

Kalbos modelio maršruto parinkimas yra auganti sritis, orientuota į didelių kalbų modelių (LLM) panaudojimo įvairioms užduotims optimizavimą. Šie modeliai, apimantys teksto generavimą, apibendrinimą ir argumentavimą, vis dažniau taikomi įvairiems įvesties duomenims. Galimybė dinamiškai nukreipti konkrečias užduotis į tinkamiausią modelį tapo esminiu iššūkiu, siekiant suderinti efektyvumą ir tikslumą atliekant šias įvairiapuses užduotis.
Vienas iš pagrindinių iššūkių diegiant LLM yra tinkamiausio modelio pasirinkimas konkrečiai įvesties užduočiai. Nors yra daug iš anksto apmokytų LLM, jų našumas gali labai skirtis atsižvelgiant į užduotį. Nustatant, kurį modelį naudoti konkrečiai įvestiei, tradiciškai reikia pasikliauti pažymėtais duomenų rinkiniais arba žmogaus komentarais. Šie daug išteklių reikalaujantys metodai kelia didelių kliūčių mastelio keitimui ir apibendrinimui, ypač tais atvejais, kai reikia priimti sprendimus realiuoju laiku arba turėti įvairių galimybių.
Esami užduočių nukreipimo į LLM metodai paprastai apima pagalbinį mokymą arba euristine pagrįstą atranką. Šie metodai dažnai priklauso nuo pažymėtų duomenų rinkinių, kad būtų galima įvertinti arba numatyti veiksmingiausią tam tikros įvesties modelį. Nors šios strategijos tam tikru mastu yra veiksmingos, jas riboja aukštos kokybės anotuotų duomenų prieinamumas ir pagalbinių modelių mokymo sąnaudos. Dėl to platesnis šių metodų pritaikymas išlieka ribotas.
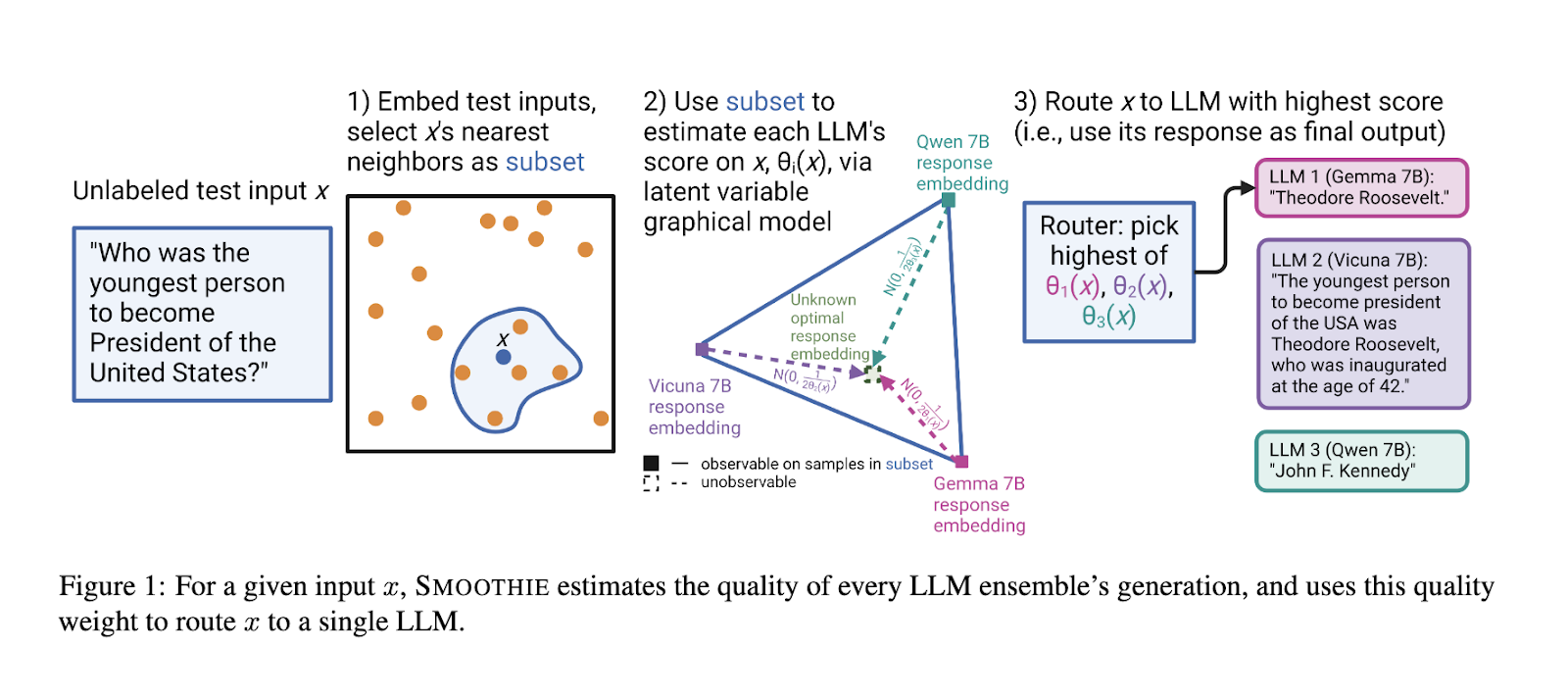
Tyrėjai iš Stanfordo universiteto pristatė SMOOTHIE – naujovišką neprižiūrimo kalbos modelio maršruto parinkimo metodą, skirtą įveikti pažymėtų duomenų apribojimus. SMOOTHIE naudoja silpnos priežiūros principus, naudodamas latentinį kintamąjį grafinį modelį, kad įvertintų kelių LLM rezultatus. Įvertinus konkrečių mėginių kokybės balus, metodas nukreipia kiekvieną įvestį į LLM, kuri greičiausiai duos optimalius rezultatus. Šis metodas suteikia naują sprendimą, pašalindamas priklausomybę nuo pažymėtų duomenų rinkinių ir žymiai sumažindamas išteklių poreikius.
SMOOTHIE susideda iš dviejų pagrindinių variantų: SMOOTHIE-GLOBAL ir SMOOTHIE-LOCAL. SMOOTHIE-GLOBAL išveda visų bandymų duomenų kokybės įvertinimus ir sukuria platų modelio veikimo įvertinimą. Ir atvirkščiai, SMOOTHIE-LOCAL patobulina šį procesą, sutelkdama dėmesį į artimiausius mėginio kaimynus įdėjimo erdvėje, padidindama maršruto parinkimo tikslumą. Metodika naudoja stebimų išėjimų ir latentinių kintamųjų įterpimą, kad būtų modeliuojami skirtumai tarp sugeneruotų ir hipotetinių tikrųjų išėjimų. Šie skirtumai pateikiami kaip daugiamatis Gauso, leidžiantis tyrėjams gauti uždaros formos kokybės balų įverčius. Metodas taip pat apima branduolio išlyginimą SMOOTHIE-LOCAL, kad būtų galima toliau pritaikyti atskirų pavyzdžių kokybės įvertinimus ir užtikrinti, kad sprendimai dėl maršruto būtų dinamiškai optimizuoti.
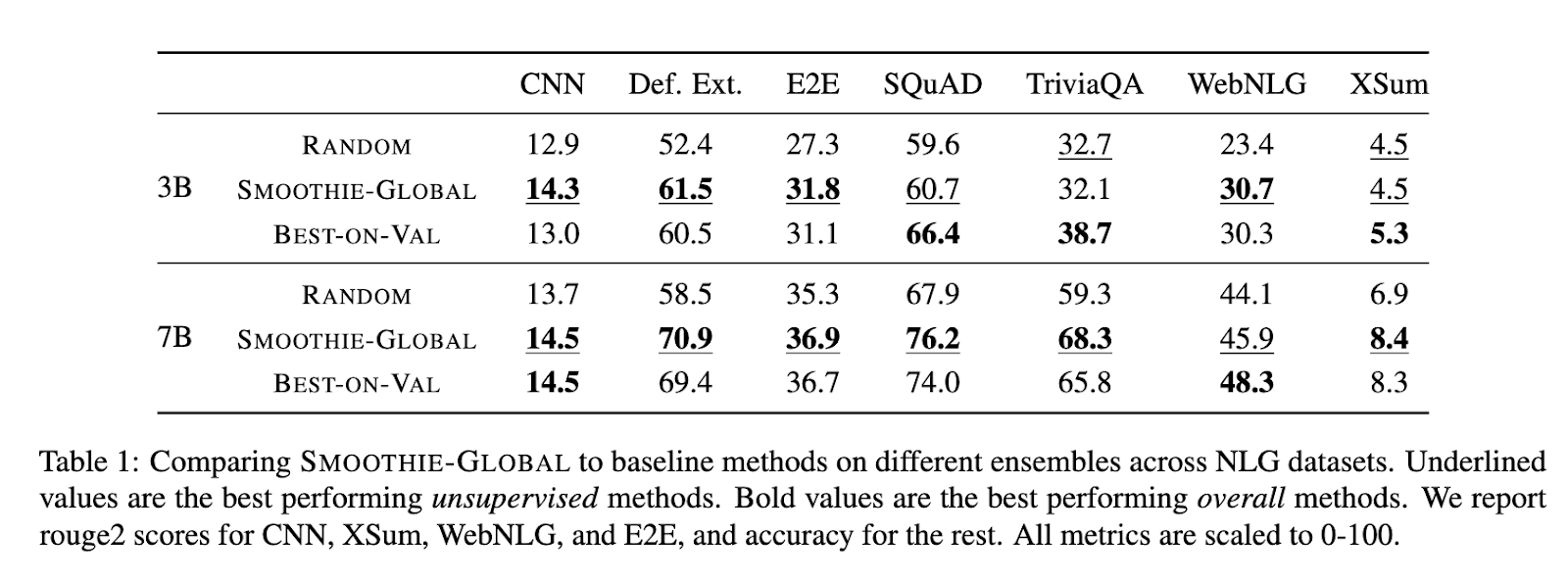
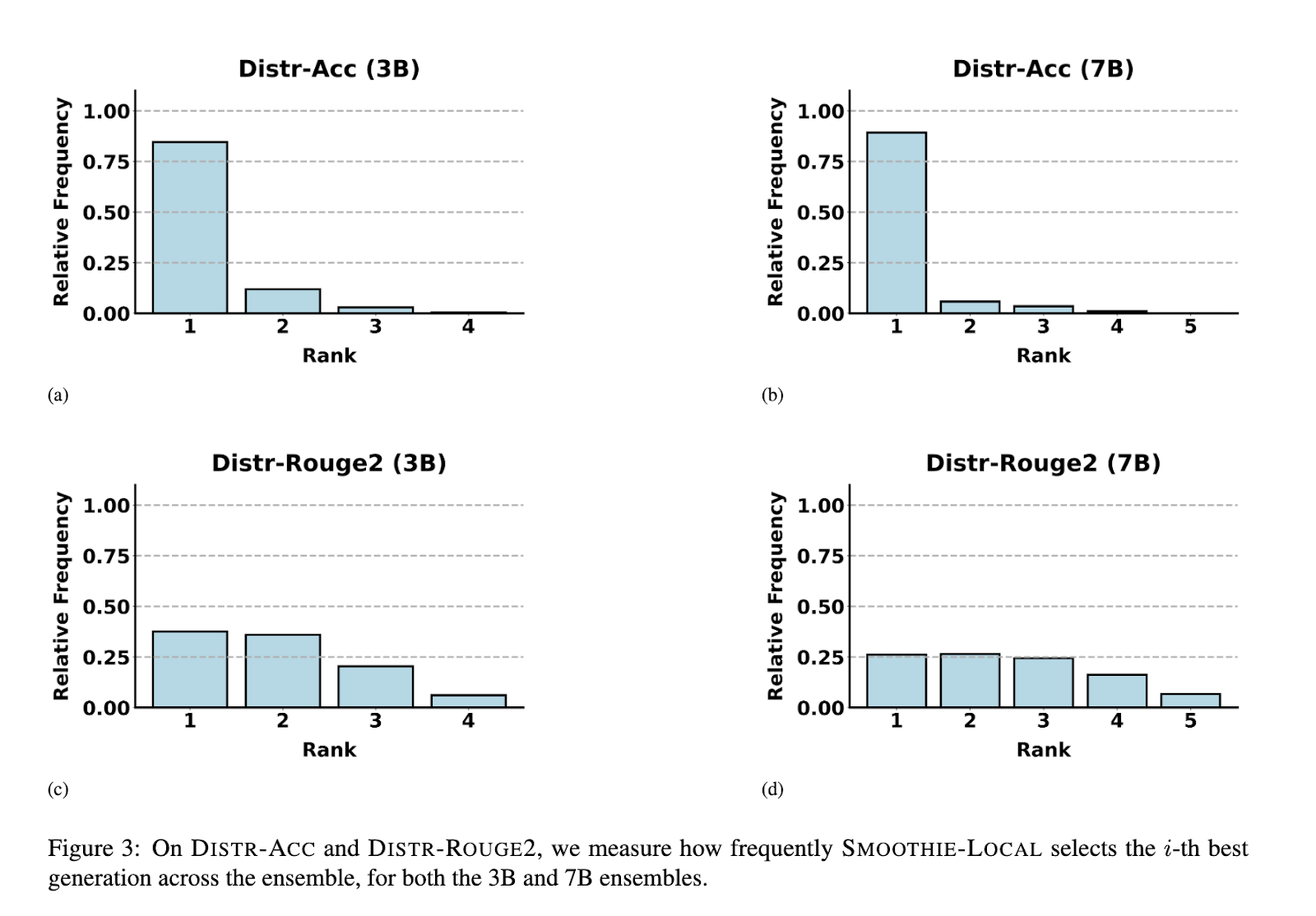
SMOOTHIE našumas buvo plačiai įvertintas keliuose duomenų rinkiniuose ir nustatymuose. SMOOTHIE-GLOBAL 9 iš 14 užduočių pademonstravo savo gebėjimą nustatyti geriausiai veikiantį modelį. Pavyzdžiui, duomenų rinkiniuose, tokiuose kaip AlpacaEval, SMOOTHIE-GLOBAL pagerino laimėjimų rodiklius iki 15 procentinių punktų, palyginti su atsitiktinės atrankos bazinėmis linijomis, ir 8 punktais SQuAD. LOCAL variantas dar labiau pasižymėjo, pranokdamas visuotinius ir prižiūrimus maršruto parinkimo metodus kelių užduočių scenarijuose. Mišrių užduočių duomenų rinkiniuose SMOOTHIE-LOCAL pagerino užduočių tikslumą iki 10 taškų, palyginti su pradiniais metodais. Be to, jis pasiekė stiprią koreliaciją tarp apskaičiuotos ir faktinės modelio kokybės, o rango koreliacijos koeficientas buvo 0,72 natūralios kalbos generavimo užduotyse ir 0,94 naudojant MixInstruct. SMOOTHIE vietinis maršruto parinkimas leido mažesniems modeliams keliose konfigūracijose pranokti didesnius modelius, o tai išryškino efektyvumą naudojant efektyvius išteklius naudojančius scenarijus.
Rezultatai pabrėžia SMOOTHIE potencialą pakeisti LLM maršrutą sprendžiant priklausomybę nuo pažymėtų duomenų ir pagalbinio mokymo. Silpnų priežiūros metodų derinimas su naujoviškais kokybės įvertinimo modeliais leidžia priimti patikimus ir veiksmingus maršruto sprendimus daugelio galimybių aplinkoje. Tyrimas pristato keičiamo dydžio ir praktišką sprendimą, kaip pagerinti LLM našumą, atveriantį kelią platesniam pritaikymui realiame pasaulyje, kur svarbiausia užduočių įvairovė ir tikslumas.
Šis tyrimas reiškia esminį pažangą kalbos modelio maršruto parinkimo srityje. Sprendžiant iššūkius, kylančius renkantis konkrečioms užduotims skirtą LLM, taikant neprižiūrimą metodą, atsiveria galimybės pagerinti LLM diegimą įvairiose programose. SMOOTHIE įdiegimas supaprastina procesą ir užtikrina reikšmingą produkcijos kokybės pagerėjimą, parodydamas didėjantį silpnos dirbtinio intelekto priežiūros potencialą.
Patikrinkite į Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Nikhilas yra „Marktechpost“ konsultantas. Indijos technologijos institute Charagpūre jis siekia integruoto dvigubo medžiagų studijų laipsnio. Nikhilas yra AI/ML entuziastas, kuris visada tiria pritaikymą tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagų mokslo išsilavinimą, jis tyrinėja naujus pasiekimus ir kuria galimybes prisidėti.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)





