Didelės kalbos modeliai (LLM) greitai tapo pagrindine šiuolaikinių vartotojų ir įmonių programų dalimi. Tačiau greitos žetonų kartos poreikis tebėra nuolatinis iššūkis, dažnai tampantis naujų programų kliūtimi. Pavyzdžiui, naujausia išvados mastelio keitimo tendencija paieškai ir kitiems sudėtingiems algoritmams atlikti naudoja daug ilgesnius išėjimus, o kelių agentų ir konvejerinės LLM sistemos siekia padidinti tikslumą ir patikimumą, tačiau abi dažnai kenčia nuo ilgo atsako laiko dėl laukimo. keliems apdorojimo etapams. Šio pagreitinto žetonų generavimo poreikio patenkinimas yra labai svarbus siekiant nuolat tobulinti ir plačiai taikyti LLM pagrįstas programas.
Esami modeliais pagrįsti spekuliaciniai dekodavimo metodai turi apribojimų, trukdančių veiksmingai spręsti žetonų generavimo LLM spartinimo iššūkį. Pirma, šie metodai labai priklauso nuo juodraščio modelio dydžio ir kokybės, kuris ne visada gali būti prieinamas, todėl norint sukurti tinkamą modelį reikia brangiai apmokyti arba tiksliai suderinti. Antra, juodraščio modelių ir LLM integravimas į GPU gali sukelti komplikacijų ir neveiksmingumo, pvz., konfliktų tarp juodraščio modelio atminties naudojimo ir LLM raktinės vertės talpyklos. Siekiant išspręsti šias problemas, neseniai atliktas darbas buvo išnagrinėtas papildomų dekodavimo galvučių įtraukimas tiesiai į LLM, kad būtų galima atlikti spekuliacinį dekodavimą. Tačiau šie metodai vis dar susiduria su panašiais iššūkiais, nes papildomoms galvutėms reikia tiksliai suderinti kiekvieną LLM ir sunaudojama daug GPU atminties. Šių apribojimų įveikimas yra labai svarbus kuriant patikimesnius ir efektyvesnius metodus, kurie pagreitintų LLM išvadas.
Tyrėjai iš Snowflake AI Research ir Carnegie Mellon universiteto pristato Sufikso dekodavimastvirtas metodas be modelio, todėl nereikia juodraščių modelių ar papildomų dekodavimo galvučių. Užuot pasikliavę atskirais modeliais, „SuffixDecoding“ naudoja efektyvius priesagų medžio indeksus, sukurtus remiantis ankstesnėmis išvesties kartomis ir dabartine vykdoma išvadų užklausa. Procesas prasideda kiekvienos greito atsako poros žymėjimu naudojant LLM žodyną, ištraukiant visas galimas priesagas (pasekmes nuo bet kurios padėties iki galo), kad būtų sukurta priesagų medžio struktūra. Kiekvienas medžio mazgas reiškia prieigos raktą, o kelias nuo šaknies iki bet kurio mazgo atitinka seką, kuri pasirodė mokymo duomenyse. Šis be modelio metodas pašalina sunkumus ir GPU pridėtines išlaidas, susijusias su juodraščio modelių ar papildomų dekodavimo galvučių integravimu, o tai yra efektyvesnė alternatyva paspartinti LLM išvadas.
Kiekvienai naujai išvados užklausai SuffixDecoding sukuria atskirą užklausos priesagų medį iš dabartinių raginimo žetonų. Šis dizainas yra labai svarbus atliekant užduotis, kai tikimasi, kad LLM išvestis nurodys arba pakartotinai naudos turinį iš įvesties eilutės, pvz., dokumento apibendrinimą, atsakymus į klausimus, kelių pokalbių pokalbius ir kodo redagavimą. Priesagų medis palaiko dažnių skaičių kiekviename mazge, kad būtų galima stebėti, kaip dažnai atsiranda skirtingų žetonų sekos, todėl galima efektyviai suderinti šabloną. Atsižvelgiant į bet kokią naujausių dabartinės kartos žetonų seką, „SuffixDecoding“ gali greitai pereiti medį, kad surastų visus galimus tęsinius, kurie pasirodė raginimuose arba ankstesniuose išvestiuose. Kiekviename išvados etape „SuffixDecoding“ parenka geriausią (-ius) tęsinių žetonų pomedį (-ius), remdamasi dažnio statistika ir empirine tikimybe. Tada šie spėlioti žetonai perduodami LLM patikrinti, o tai atliekama vienu perėjimu į priekį dėka medžio dėmesio operatoriaus su topologiją suvokiančia priežastinio ryšio kauke.

Panašiai kaip ir ankstesniame darbe, pvz., LLMA ir Prompt Lookup Decoding, „SuffixDecoding“ yra be modelio metodas, kuris pateikia kandidatų sekas iš pamatinio korpuso. Tačiau, skirtingai nuo ankstesnių metodų, kuriuose buvo atsižvelgta tik į mažus nuorodos tekstus, pvz., keletą fragmentų arba tik dabartinį raginimą, SuffixDecoding sukurtas naudoti daug didesnio masto korpusą, kurį sudaro šimtai ar net tūkstančiai anksčiau sugeneruotų išėjimų.
Naudodamas šį didesnį atskaitos korpusą, „SuffixDecoding“ gali principingiau panaudoti dažnių statistiką, kad pasirinktų galimas kandidatų sekas. Kad būtų galima greitai sukurti šias kandidatų sekas, „SuffixDecoding“ savo nuorodos korpuse sukuria priesagų medį. Šakninis medžio mazgas reiškia priesagos pradžią iš bet kurio korpuso dokumento, kur dokumentas yra ankstesnės išvados išvestis arba dabartinės vykstančios išvados raginimas ir išvestis. Kelias nuo šaknies iki kiekvieno mazgo reiškia poseką, kuri rodoma atskaitos korpuse, o kiekvienas antrinis mazgas reiškia galimą prieigos rakto tęsinį.
SuffixDecoding naudoja šią priesagų medžio struktūrą, kad atliktų efektyvų modelio atitikimą. Atsižvelgiant į eilutę ir sugeneruotus dabartinės išvados žetonus, ji identifikuoja šablonų seką ir eina priesagų medyje, kad surastų visus galimus tęsinius, kurie pasirodė nuorodos korpuse. Nors tai gali sukurti didelį kandidatų sekų rinkinį, „SuffixDecoding“ taiko godų išplėtimo ir balų nustatymo procedūrą, kad sukurtų mažesnį, labiau tikėtiną spekuliacijos medį, kuris vėliau naudojamas paskutiniame medžiu pagrįsto spekuliacinio dekodavimo žingsnyje.
Galutiniai eksperimentiniai rezultatai parodo suffixDecoding metodo pranašumus. „AgenticSQL“ duomenų rinkinyje, kuris atspindi sudėtingą kelių pakopų LLM konvejerį, „SuffixDecoding“ pasiekia iki 2,9 karto didesnį išvesties pralaidumą ir iki 3 kartų mažesnę laiko per raktą (TPOT) delsą, palyginti su „SpecInfer“ bazine linija. Atliekant atviresnes užduotis, pvz., pokalbius ir kodų generavimą, „SuffixDecoding“ vis tiek užtikrina didelį našumą, iki 1,4 karto didesnį pralaidumą ir 1,1 karto mažesnį TPOT delsą nei „SpecInfer“.
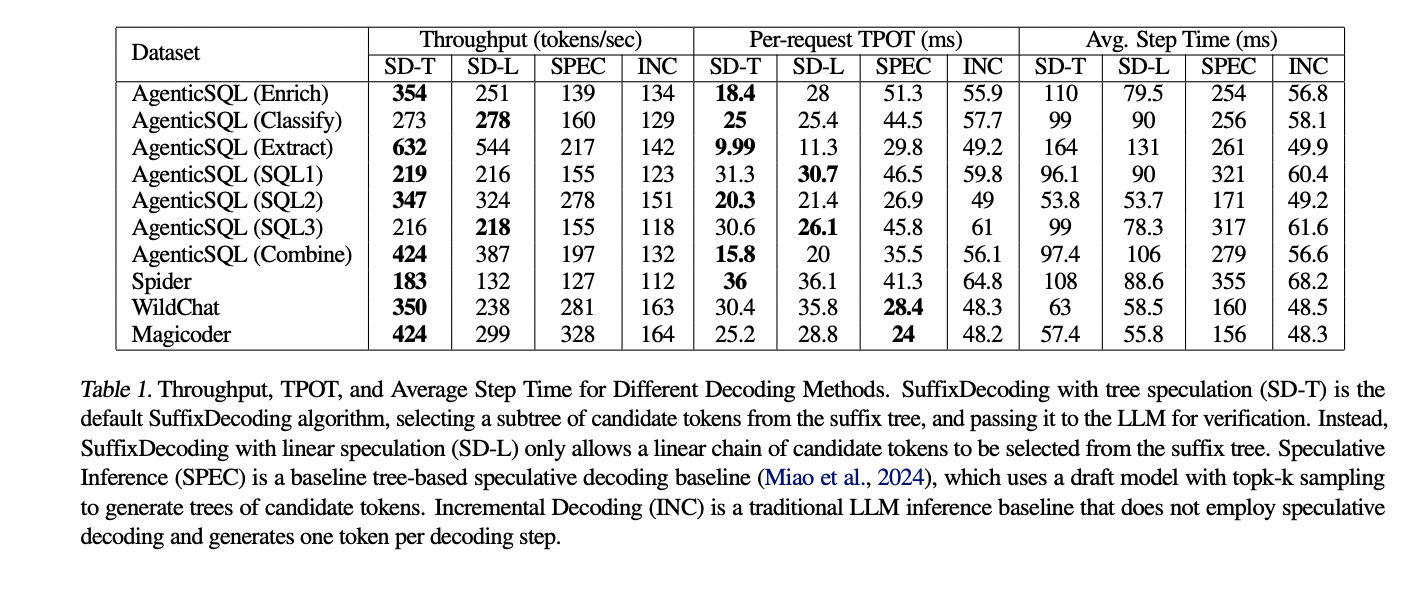
Vertinant taip pat nagrinėjamas „SuffixDecoding“ spekuliacinio dekodavimo galimybių efektyvumas. SuffixDecoding gali pasiekti žymiai didesnį vidutinį priimtų spėliojamų žetonų skaičių per vieną patvirtinimo veiksmą, palyginti su juodraščiu paremtu SpecInfer metodu. Tai rodo, kad „SuffixDecoding“ priesagų medžio struktūra be modelio leidžia tiksliau ir patikimiau generuoti spekuliacinį prieigos raktą, maksimaliai padidindama galimą spekuliacinio dekodavimo pagreitį, nereikalaujant atskiro modelio juodraščio priežiūros.


Šis darbas pristato SuffixDekodavimasbe modelio metodas, skirtas paspartinti LLM išvadas, naudojant priesagų medžius, sukurtus iš ankstesnių išėjimų. „SuffixDecoding“ pasiekia konkurencingą greitį, palyginti su esamais modeliais pagrįstais spekuliaciniais dekodavimo metodais, esant įvairiems darbo krūviams, ir yra ypač tinkamas sudėtingiems, daugiapakopiams LLM vamzdynams. SuffixDecoding, padidindamas atskaitos korpuso mastelį, o ne pasikliaudamas modelių juodraščiais, demonstruoja tvirtą kryptį, kaip pagerinti spekuliacinio dekodavimo efektyvumą ir išnaudoti visą didelių kalbų modelių potencialą realiose programose.
Patikrinkite Išsami informacija čia. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(NEMOKAMAS AI internetinis seminaras) Sumanaus dokumentų apdorojimo su GenAI įgyvendinimas finansinių paslaugų ir nekilnojamojo turto sandoriuose
Asjadas yra „Marktechpost“ konsultantas. Jis tęsia mechanikos inžinerijos bakalauro laipsnį Indijos technologijos institute Kharagpur mieste. Asjadas yra mašininio mokymosi ir gilaus mokymosi entuziastas, nuolat tyrinėjantis mašininio mokymosi taikymą sveikatos priežiūros srityje.
🐝🐝 Artėjantis tiesioginis LinkedIn renginys „Viena platforma, daugiarūšės galimybės“, kuriame „Encord“ generalinis direktorius Ericas Landau ir produktų inžinerijos vadovas Justinas Sharpsas kalbės, kaip jie iš naujo išranda duomenų kūrimo procesą, kad padėtų komandoms greitai kurti žaidimus keičiančius multimodalinius AI modelius.