

Didelių kalbų modeliai (LLM) parodė nepaprastas galimybes atlikti sudėtingas samprotavimo užduotis, ypač atliekant matematinį problemų sprendimo ir kodavimo programas. Tyrimai parodė tvirtą koreliaciją tarp samprotavimo grandinių ilgio ir geresnio tikslumo sprendžiant problemas sprendžiant rezultatus. Tačiau jie susiduria su dideliais iššūkiais: nors išplėstiniai samprotavimo procesai padidina problemų sprendimo galimybes, jie dažnai lemia neefektyvius sprendimus. Modeliai paprastai generuoja be reikalo ilgus samprotavimo grandines net ir dėl paprastų klausimų, kuriuos būtų galima išspręsti tiesiogiai. Šis vienodus požiūris į samprotavimo ilgį sukuria skaičiavimo neveiksmingumą ir sumažina šių sistemų praktinį naudingumą realaus pasaulio programose.
Atsirado įvairių metodikų, siekiant sustiprinti LLMS samprotavimo galimybes, o minties grandinė (COT) yra pagrindinis požiūris, kuris pagerina problemų sprendimą, suskaidant samprotavimus į diskretus žingsnius. Remdamiesi lovele, tyrėjai sukūrė sudėtingesnius metodus, tokius kaip išplėstinė lovelė su papildomais žingsniais, savirefleksijos mechanizmais, daugiapakopiais samprotavimais ir daugialypėmis diskusijų sistemomis. Naujausi pokyčiai sutelkė dėmesį į samprotavimo ilgio padidėjimą, kaip parodė tokie modeliai kaip „Openai-O1“ ir „Deepseek-R1“. Tačiau jie sukuria plačias samprotavimo grandines, neatsižvelgiant į problemos sudėtingumą. Šis neefektyvus požiūris padidina skaičiavimo sąnaudas ir didesnius anglies pėdsakus.
Meta AI ir Ilinojaus universiteto Čikagos universiteto tyrėjai pasiūlė novatorišką požiūrį į LLM samprotavimo neveiksmingumą kuriant sistemą, kuri automatiškai koreguoja samprotavimo pėdsakų ilgį, atsižvelgiant į užklausos sudėtingumą. Nors ankstesni euristiniai metodai bandė pagerinti žetonų efektyvumą, kad būtų geresnis tikslumas, nes sumažėjo pridėtinė vertė, šis naujas tyrimas atitinka stiprinimo mokymosi (RL) perspektyvą. Užuot aiškiai modeliuojantys atsako ilgį ar subalansuodami vidinius ir išorinius apdovanojimus, tyrėjai sukūrė grupavimo metodiką, apimančią atsakymų suskirstymą į atskiras grupes pagal jų ypatybes, sukurdami išsamią sistemą, skirtą aprėpti visą atsakymo erdvę, išlaikant efektyvumą.
Siūlomoje metodikoje naudojama sekos lygio žymėjimo sistema, kuri supaprastina sudėtingas perėjimo tikimybes ir tarpinius apdovanojimus, laikant kiekvieną atsakymą kaip visą vienetą. Architektūra suskirsto atsakymus į dvi pirmines grupes: viena-įprasto ilgio mąstymo grandinės atsakymams, kita-dėl išplėstinių atsakymų, kiekviena su skirtingomis išvadų sąnaudomis. Sistema veikia per dviejų lygių optimizavimo sistemą, kai išteklių paskirstymo apribojimai yra apibrėžti išgaubtame politope, kuris riboja kiekvienos grupės tankio masę. Be to, algoritmas naudoja iteracinį metodą, išspręsdamas viršutinio lygio problemą per gradiento atnaujinimus, tiesiogiai nukreipdamas žemesnio lygio optimizavimą kiekvienoje iteracijoje.
Eksperimentiniai rezultatai rodo reikšmingą rezultatų pagerėjimą skirtingose siūlomos metodikos įgyvendinimuose. Prižiūrimos tobulinimo (SFT) konstrukcijos, SVSFT ir ASV-SFT-1, pasiekia patobulintą praėjimą@1 metriką, nors ir padidėjus išvadų reikalavimams. Visų pirma, ASV-IUB-Q+ kompozicija, kurių parametrai yra 50% ir 75% pagrįstas savęs taisymo metodas. Rezultatai taip pat atskleidžia pastebimą raginimų ir SFT pagrįstų metodų apribojimą tiek absoliučiai tobulinimo, tiek efektyvumo metrikoje, ir tai rodo, kad savęs taisymo galimybės efektyviau atsiranda per RL.
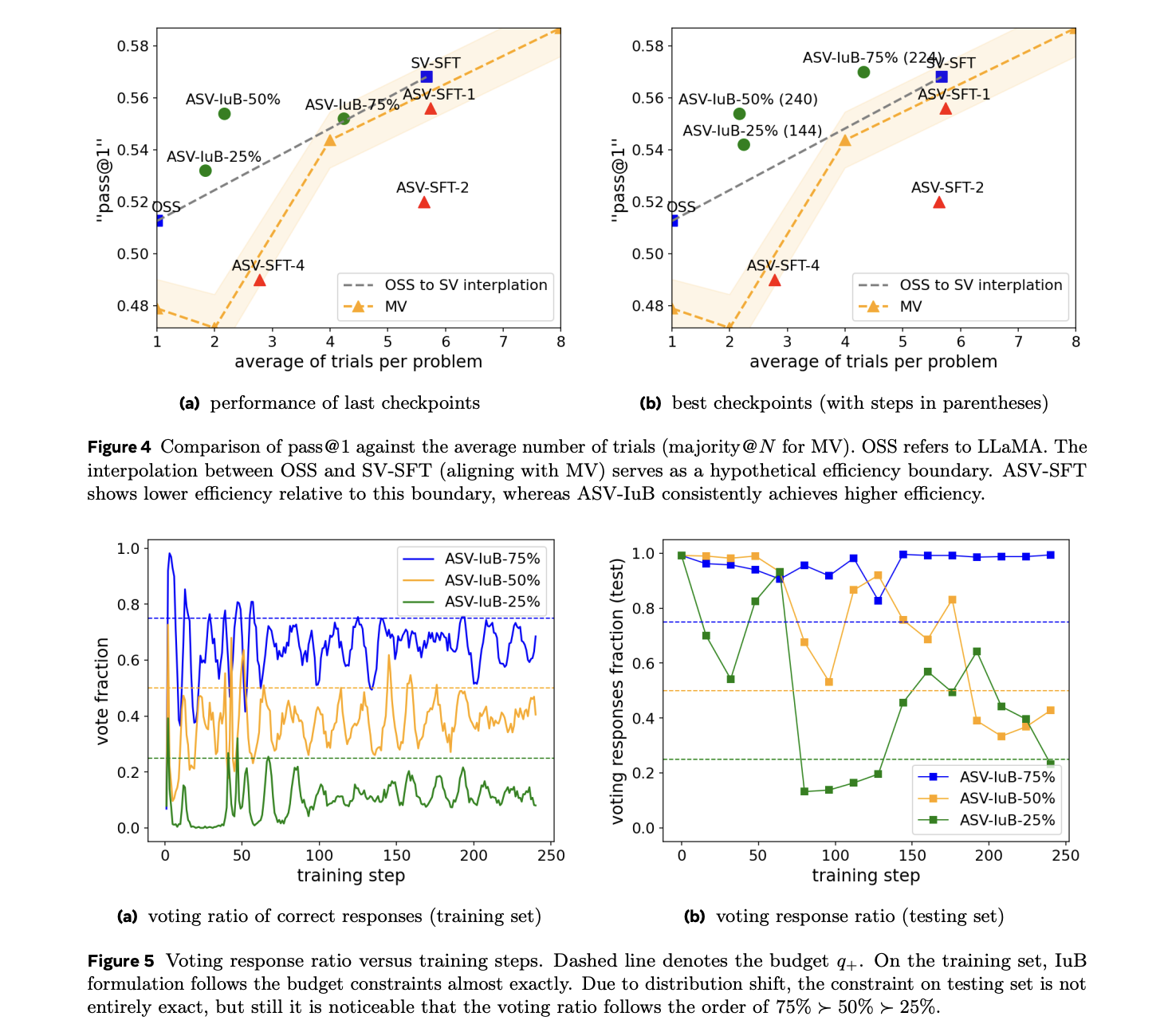
Apibendrinant, tyrėjai pristatė metodą, kaip įveikti LLM samprotavimo neveiksmingumą. Be to, jie pristatė „IBPO“-suvaržytą politikos optimizavimo sistemą, įgyvendinančią svertinį prižiūrimą tobulinimo atnaujinimo mechanizmą. Šis metodas nustato optimalius svorius per sveikąjį linijinį programavimo sprendimą kiekvienoje iteracijoje, pagrįstą CGPO sistema. Nors sistema rodo veiksmingą suvaržymo laikymąsi ir dinamiškų išvadų biudžeto paskirstymą atliekant matematinių samprotavimo užduotis, skaičiavimo išteklių apribojimus galima išspręsti kaupiant imtį keliais etapais. Ateities tyrimų kryptys apima sistemos pritaikymo išplėtimą įvairiose LLM programose ir eksperimentinių įgyvendinimų padidinimą, kad būtų galima išbandyti visą jo potencialą įvairiuose kontekstuose.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)

Sajjad Ansari yra paskutinių metų bakalauras iš IIT Kharagpur. Kaip technikos entuziastas, jis gilinasi į AI praktinius pritaikymus, daugiausia dėmesio skirdamas AI technologijų poveikio ir jų realiojo poveikio poveikiui supratimui. Jis siekia aiškiai ir prieinamai išdėstyti sudėtingas AI sąvokas.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo





