

Adomas plačiai naudojamas giluminiame mokyme kaip adaptyvus optimizavimo algoritmas, tačiau jis kovoja su konvergencija, nebent hiperparametras β2 būtų pakoreguotas pagal konkrečią problemą. Bandant tai išspręsti, kaip ir AMSGrad, reikalinga nepraktiška prielaida apie vienodai ribojamą gradiento triukšmą, kuris negalioja Gauso triukšmo atvejais, kaip matyti iš variacinių autokoderių ir difuzijos modelių. Kiti metodai, pvz., „AdaShift“, sprendžia konvergenciją pagal ribotus scenarijus, tačiau nėra veiksmingi bendroms problemoms spręsti. Naujausi tyrimai rodo, kad Adomas gali konverguoti tiksliai nustatydamas β2 kiekvienai užduočiai, nors šis metodas yra sudėtingas ir būdingas konkrečiai problemai, todėl reikia toliau ieškoti universalių sprendimų.
Tyrėjai iš Tokijo universiteto pristatė ADOPT. Šiuo nauju adaptyvaus gradiento metodu pasiekiama optimali konvergencija esant O (1/√T) greičiui, nereikalaujant konkrečių β2 pasirinkimų arba riboto triukšmo prielaidos. ADOPT sprendžia Adamo nesuartėjimą, neįtraukdamas dabartinio gradiento iš antrojo momento įvertinimo ir koreguodamas impulso ir normalizavimo atnaujinimų tvarką. Eksperimentai su įvairiomis užduotimis, pvz., vaizdų klasifikavimu, generaciniu modeliavimu, kalbos apdorojimu ir mokymosi pastiprinimu, rodo, kad ADOPT yra pranašesnis už Adamą ir jo variantus. Šis metodas taip pat patikimai suderinamas sudėtingais atvejais, įskaitant scenarijus, kai Adamas ir AMSGrad kovoja.
Šiame tyrime pagrindinis dėmesys skiriamas tikslo funkcijos, kuri priklauso nuo parametro vektoriaus, sumažinimui, naudojant pirmos eilės stochastinio optimizavimo metodus. Užuot dirbę su tiksliu gradientu, jie remiasi įvertinimu, žinomu kaip stochastinis gradientas. Kadangi funkcija gali būti neišgaubta, tikslas yra rasti stacionarų tašką, kuriame gradientas yra lygus nuliui. Standartinės šios srities konvergencijos analizės paprastai daro keletą pagrindinių prielaidų: funkcija turi minimalią ribą, stochastinis gradientas suteikia nešališką gradiento įvertinimą, funkcija keičiasi sklandžiai, o stochastinio gradiento dispersija yra tolygiai ribojama. Naudojant adaptyviuosius metodus, tokius kaip Adamas, dažnai daroma papildoma prielaida apie gradiento dispersiją, siekiant supaprastinti konvergencijos įrodymus. Tyrėjai taiko prielaidų rinkinį, kad ištirtų, kaip prisitaikantys gradiento metodai susilieja, nesiremdami griežtesne prielaida, kad gradiento triukšmas išlieka ribotas.
Ankstesni tyrimai rodo, kad nors pagrindinis stochastinis gradiento nusileidimas dažnai susilieja neišgaubtuose nustatymuose, adaptyvūs gradiento metodai, tokie kaip Adamas, dėl savo lankstumo plačiai naudojami giliajame mokyme. Tačiau Adomui kartais reikia suartėti, ypač išgaubtais atvejais. Siekiant išspręsti šią problemą, buvo sukurta modifikuota versija, pavadinta AMSGrad, kuri įveda nemažėjantį mokymosi greičio mastelį, atnaujinant antrojo momento įvertį maksimalia funkcija. Vis dėlto AMSGrad konvergencija grindžiama stipresne tolygiai ribojamo gradiento triukšmo prielaida, kuri galioja ne visuose scenarijuose, pavyzdžiui, tam tikruose generatyviniuose modeliuose. Todėl mokslininkai siūlo naują adaptyvų gradiento atnaujinimo metodą, kuriuo siekiama užtikrinti patikimą konvergenciją, nesiremiant griežtomis prielaidomis apie gradiento triukšmą, sprendžiant Adamo apribojimus, susijusius su konvergencija ir optimizuojant parametrų priklausomybes.
ADOPT algoritmas vertinamas atliekant įvairias užduotis, siekiant patikrinti jo našumą ir tvirtumą, palyginti su Adam ir AMSGrad. Pradedant nuo žaislo problemos, ADOPT sėkmingai susilieja ten, kur Adam to nedaro, ypač esant aukšto gradiento triukšmo sąlygoms. Bandymai su MLP MNIST duomenų rinkinyje ir ResNet CIFAR-10 rodo, kad ADOPT pasiekia greitesnę ir stabilesnę konvergenciją. ADOPT taip pat lenkia Adamą tokiose programose kaip „Swin Transformer“ pagrįsta „ImageNet“ klasifikacija, NVAE generacinis modeliavimas ir GPT-2 išankstinis mokymas triukšmingo gradiento sąlygomis ir pagerina LLaMA-7B kalbos modelio derinimą pagal MMLU etaloną.
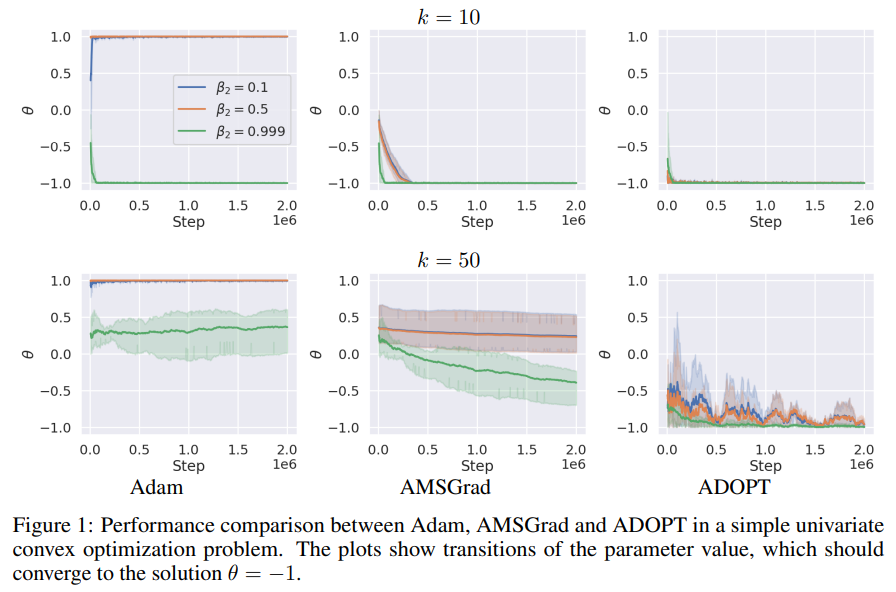
Tyrime nagrinėjami teoriniai adaptyvaus gradiento metodų, pvz., Adamo, apribojimai, kuriems reikia konverguoti specifinių hiperparametrų nustatymų. Norėdami tai išspręsti, autoriai pristato ADOPT – optimizavimo priemonę, kuri pasiekia optimalų konvergencijos greitį įvairiose užduotyse be konkrečių problemų derinimo. ADOPT įveikia Adamo apribojimus, pakeisdamas pagreitio atnaujinimo tvarką ir neįtraukdamas dabartinio gradiento į antrojo momento skaičiavimus, taip užtikrindamas stabilumą atliekant tokias užduotis kaip vaizdų klasifikavimas, NLP ir generacinis modeliavimas. Darbas sujungia teoriją ir pritaikymą adaptyviajame optimizavime, nors būsimi tyrimai gali ištirti švelnesnes prielaidas, kad būtų galima dar labiau apibendrinti ADOPT efektyvumą.
Patikrinkite Popierius ir GitHub. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(AI žurnalas / ataskaita) Skaitykite mūsų naujausią ataskaitą apieMAŽI KALBOS MODELIAI“
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️





