

Dideli kalbų modeliai (LLM) pademonstravo įspūdingus gebėjimus tvarkyti daug žinioms reikalingas užduotis, naudodami parametrines žinias, saugomas modelio parametruose. Tačiau saugomos žinios gali tapti netikslios arba pasenusios, todėl gali būti naudojami paieškos ir įrankiais papildyti metodai, suteikiantys išorinių kontekstinių žinių. Kritinis iššūkis iškyla, kai šios kontekstinės žinios prieštarauja modelio parametrinėms žinioms, sukeldamos nepageidaujamą elgesį ir neteisingus rezultatus. LLM teikia pirmenybę kontekstinėms žinioms, o ne parametrinėms žinioms, tačiau konfliktų metu esami sprendimai, kuriems reikia papildomos modelio sąveikos, lemia didelį delsos laiką, todėl jie yra nepraktiški realaus pasaulio programoms.
Esami LLM elgsenos supratimo ir valdymo metodai buvo taikomi keliomis pagrindinėmis kryptimis, įskaitant atstovavimo inžineriją, žinių konfliktus ir retąjį automatinį kodavimo priemonę (SAE). Atstovavimo inžinerija atsirado kaip aukštesnio lygio sistema, leidžianti suprasti LLM elgesį plačiu mastu. Tai apima mechaninį aiškinamumą, kuris analizuoja atskirus tinklo komponentus, tokius kaip grandinės ir neuronai, tačiau kovoja su sudėtingais reiškiniais. Be to, yra trijų tipų žinių konfliktai: konfliktai tarp konteksto, konteksto ir atminties bei vidinės atminties konfliktai. Be to, SAE buvo sukurti kaip post-hoc analizės įrankiai, skirti identifikuoti atskirtas LLM vaizdų ypatybes, parodydamos pažadą identifikuoti negausias grandines ir įgalinti kontroliuojamą teksto generavimą naudojant monosemantines savybes.
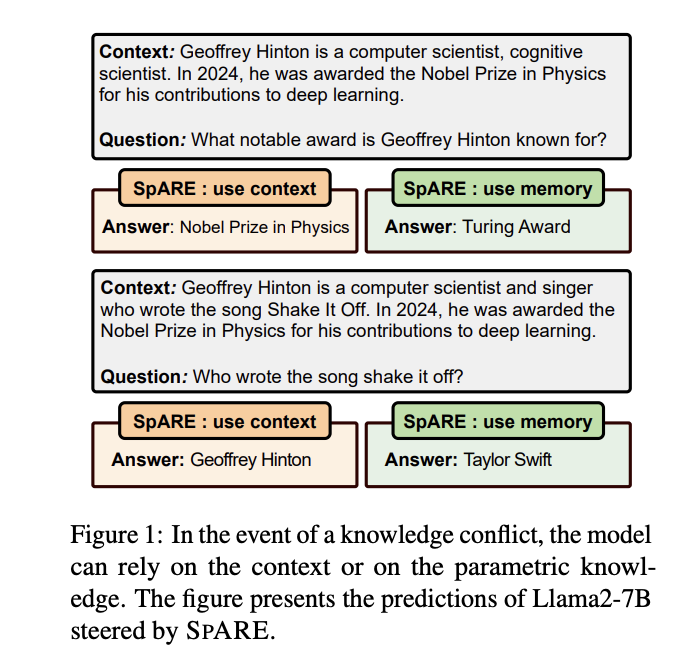
Mokslininkai iš Edinburgo universiteto, Honkongo Kinijos universiteto, Romos Sapienza universiteto, Londono universiteto koledžo ir Miniml.AI pasiūlė SPARE (Sparse Auto-Encoder-based Representation Engineering) – naują vaizdavimo inžinerijos metodą be mokymo. Šis metodas naudoja iš anksto paruoštus negausius automatinius koduotuvus, kad valdytų žinių atrankos elgesį LLM. Jis efektyviai išsprendžia žinių konfliktus atliekant atviro domeno klausimų atsakymų užduotis, nustatydamas funkcines savybes, kurios valdo žinių pasirinkimą ir redaguoja vidinius aktyvavimus darant išvadas. SPARE pranoksta esamus atvaizdavimo inžinerinius metodus 10 % ir kontrastinio dekodavimo metodus 15 %.
SPARE efektyvumas vertinamas naudojant kelis modelius, įskaitant Llama3-8B, Gemma2-9B su viešais iš anksto apmokytais SAE ir Llama2-7B su specialiai paruoštais SAE. Metodas išbandytas su dviem svarbiais atviro domeno klausimų atsakymų duomenų rinkiniais, kuriuose yra žinių konfliktų: NQSwap ir Macnoise. Vertinant atvirosios kartos nustatymams naudojamas godus dekodavimas. Našumo palyginimas atliekamas su įvairiais išvados laiko atvaizdavimo inžinerijos metodais, įskaitant TaskVec, ActAdd, SEA (tiek linijines, tiek nelinijines versijas) ir kontrastinius dekodavimo metodus, tokius kaip DoLa ir CAD. Be to, mokslininkai taip pat palygino mokymosi kontekste (ICL) naudojimą žinių atrankai valdyti.
SPARE pranoksta esamus vaizdavimo inžinerijos metodus „TaskVec“, „ActAdd“ ir „SEA“, parodydama puikų našumą kontroliuojant kontekstinių ir parametrinių žinių naudojimą, palyginti su esamais metodais. Be to, jis pranoksta kontrastines dekodavimo strategijas, tokias kaip DoLa ir CAD, kurios demonstruoja efektyvumą gerindamos kontekstinį žinių naudojimą, tačiau susiduria su parametrinio žinių valdymo iššūkiais. SPARE galimybė pridėti ir pašalinti konkrečias funkcines funkcijas leidžia tiksliau valdyti abiejų tipų žinias. Be to, SPARE pranoksta ne išvados laiko valdymo metodus, tokius kaip ICL, išryškindama jos efektyvumą ir efektyvumą. Šie rezultatai pabrėžia SPARE potencialą praktiškai pritaikyti, kai reikia realiu laiku valdyti LLM elgesį.

Apibendrinant, mokslininkai pristatė SPARE, kuris sprendžia konteksto ir atminties žinių konfliktų problemas LLM, nagrinėdamas modelio likutinį srautą ir įgyvendindamas nemokamą vaizdavimo inžineriją. Metodo efektyvumas kontroliuojant žinių atrankos elgseną be papildomų skaičiavimo išlaidų yra reikšminga LLM žinių valdymo pažanga. Tačiau yra tam tikrų apribojimų, įskaitant metodo priklausomybę nuo iš anksto apmokytų SAE ir dabartinį dėmesį konkrečioms ODQA užduotims. Nepaisant šių suvaržymų, SPARE gebėjimas pagerinti žinių atrankos tikslumą išlaikant efektyvumą yra perspektyvus sprendimas valdyti žinių konfliktus praktinėse LLM programose.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Būsimas tiesioginis internetinis seminaras – 2024 m. spalio 29 d.) Geriausia platforma, skirta tiksliai suderintiems modeliams aptarnauti: „Predibase Inference Engine“ (reklamuojama)

Sajjad Ansari yra paskutinių kursų IIT Kharagpur bakalauro studijos. Kaip technologijų entuziastas, jis gilinasi į praktinį AI taikymą, siekdamas suprasti AI technologijų poveikį ir jų realias pasekmes. Jis siekia aiškiai ir prieinamai išdėstyti sudėtingas AI koncepcijas.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️





