

Kuriant kalbos modeliavimą pagrindinis dėmesys skiriamas dirbtinio intelekto sistemų kūrimui, kurios gali apdoroti ir generuoti tekstą sklandžiai, kaip žmogus. Šie modeliai atlieka svarbų vaidmenį mašininio vertimo, turinio generavimo ir pokalbio AI programose. Jie remiasi plačiais duomenų rinkiniais ir sudėtingais mokymo algoritmais, kad išmoktų kalbinius modelius, leidžia jiems suprasti kontekstą, atsakyti į užklausas ir kurti nuoseklų tekstą. Sparti šios srities raida pabrėžia didėjančią atvirojo kodo įnašų, kuriais siekiama demokratizuoti prieigą prie galingų AI sistemų, svarbą.
Nuolatinė problema šioje srityje buvo patentuotų modelių dominavimas, kurie dažnai pranoksta atvirojo kodo sistemas dėl savo didelių išteklių ir optimizuotų mokymo vamzdynų. Patentuotos sistemos dažnai naudoja didžiulius duomenų rinkinius, skaičiavimo galią ir pažangias patentuotas metodikas, sukurdamos našumo spragą, kurią reikia padėti užpildyti atviriems modeliams. Šis skirtumas riboja DI prieinamumą ir inovacijas, nes tik gerai finansuojamos organizacijos gali sau leisti kurti tokias pažangiausias technologijas.
Nors ir pagirtina, dabartiniai atvirojo kodo metodai vis tiek turi visiškai išspręsti mastelio, mokymo stabilumo ir modelio našumo iššūkius. Daugelis modelių yra arba iš dalies atviri, teikiantys tik ribotus duomenų rinkinius ar metodikas, arba visiškai atviri, tačiau jiems reikia konkurencinio pranašumo, palyginti su patentuotais analogais. Tačiau naujausi pažanga atveria kelią naujos kartos visiškai atviriems ir konkurencingiems modeliams.
Allen instituto AI tyrimų komanda pristatė OLMo 2novatoriška atvirojo kodo kalbų modelių šeima. Šie modeliai, kurių parametrų konfigūracija yra 7 milijardai (7B) ir 13 milijardų (13B), buvo išmokyti naudoti iki 5 trilijonų žetonų, naudojant naujausius metodus. Patobulindami treniruočių stabilumą, taikydami etapinius mokymo procesus ir įtraukdami įvairius duomenų rinkinius, tyrėjai sumažino veiklos spragą su patentuotomis sistemomis, tokiomis kaip Llama 3.1. OLMo 2 pagerina sluoksnių normalizavimą, sukamąjį padėties įterpimą ir Z praradimo reguliavimą, kad padidintų modelio tvirtumą.
OLMo 2 mokymuose buvo taikomas dviejų etapų mokymo programos metodas. Pirmajame etape, apimančiame 90 % išankstinio mokymo biudžeto, modeliai buvo apmokyti naudojant OLMo-Mix-1124 duomenų rinkinį, kurį sudaro 3,9 trilijono žetonų, gautų iš įvairių aukštos kokybės saugyklų, tokių kaip DCLM ir Starcoder. Antrasis etapas apėmė tobulą Dolmino-Mix-1124 – 843 milijardų žetonų kuruojamą duomenų rinkinį su žiniatinkliu ir domenui būdingu turiniu. Tokie metodai, kaip modelių keitimas, kuris sujungia kontrolinius taškus, kad optimizuotų našumą, buvo labai svarbūs kuriant galutines 7B ir 13B modelių versijas.
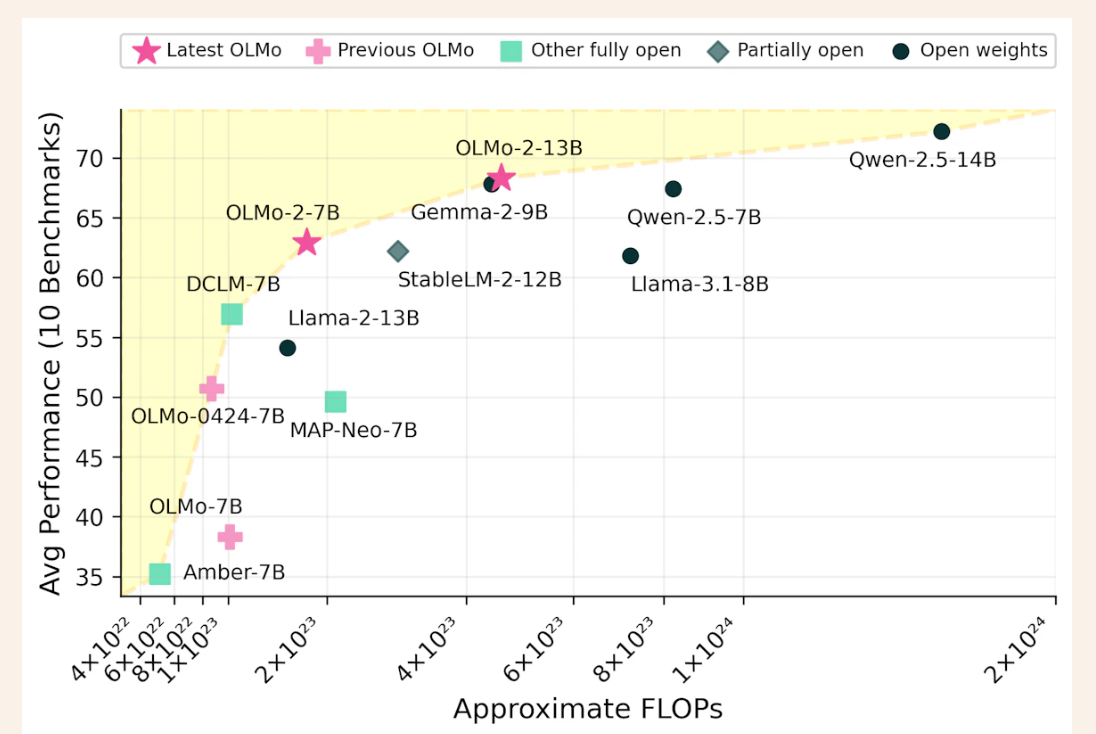
OLMo 2 našumas nustato naujus etalonus atvirojo kodo kalbų modeliavimo srityje. Palyginti su savo pirmtaku OLMo-0424, OLMo 2 demonstruoja didelį postūmį atliekant visas vertinimo užduotis. OLMo 2 7B žymiai lenkia Llama-3.1 8B, o OLMo 2 13B pranoksta Qwen 2.5 7B, nepaisant to, kad naudoja mažiau treniruočių FLOP. Vertinimas naudojant atvirosios kalbos modeliavimo vertinimo sistemą (OLMES), 20 etalonų rinkinį, patvirtino šiuos laimėjimus, išryškindamas žinių prisiminimo, samprotavimo ir bendrųjų kalbos gebėjimų pranašumus.
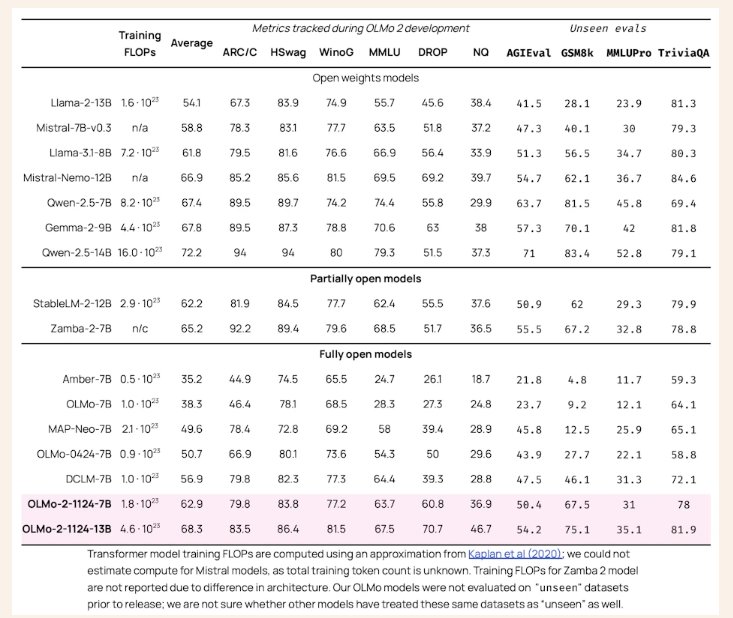
Pagrindiniai tyrimo rezultatai yra šie:
- Treniruočių stabilumo gerinimas: Metodai, tokie kaip RMSNorm ir mokymosi greičio atkaitinimas, sumažino nuostolių šuolius išankstinio treniruotės metu, užtikrindami nuoseklų modelio veikimą.
- Inovatyvus etapinis mokymas: Vėlyvos išankstinio mokymo intervencijos, įskaitant duomenų mokymo programos koregavimą, leido tikslingai tobulinti modelio galimybes.
- Veiksminga vertinimo sistema: OLMES įdiegimas suteikė struktūrizuotų etalonų, padedančių kurti modelius ir veiksmingai stebėti pažangą.
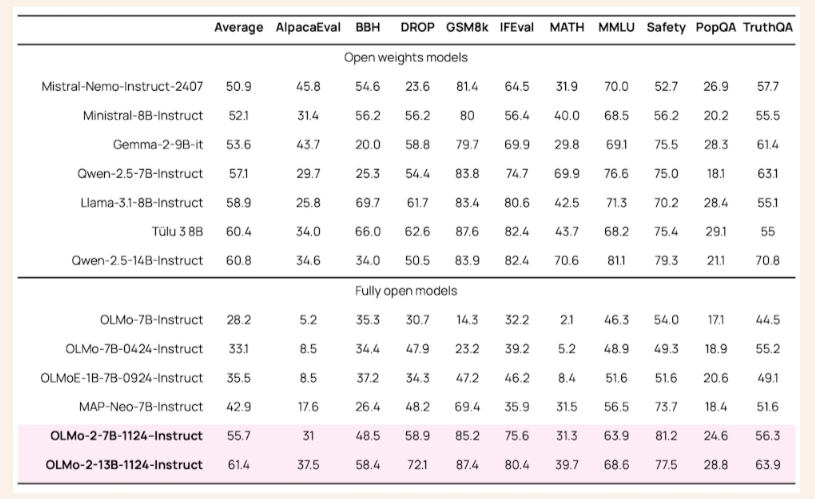
- Metodikos po mokymų: Prižiūrimas koregavimas, pirmenybių derinimas ir mokymasis sustiprino patikrinamą atlygį, pagerino modelių instrukcijų sekimo galimybes.
- Duomenų rinkinio įvairovė ir kokybė: Išankstinis mokymas apie duomenų rinkinius, tokius kaip Dolmino-Mix-1124, užtikrino, kad modeliai galėtų būti apibendrinti įvairiose srityse.

Apibendrinant galima pasakyti, kad „OLMo 2“ pasiekimai rodo kalbos modeliavimo kraštovaizdžio pasikeitimą. Spręsdami tokius iššūkius kaip mokymo stabilumas ir vertinimo skaidrumas, mokslininkai nustatė naują atvirojo kodo AI standartą. Šie modeliai panaikina atotrūkį nuo patentuotų sistemų ir parodo bendradarbiavimo naujovių potencialą tobulinant dirbtinį intelektą. OLMo 2 iniciatyva pabrėžia atviros prieigos prie didelio našumo AI modelių transformuojančią galią, atveriančią kelią teisingesnei technologinei pažangai.
Patikrinkite Modeliai su apsikabinusiu veidu ir detalėmis. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
🎙️ 🚨 „Didelių kalbos modelio pažeidžiamumų įvertinimas: lyginamoji raudonųjų komandų sudarymo metodų analizė“ Skaitykite visą ataskaitą (Paaukštintas)
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)





