiant tobulinti OLM galimybes.
Omni×R etalono rezultatai atskleidė keletą pastebimų tendencijų skirtinguose OLM. Vienas iš svarbiausių pastebėjimų buvo tai, kad net pažangiausi modeliai, tokie kaip Gemini ir GPT-4o, labai skyrė savo mąstymo gebėjimus įvairiais būdais. Pavyzdžiui, Gemini modelis apdorojant garsą pasiekė 65% tikslumą, tačiau derinant vaizdo ir garso duomenis jo našumas nukrito iki 25,9%. Panašiai, GPT-4o-mini modelis, nepaisant puikiai atlikdamas tekstines užduotis, susidūrė su vaizdo įrašais ir parodė 41 % našumo atotrūkį, palyginti su tekstinėmis užduotimis. Šie neatitikimai rodo, kad reikia atlikti tolesnius tyrimus ir plėtrą, kad būtų užpildyta įvairių transporto rūšių samprotavimo galimybių spraga.
Omni×R etalono išvados rodo keletą pagrindinių dalykų, kurie pabrėžia dabartinius OLM tyrimų apribojimus ir ateities kryptis:
- Tokie modeliai kaip „Gemini“ ir „GPT-4o“ puikiai veikia su tekstu, tačiau susiduria su daugiarūšiu samprotavimu.
- Egzistuoja didelis našumo atotrūkis tarp teksto įvesties apdorojimo ir sudėtingų daugiarūšių užduočių, ypač kai naudojamas vaizdo ar garso įrašas.
- Didesni modeliai paprastai veikia geriau įvairiais būdais, tačiau mažesni modeliai kartais gali pranokti juos atliekant tam tikras užduotis, parodydami modelio dydžio ir lankstumo kompromisą.
- Sintetinis duomenų rinkinys (Omni×Rsynth) tiksliai imituoja realaus pasaulio iššūkius, todėl tai yra vertinga priemonė kuriant modelį ateityje.

Apibendrinant galima pasakyti, kad „Omni×R“ sistema, kurią pristatė tyrimų grupė, yra svarbus žingsnis į priekį vertinant ir tobulinant OLM argumentavimo galimybes. Griežtai išbandydamas įvairių modelių modelius, tyrimas atskleidė didelių iššūkių, kuriuos reikia spręsti, norint sukurti dirbtinio intelekto sistemas, galinčias mąstyti panašiai kaip multimodalinis mąstymas. Našumo sumažėjimas, pastebimas atliekant užduotis, susijusias su vaizdo ir garso integravimu, išryškina įvairiarūšio mąstymo sudėtingumą ir rodo, kad reikia pažangesnių mokymo metodų ir modelių, kad būtų galima valdyti realaus pasaulio daugiarūšių duomenų sudėtingumą.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 50 000+ ML SubReddit.
(Būsimas tiesioginis internetinis seminaras – 2024 m. spalio 29 d.) Geriausia platforma, skirta tiksliai suderintiems modeliams aptarnauti: „Predibase Inference Engine“ (reklamuojama)
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️





