Įvadas
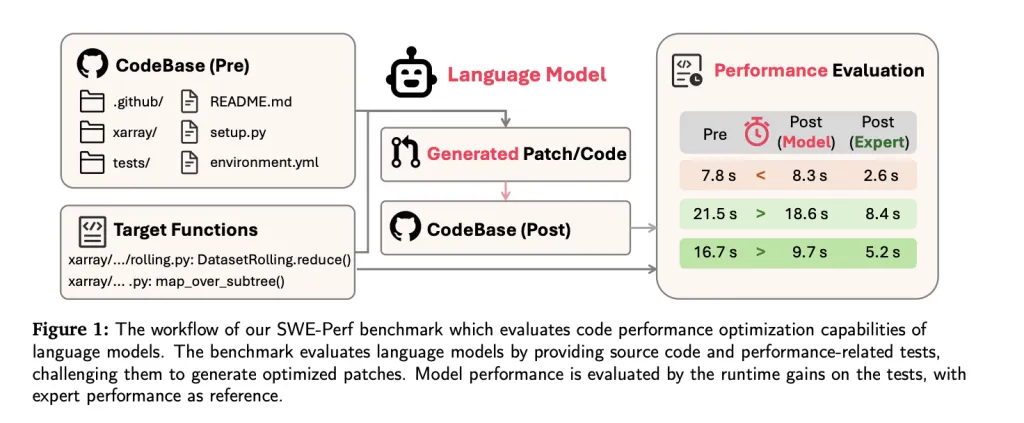
Kadangi didelių kalbų modelių (LLMS) progresuoja programinės įrangos inžinerijos užduotys – nuo kodo generavimo iki klaidų taisymo – vykdymo optimizavimas išlieka nemandagus siena, ypač saugyklos lygyje. Norėdami užpildyti šią spragą, „Tiktok“ tyrėjai ir bendradarbiavimo institucijos pristatė SWE-PERF-Pirmasis etalonas, specialiai skirtas įvertinti LLMS galimybes optimizuoti kodo našumą realaus pasaulio saugyklose.
Skirtingai nuo ankstesnių etalonų, orientuotų į teisingumą ar funkcijų lygio efektyvumą (pvz., SWE-Bench, Mercury, Effibench), SWE-perf užfiksuoja saugyklos masto efektyvumo derinimo sudėtingumą ir kontekstinį gylį. Tai suteikia atkuriamą, kiekybinį pagrindą ištirti ir patobulinti šiuolaikinių LLM veiklos optimizavimo galimybes.
Kodėl reikia „Swe-Perf“
Realaus pasaulio kodų bazės dažnai būna didelės, modulinės ir sudėtingai tarpusavyje susijusios. Jų optimizavimui atlikti našumui reikia suprasti kryžminio failo sąveiką, vykdymo kelius ir skaičiavimo kliūtis-skiedinius, viršijančius izoliuotų funkcijų lygio duomenų rinkinių sritį.
LLM šiandien iš esmės vertinamos atliekant tokias užduotis kaip sintaksės korekcija ar mažos funkcijos transformacijos. Tačiau gamybos aplinkoje saugojimo veiklos derinimas gali suteikti didesnę naudą visoje sistemoje. „SWE-Perf“ yra aiškiai sukurtas norint įvertinti LLM galimybes tokiose nustatymuose.
Duomenų rinkinio konstrukcija
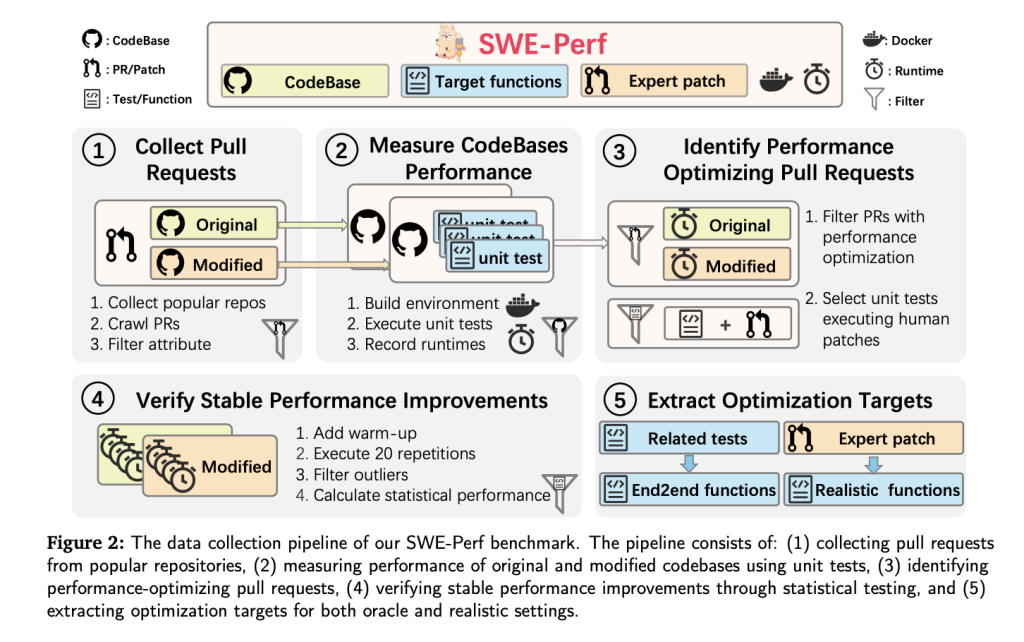
„SWE-perf“ yra pastatytas iš daugiau nei 100 000 patrauklių užklausų, susijusių su aukšto lygio „GitHub“ saugyklomis. Galutinis duomenų rinkinys apėmė 9 saugyklas, įskaitant:
- 140 kuruojami atvejai Parodyti išmatuojamus ir stabilius veiklos patobulinimus.
- Užpildykite kodų bazes prieš ir po optimizavimo.
- Tikslinės funkcijos suskirstyti į „Oracle“ (failo lygį) arba realistiškas (REPO lygis).
- Vienetų testai ir „Docker“ aplinka Atkuriamam vykdymui ir našumo matavimui.
- Ekspertų autorių pleistrai naudojami kaip aukso standartai.
Norėdami užtikrinti pagrįstumą, kiekvienas vieneto testas turi:

- Praeiti prieš ir po pleistro.
- Parodykite statistiškai reikšmingą vykdymo laiko padidėjimą per 20 kartojimų (Mann-Whitney U testas, P <0,1).
Našumas matuojamas naudojant minimalų našumo padidėjimą (δ), izoliuojant statistinius patobulinimus, priskirtinus pleistrui filtruojant triukšmą.
Etaloniniai nustatymai: „Oracle“ ir „Realistiškas“
- „Oracle“ nustatymas: Modelis gauna tik tikslines funkcijas ir atitinkamus failus. Šis nustatymas testuoja lokalizuotus optimizavimo įgūdžius.
- Realistiška aplinka: Modeliui suteikiama visa saugykla ir jis turi savarankiškai identifikuoti bei optimizuoti veiklos kritinius kelius. Tai yra artimesnis analogas tam, kaip veikia žmonės inžinieriai.
Vertinimo metrika
„SWE-Perf“ apibrėžia trijų pakopų vertinimo sistemą, savarankiškai pranešdama apie kiekvieną metriką:
- Kreiptis: Ar modelio sukurtą pleistrą galima naudoti švariai?
- Teisingumas: Ar pleistras išsaugo funkcinį vientisumą (visi vienetų testai praeina)?
- Spektaklis: Ar pleistro išmatuojamas vykdymo laiko pagerėjimas?
Metrika nėra suskirstyta į vieną balą, leidžiančią labiau įvertinti niuansuotus kompromisus tarp sintaksinio teisingumo ir našumo padidėjimo.
Eksperimentiniai rezultatai
„Enchmark“ įvertina kelis aukščiausio lygio LLM tiek „Oracle“, tiek realistiškose nustatymuose:
| Modelis | Nustatymas | Našumas (%) |
|---|---|---|
| Claude-4-Opus | Orakulas | 1.28 |
| GPT-4o | Orakulas | 0,60 |
| „Gemini-2.5-Pro“ | Orakulas | 1.48 |
| Claude-3,7 (be agentų) | Realistas | 0,41 |
| „Claude-3,7“ („Openhands“) | Realistas | 2.26 |
| Ekspertas (žmogaus pleistras) | – | 10.85 |
Pažymėtina, kad net ir geriausiai veikiančios LLM konfigūracijos žymiai neatitinka žmogaus lygio našumo. Agentais pagrįstas metodas „Openhands“, sukurtas ant „Claude-3.7-Sonnet“, realioje aplinkoje pralenkia kitas konfigūracijas, tačiau vis dar atsilieka nuo ekspertų sukurtų optimizacijų.
Pagrindiniai stebėjimai
- Agentų pagrindu sukurtos sistemos, tokios kaip „Openhands“ geriau tinka sudėtingam, daugiapakopiam optimizavimui, pralenkiantiems tiesioginio modelio raginimus ir vamzdynų pagrindu sukurtus metodus, tokius kaip „Agentless“.
- Našumas blogėja Didėjant tikslinių funkcijų skaičiui – „llms“ kovoja su platesnėmis optimizavimo apimtimis.
- LLMS turi ribotą mastelį Ilgalaikiuose scenarijuose, kur ekspertų sistemos ir toliau rodo našumo padidėjimą.
- Pataiso analizė Parodomos LLMS daugiau dėmesio skiria žemo lygio kodo struktūroms (pvz.
Išvada
„SWE-perf“ yra pagrindinis žingsnis siekiant išmatuoti ir tobulinti LLMS optimizavimo galimybes realiose programinės įrangos inžinerijos darbo eigose. Tai atskleidžia didelį galimybių atotrūkį tarp esamų modelių ir žmonių ekspertų, siūlančių tvirtą pagrindą būsimiems tyrimams saugyklos masto atlikimo derinimo srityje. Vystantis LLMS, „SWE-perf“ gali būti „North Star“, nukreipianti juos į praktinį, gamybai paruoštą programinės įrangos patobulinimą mastu.
Peržiūrėkite Popierius, „Github“ puslapis ir projektas. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams.
Rėmimo galimybė: Pasiekite įtakingiausius AI kūrėjus JAV ir Europoje. 1m+ mėnesiniai skaitytojai, 500K+ bendruomenės statytojai, begalinės galimybės. (Tyrinėti rėmimą)
Asif Razzaq yra „MarkTechPost Media Inc“ generalinis direktorius. Kaip vizionierius verslininkas ir inžinierius, ASIF yra įsipareigojęs išnaudoti dirbtinio intelekto potencialą socialiniam gėrybei. Naujausias jo siekis yra dirbtinio intelekto žiniasklaidos platformos „MarkTechPost“, kuri išsiskiria išsamia mašininio mokymosi ir giluminio mokymosi naujienų, kuri yra techniškai pagrįsta, ir lengvai suprantama plačiai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonai mėnesinių peržiūrų, parodydama jos populiarumą tarp auditorijos.