

Šį straipsnį iš pradžių paskelbė Amperų skaičiavimas.
mačiau a tinklaraščio straipsnis apie gprofng, naujas GNU profiliavimo įrankis. To tinklaraščio pavyzdys buvo matricos vektorių daugybos programa, parašyta C kalba. Aš esu Java™ programuotojas, o Java programų profiliavimas yra dažnai sunku su įrankiais, skirtais statiškai kompiliuotoms C programoms, o ne Java programoms, kurios kompiliuojamos vykdymo metu. Šiame tinklaraštyje aš tai parodau gprofng yra paprasta naudoti ir naudinga norint įsigilinti į dinamišką „Java“ programos veikimą.
Pirmas žingsnis buvo parašyti a matricos daugybos programa. Parašiau pilną matricos-kart-matricos programą, nes ji nėra sunkesnė už matricos-kartų-vektorių. Egzistuoja trys pagrindiniai metodai: vienas metodas, skirtas vidiniam padauginimui, vienas metodas, skirtas sujungti daugybos veiksmus į vieną rezultato elementą, ir vienas metodas, skirtas kartoti kiekvieno rezultato elemento skaičiavimą.
Skaičiavimą įtraukiau į paprastą diržą, kad pakartotinai skaičiuočiau matricos sandaugą, kad įsitikinčiau, ar laikai pasikartoja. (Žr. 1 pabaigos pastabą.) Programa išspausdina, kada prasideda kiekvienas matricos dauginimas (lyginant su Java virtualios mašinos pradžia), ir kiek laiko užtrunka kiekviena matrica dauginama. Čia aš atlikau testą, kad padauginčiau dvi 8000 × 8000 matricas. Diržai pakartoja skaičiavimą 11 kartų ir, kad vėliau geriau išryškintų elgesį, tarp pakartojimų miega 920 milisekundžių:
$ numactl --cpunodebind=0 --membind=0 -- \
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData \
MxV -m 8000 -n 8000 -r 11 -s 920
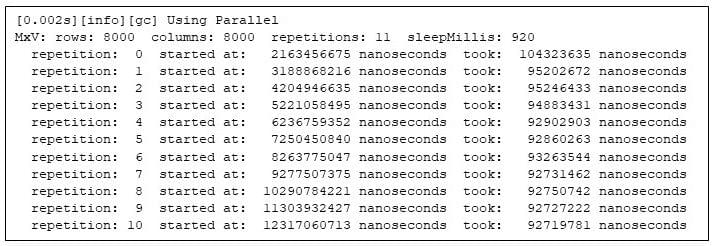
1 pav. Matricos daugybos programos vykdymas
Atkreipkite dėmesį, kad antrasis pakartojimas trunka 92% pirmojo kartojimo laiko, o paskutinis pakartojimas – tik 89% pirmojo kartojimo laiko. Šie vykdymo laiko skirtumai patvirtina, kad Java programoms reikia šiek tiek laiko sušilti.
Kyla klausimas: ar galiu naudoti gprofng pamatyti, kas vyksta tarp pirmojo ir paskutinio pakartojimo, dėl ko pagerėja pasirodymas?
Vienas iš būdų atsakyti į šį klausimą yra paleisti programą ir leisti gprofng rinkti informaciją apie bėgimą. Laimei, tai lengva: aš tiesiog prieš komandinę eilutę įrašau a gprofng komandą rinkti ką gprofng vadina „eksperimentu“.
$ numactl --cpunodebind=0 --membind=0 -- \
gprofng collect app \
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData \
MxV -m 8000 -n 8000 -r 11 -s 920
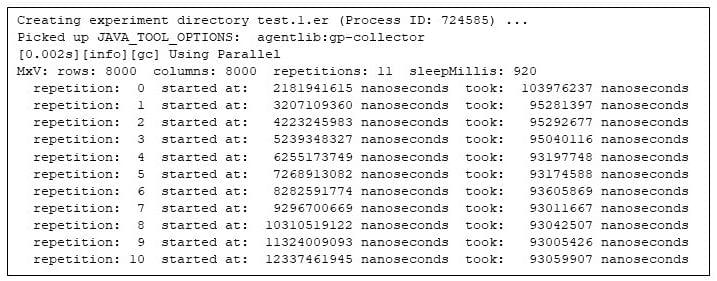
2 pav. Matricos daugybos programos vykdymas pagal gprofng
Pirmas dalykas, į kurį reikia atkreipti dėmesį, kaip ir naudojant bet kurį profiliavimo įrankį, yra pridėtinės išlaidos, kurias programai patiria renkant profiliavimo informaciją. Palyginti su ankstesniu neprofiliuotu paleidimu, gprofng atrodo, kad tai nereikalauja jokių pastebimų papildomų išlaidų.
Tada galiu paklausti gprofng kaip buvo praleistas laikas visoje paraiškoje. (Žr. 2 pabaigos pastabą.) Visą bėgimą, gprofng sako, kad karščiausi 24 metodai yra:
$ gprofng display text test.1.er -viewmode expert -limit 24 -functions
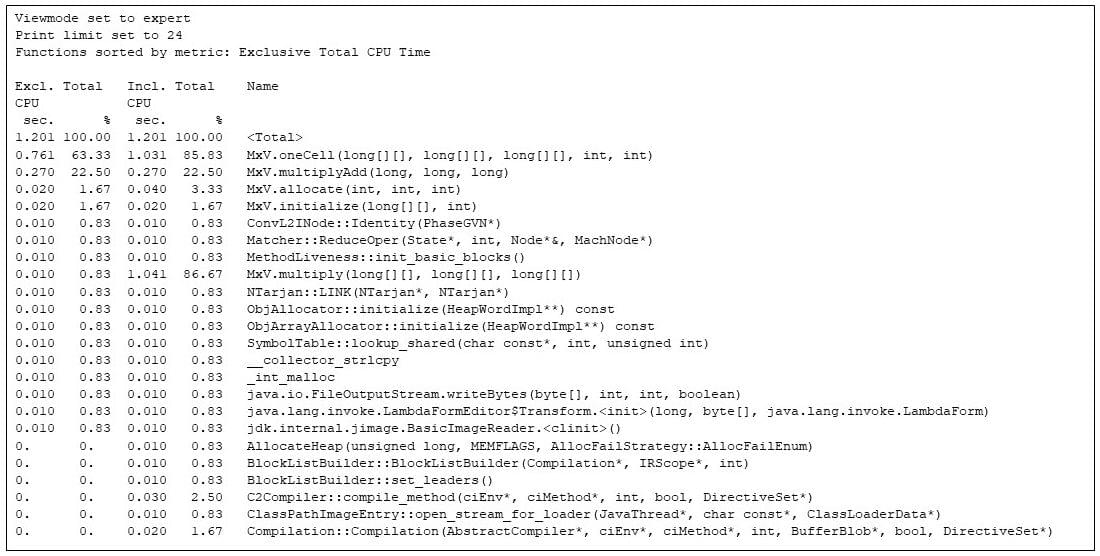
3 paveikslas: 24 karščiausių metodų Gprofng ekranas
Aukščiau pateiktame funkcijų rodinyje pateikiamas išskirtinis ir įtrauktas kiekvieno metodo procesoriaus laikas, tiek sekundėmis, tiek procentais nuo bendro procesoriaus laiko. Pavadinta funkcija yra pseudo funkcija, kurią sugeneravo gprofng ir turi bendrą įvairių metrikų vertę. Šiuo atveju matau, kad bendras procesoriaus laikas, praleistas visai programai, yra 1,201 sekundės.
Taikymo metodai (metodai iš klasės MxV) yra ten ir užima didžiąją dalį procesoriaus laiko, tačiau yra ir kitų metodų, įskaitant JVM (Compilation::Compilation) ir kitos funkcijos, kurios nėra matricos daugiklio dalis. Šis visos programos vykdymo rodinys užfiksuoja paskirstymą (MxV.allocate) ir inicijavimas (MxV.initialize) kodą, kuris mane mažiau domina, nes yra bandomojo diržo dalis, yra naudojami tik paleidžiant ir turi mažai ką bendro su matricos daugyba.
Galiu naudoti gprofng sutelkti dėmesį į tas programos dalis, kurios mane domina. Viena iš nuostabių programos savybių gprofng yra tai, kad surinkus eksperimentą galiu pritaikyti filtrus surinktiems duomenims. Pavyzdžiui, pažiūrėti, kas vyko tam tikru laiko intervalu arba kai tam tikras metodas yra skambučių krūvoje. Demonstravimo tikslais ir palengvinti filtravimą pridėjau strateginius skambučius Thread.sleep(ms) kad būtų lengviau rašyti filtrus pagal programos fazes, atskirtas vienos sekundės intervalais. Štai kodėl 1 paveiksle aukščiau pateiktoje programos išvestyje kiekvienas pakartojimas yra atskirtas maždaug viena sekunde, nors kiekvienas matricos kartotinis trunka tik apie 0,1 sekundės.
gprofng yra scenarijus, todėl parašiau scenarijų, kad ištraukčiau atskiras sekundes iš gprofng eksperimentas. Pirmoji sekundė yra apie Java virtualios mašinos paleidimą.
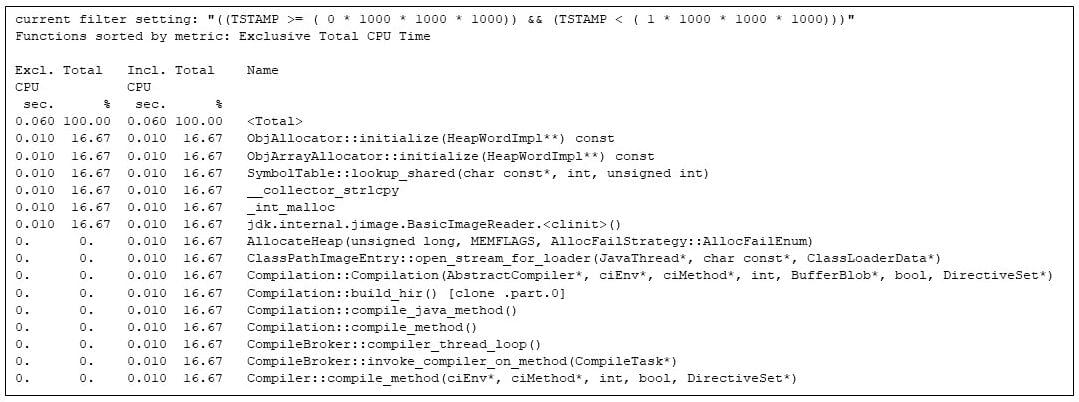
4 pav. Karščiausių metodų filtravimas per pirmąją sekundę. Matricos padauginimas buvo dirbtinai atidėtas per šią sekundę, kad galėčiau parodyti JVM paleidimą
Matau, kad įsijungia vykdymo laiko kompiliatorius (pvz., Compilation::compile_java_method, užima 16 % procesoriaus laiko), net jei nė vienas iš programos metodų nebuvo paleistas. (Matricos daugybos skambučiai vėluoja dėl mano įterptų miego skambučių.)
Po pirmosios sekundės yra antra, kurios metu vykdomi paskirstymo ir inicijavimo metodai, kartu su įvairiais JVM metodais, tačiau nė vienas matricos dauginimo kodas dar nepradėtas.
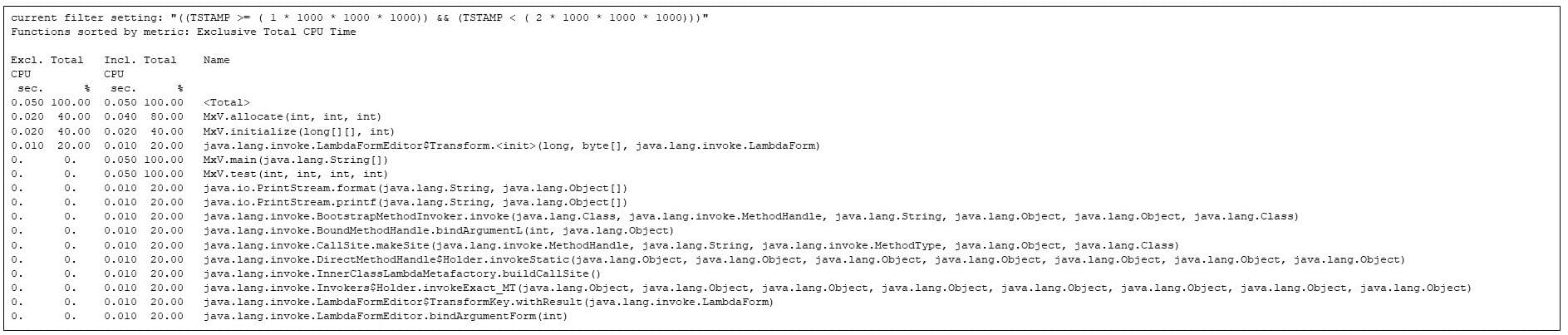
5 pav. Karščiausi metodai antrą sekundę. Matricos paskirstymas ir inicijavimas konkuruoja su JVM paleidimu
Dabar, kai JVM paleidimas ir masyvų paskirstymas bei inicijavimas baigtas, trečioje sekundėje pirmą kartą pakartojamas matricos daugybos kodas, parodytas 6 paveiksle. Tačiau atminkite, kad matricos dauginimo kodas konkuruoja dėl mašinos išteklių su Java vykdymo laiko kompiliatoriumi. (pvz., CompileBroker::invoke_compiler_on_method8% 6 paveiksle), kuris kompiliuoja metodus, nes nustatyta, kad matricos daugybos kodas yra karštas.
Nepaisant to, matricos daugybos kodas (pvz., „imtinai“ laikas MxV.main metodu, 91%) sunaudoja didžiąją procesoriaus laiko dalį. Laikas imtinai sako, kad matrica dauginasi (pvz., MxV.multiply). gprofng sąskaitos į MxV.multiply.)
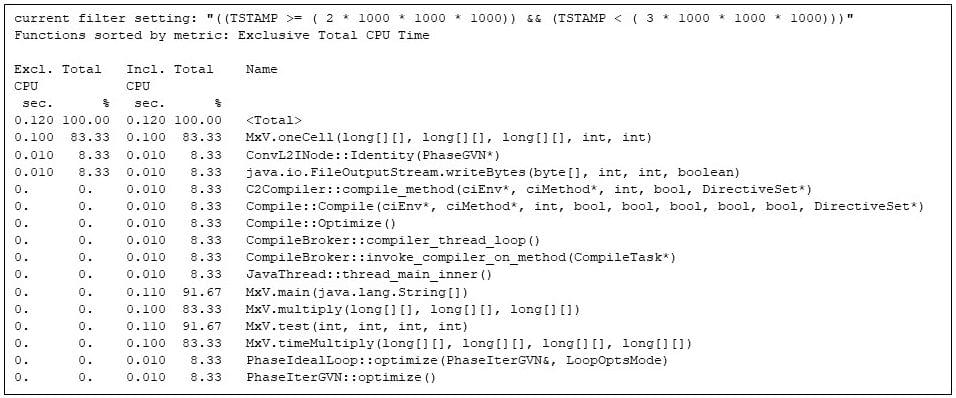
6 pav. Karščiausi metodai trečią sekundę, rodantys, kad vykdymo laiko kompiliatorius konkuruoja su matricos daugybos metodais
Šiame konkrečiame pavyzdyje matricos dauginimas tikrai nekonkuruoja dėl procesoriaus laiko, nes testas vykdomas kelių procesorių sistemoje su daugybe tuščiosios eigos ciklų, o vykdymo laiko kompiliatorius veikia kaip atskiros gijos. Esant labiau ribotoms aplinkybėms, pavyzdžiui, labai apkrautame bendrai naudojamame kompiuteryje, 8 % laiko, praleisto vykdymo laiko kompiliatoriuje, gali kilti problema. Kita vertus, laikas, praleistas vykdymo laiko kompiliatoriuje, efektyviau įgyvendina metodus, taigi, jei skaičiuočiau daug matricos padauginimų, tai yra investicija, kurią norėčiau padaryti.
Iki penktos sekundės matricos dauginimo kodas turi Java virtualią mašiną.
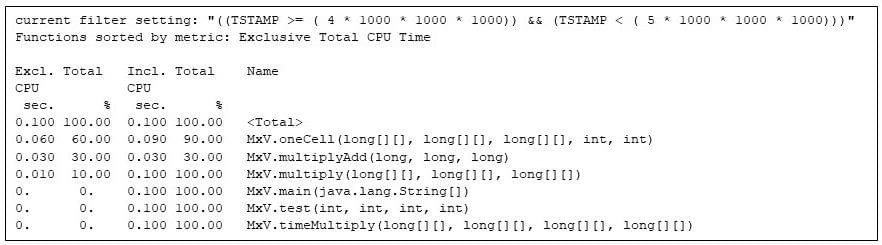
7 pav. Visi vykdomi metodai per penktą sekundę, rodantys, kad aktyvūs tik matricos daugybos metodai
Atkreipkite dėmesį į 60% / 30% / 10% padalijimą per išskirtines CPU sekundes MxV.oneCell, MxV.multiplyAddir MxV.multiply. The MxV.multiplyAdd metodas paprasčiausiai apskaičiuoja dauginimą ir sudėjimą: bet tai yra slapčiausias matricos daugybos metodas. MxV.oneCell turi kilpą, kuri skambina MxV.multiplyAdd. Matau, kad kilpa ir skambutis (sąlygų įvertinimas ir valdymo perdavimas) yra santykinai daugiau darbo nei tiesi aritmetika MxV.multiplyAdd. (Šį skirtumą atspindi išskirtinis laikas, skirtas MxV.oneCell 0,060 procesoriaus sekundės, palyginti su 0,030 procesoriaus sekundės MxV.multiplyAdd.) Išorinis MxV.multiply ciklas vykdomas pakankamai retai, todėl vykdymo laiko kompiliatorius jo dar nesukompiliavo, tačiau šis metodas naudoja 0,010 procesoriaus sekundės.
Matricos dauginimas tęsiasi iki devintos sekundės, kai JVM vykdymo laiko kompiliatorius vėl įsijungia, atradęs, kad MxV.multiply pasidarė karšta.
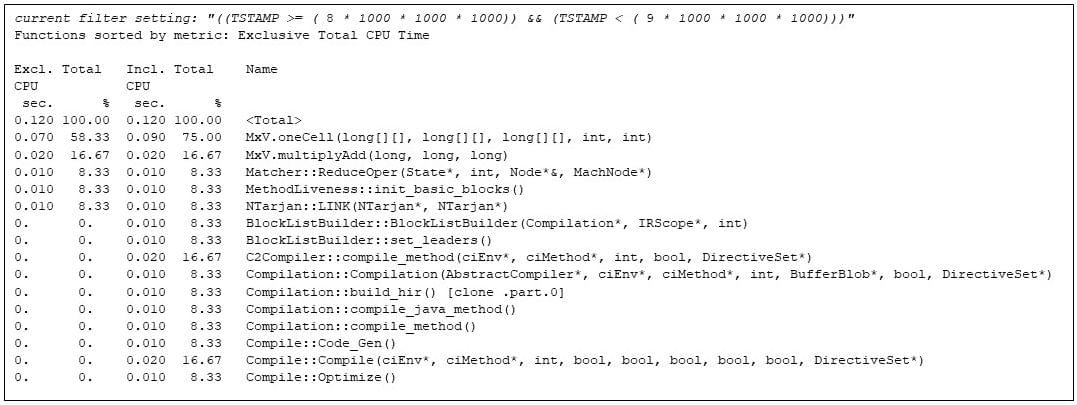
Iki paskutinio kartojimo matricos daugybos kodas visiškai išnaudoja „Java“ virtualią mašiną.
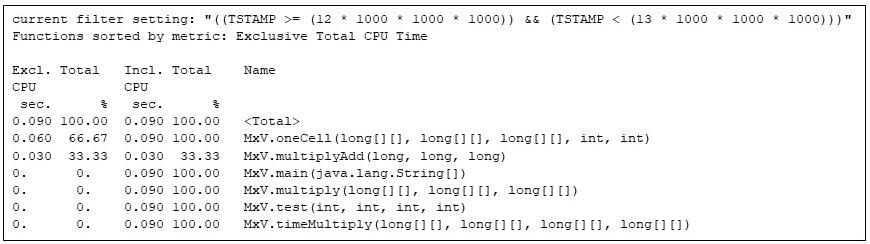
9 pav. Galutinis matricos daugybos programos pakartojimas, rodantis galutinę kodo konfigūraciją
Išvada
Parodžiau, kaip lengva gauti įžvalgos apie Java programų vykdymo laiką profiliuojant naudojant gprofng. Naudojant filtravimo funkciją gprofng Išnagrinėti eksperimentą pagal laiko pjūvius man leido išnagrinėti tik dominančias programos fazes. Pavyzdžiui, programos paskirstymo ir inicijavimo etapų neįtraukimas ir tik vieno programos pakartojimo rodymas, kol vykdymo laiko kompiliatorius veikia savo magiškai, o tai leido pabrėžti gerėjantį našumą, kai buvo palaipsniui kompiliuojamas karštasis kodas.
Papildoma literatūra
Skaitytojams, norintiems daugiau sužinoti apie gprofngyra šį tinklaraščio įrašą su įžanginiu vaizdo įrašu gprofngįskaitant instrukcijas, kaip ją įdiegti „Oracle Linux“.
Padėkos
Dėkoju Ruudui van der Pasui, Kurtui Goebeliui ir Vladimirui Mezentsevui už pasiūlymus ir techninę pagalbą, o Elenai Zannoni, Davidui Banmanui, Craig Hardy ir Dave'ui Neary'ui už paskatinimą rašyti šį tinklaraštį.
Pabaigos pastabos
1. Programos komandinės eilutės komponentų motyvai:
numactl --cpunodebind=0 --membind=0 --. Apribokite „Java“ virtualiosios mašinos naudojamą atmintį iki vieno NUMA mazgo branduolių ir atminties. Apribojus JVM iki vieno mazgo, sumažėja programos paleisties variantas.java. Naudoju jdk-17.0.4.1 OpenJDK versiją, skirtą aarch64.-XX:+UseParallelGC. Įjunkite lygiagretųjį šiukšlių rinktuvą, nes jis atlieka mažiausiai foninio darbo iš galimų surinkėjų.-Xms31g -Xmx31g. Suteikite pakankamai „Java“ objektų krūvos vietos, kad niekada nereikėtų surinkti šiukšlių.-Xlog:gc. Užregistruokite GC veiklą, kad patikrintumėte, ar kolekcija iš tikrųjų nereikalinga. („Tikėk, bet pasitikrink.”)-XX: -UsePerfData. Sumažinkite „Java“ virtualiosios mašinos išlaidas.
2. Paaiškinimai gprofng parinktys yra:
-limit 24. Rodyti tik 24 populiariausius metodus (čia surūšiuoti pagal išskirtinį procesoriaus laiką). Matau, kad 24 metodų rodymas mane pritraukia prie metodų, kuriems nereikia beveik laiko. Vėliau aš naudosiu 16 limitą tose vietose, kur 16 metodų nusileidžia į metodus, kurie prisideda prie nereikšmingo procesoriaus laiko. Kai kuriuose pavyzdžiuosegprofngpats riboja rodymą, nes nėra tiek daug metodų, kurie kaupia laiką.-viewmode expert. Rodyti visus metodus, kaupiančius procesoriaus laiką, ne tik „Java“ metodus, įskaitant metodus, kurie būdingi pačiam JVM. Naudodamas šią vėliavėlę galiu matyti vykdymo laiko kompiliatoriaus metodus ir kt.





