Multimodaliniai AI agentai yra skirti apdoroti ir integruoti įvairius duomenų tipus, tokius kaip vaizdai, tekstas ir vaizdo įrašai, skirti atlikti užduotis skaitmeninėje ir fizinėje aplinkoje. Jie naudojami robotikoje, virtualiuose padėjėjuose ir vartotojo sąsajos automatizavime, kur jie turi suprasti ir veikti pagal sudėtingus multimodalinius įvestis. Šiomis sistemomis siekiama įveikti žodinį ir erdvinį intelektą, pasinaudojant gilaus mokymosi metodais, leidžiančiomis sąveikai įvairiose srityse.
PG sistemos dažnai specializuojasi vizijos kalbos supratime ar manipuliacijoje robotuose, tačiau stengiasi sujungti šias galimybes į vieną modelį. Daugelis AI modelių yra skirti konkrečioms sritims skirtoms užduotims, tokioms kaip UI navigacija skaitmeninėje aplinkoje ar fizinės manipuliacijos robotikoje, ribojant jų apibendrinimą įvairiose programose. Iššūkis yra sukurti vieningą modelį, kaip suprasti ir veikti įvairiais būdais, užtikrinant veiksmingą sprendimų priėmimą struktūrizuotoje ir nestruktūrizuotoje aplinkoje.
Esami regėjimo kalbos (VLA) modeliai bando spręsti daugiamodalines užduotis, išimant didelius regėjimo kalbos porų duomenų rinkinius, po kurių pateikiami veiksmo trajektorijos duomenys. Tačiau šiems modeliams paprastai trūksta pritaikomumo skirtingose aplinkose. Pavyzdžiai yra „Pix2ACT“ ir „WebGum“, kurie tobulėja UI navigacijoje, ir „OpenVLA“ ir „RT-2“, kurie yra optimizuoti robotiniams manipuliacijoms. Šiems modeliams dažnai reikalingi atskiri mokymo procesai ir nesugebėti apibendrinti tiek skaitmeninėje, tiek fizinėje aplinkoje. Be to, įprasti multimodaliniai modeliai kovoja su erdvinio ir laikinojo intelekto integravimu, ribodami jų sugebėjimą autonomiškai atlikti sudėtingas užduotis.
Merilando universiteto, Viskonsino-Madisono Kaisto ir Vašingtono universiteto, Vašingtono universiteto, tyrėjai ir Vašingtono universitetas Magmapamatų modelis, skirtas suvienodinti multimodalinį supratimą su veiksmo vykdymu, suteikiant galimybę AI agentams sklandžiai veikti skaitmeninėje ir fizinėje aplinkoje. „Magma“ yra skirta įveikti esamų VLA modelių trūkumus, įtraukiant patikimą mokymo metodiką, integruojančią daugialypį supratimą, veiksmų pagrindimą ir planavimą. Magma mokoma naudojant įvairius duomenų rinkinį, kurį sudaro 39 milijonai pavyzdžių, įskaitant vaizdus, vaizdo įrašus ir robotų veiksmo trajektorijas. Tai apima dvi naujas technikas,
- Ekreto rinkinys (SOM): SOM leidžia modeliui pažymėti veiksmingus vaizdinius objektus, tokius kaip mygtukai UI aplinkoje
- Marko pėdsakai (Tomas): Tomas leidžia laikui bėgant sekti objektų judesius ir atitinkamai suplanuoti būsimus veiksmus
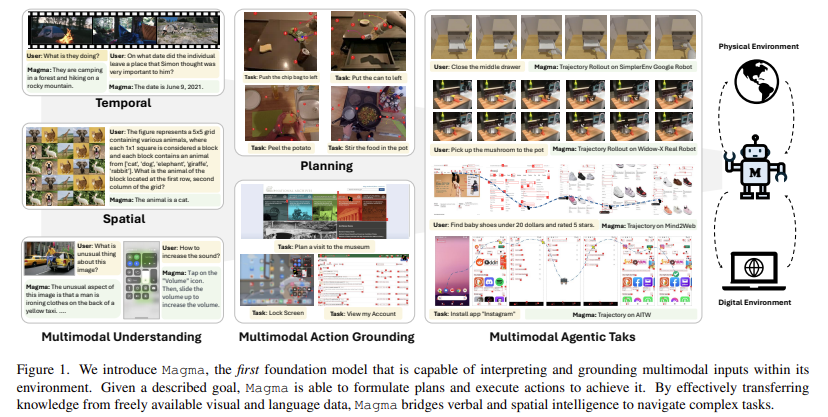
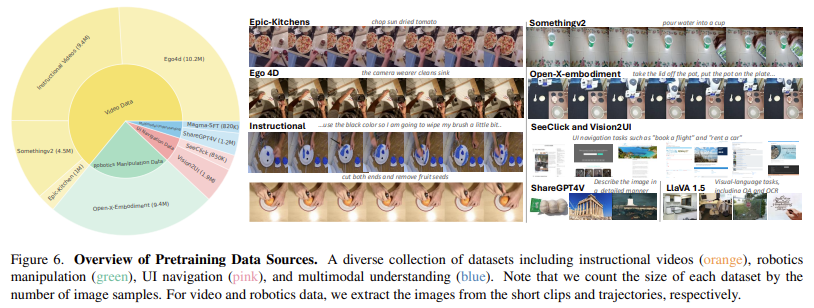
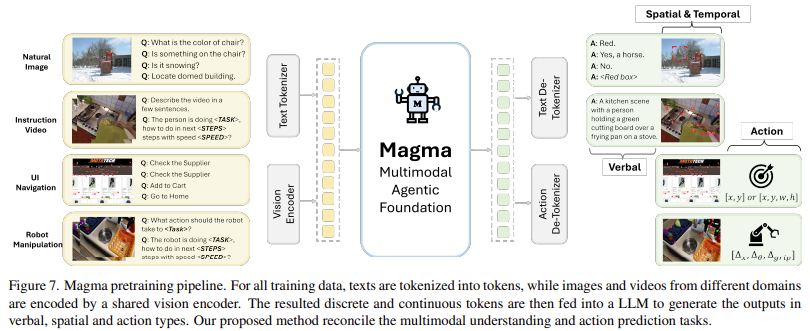
„Magma“ naudoja giluminio mokymosi architektūros ir didelio masto išankstinio rašymo derinį, kad optimizuotų jo našumą keliose srityse. Modelyje vaizdams ir vaizdo įrašams apdoroti naudojamas „concnext-xxl“ regėjimo stuburas, o „Llama-3-8b“ kalbos modelis tvarko tekstines įvestis. Ši architektūra suteikia „Magma“ galimybę sklandžiai integruoti vizijos kalbos supratimą su veiksmo vykdymu. Jis yra mokomas kuruojamo duomenų rinkinio, kuriame yra UI navigacijos užduotys iš „SeeClick“ ir „Vision2UI“, robotų manipuliavimo duomenų rinkiniai iš atvirojo-X-Imbodiment ir mokomųjų vaizdo įrašų iš tokių šaltinių kaip ego4D, kažkas, kas yra V2 ir EPIC-KITCHEN. Pasitelkdama SOM ir Tomą, „Magma“ gali efektyviai išmokti veiksmo pagrindą iš UI ekrano kopijų ir robotikos duomenų, tuo pačiu padidindama jos sugebėjimą numatyti būsimus veiksmus, pagrįstus stebimomis vaizdinėmis sekomis. Treniruotės metu modelis apdoroja iki 2,7 milijono UI ekrano kopijų, 970 000 robotų trajektorijų ir daugiau nei 25 milijonų vaizdo įrašų pavyzdžių, kad būtų užtikrintas patikimas multimodalinis mokymasis.
Atliekant „Zero-Shot“ UI navigacijos užduotis, magma pasiekė 57,2%elementų pasirinkimo tikslumą, pralenkdami tokius modelius kaip GPT-4V-Omniparser ir SeeClick. Vykdydama robotų manipuliavimo užduotis, „Magma“ pasiekė 52,3% sėkmės procentą „Google“ robotų užduotyse ir 35,4% tiltų modeliavimo metu, žymiai viršijant „OpenVLA“, kuri tuo pačiu etalonu pasiekė tik 31,7% ir 15,9%. Modelis taip pat buvo atliktas ypač gerai atliekant multimodalinio supratimo užduotis, pasiekdamas 80,0% tikslumą VQA V2, 66,5% „TextVQA“ ir 87,4% popiežiaus vertinimuose. „Magma“ taip pat pademonstravo stiprias erdvinio samprotavimo galimybes, įvertinusi 74,8% „Blink“ duomenų rinkinyje ir 80,1% pagal vaizdinio erdvinio samprotavimo (VSR) etaloną. Vaizdo klausimų ir atsakymų užduotyse „Magma“ pasiekė 88,6% tikslumą „IntentQA“ ir 72,9% „NextQA“, dar labiau pabrėždama jos sugebėjimą efektyviai apdoroti laikiną informaciją.
Iš „Magma“ tyrimų atsiranda keletas pagrindinių pasirinkimų:
- Magma buvo apmokyta 39 milijonų multimodalinių mėginių, įskaitant 2,7 milijono UI ekrano kopijų, 970 000 robotų trajektorijų ir 25 milijonų vaizdo pavyzdžių.
- Modelis sujungia viziją, kalbą ir veiksmą vieningoje sistemoje, įveikdamas domeno specifinių AI modelių apribojimus.
- SOM įgalina tikslų spustelėjamų objektų ženklinimą, o TOM leidžia laikui bėgant sekti objektų judėjimą, pagerindamas ilgalaikio planavimo galimybes.
- Magma pasiekė 57,2% tikslumo greitį pasirenkant elementus UI užduotyse, 52,3% sėkmės robotų manipuliavimo procentas ir 80,0% tikslumo greitis atliekant VQA užduotis.
- „Magma“ aplenkė esamus AI modelius daugiau nei 19,6% erdvinių samprotavimų etalonų ir pagerėjo 28%, palyginti su ankstesniais vaizdo įrašų pagrindu pagrįstais modeliais.
- Magma pademonstravo aukštesnį apibendrinimą atliekant kelias užduotis, nereikalaudama papildomo derinimo, todėl tai tapo labai pritaikoma AI agentu.
- „Magma“ galimybės gali pagerinti sprendimų priėmimą ir vykdymą robotikoje, autonominėse sistemose, UI automatizavimą, skaitmeninius padėjėjus ir pramonės AI.
Patikrinkite Popieriaus ir projekto puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama „Read-LG AI Research“ išleidžia „Nexus“: pažangių sistemos integracinių agentų AI sistemos ir duomenų atitikties standartų, skirtų teisiniams klausimams spręsti AI duomenų rinkiniuose
Asif Razzaq yra „MarkTechPost Media Inc“ generalinis direktorius. Kaip vizionierius verslininkas ir inžinierius, ASIF yra įsipareigojęs išnaudoti dirbtinio intelekto potencialą socialiniam gėrybei. Naujausias jo siekis yra dirbtinio intelekto žiniasklaidos platformos „MarkTechPost“, kuri išsiskiria išsamia mašininio mokymosi ir giluminio mokymosi naujienų, kuri yra techniškai pagrįsta, ir lengvai suprantama plačiai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonai mėnesinių peržiūrų, parodydama jos populiarumą tarp auditorijos.