
Tyrėjai iš Stanfordo, EPFL ir UNC pristatyti „Silpnas už stiprų pajungimą“, W4Snaują sustiprinimo mokymosi RL sistemą, kuri apmoko nedidelį metaagentą kurti ir tobulinti kodo darbo eigas, kurios vadina stipresnį vykdytojo modelį. Metaagentas nesuderina stipraus modelio, jis išmoksta jį orkestruoti. W4S formalizuoja darbo eigos dizainą kaip kelių pakopų Markovo sprendimų procesą ir apmoko metaagentą metodu, vadinamu Sustiprinimo mokymasis agentų darbo eigos optimizavimui, RLAO. Tyrėjų komanda praneša apie nuoseklų 11 etalonų pranašumą, kai 7B metaagentas buvo apmokytas maždaug 1 GPU valandą.
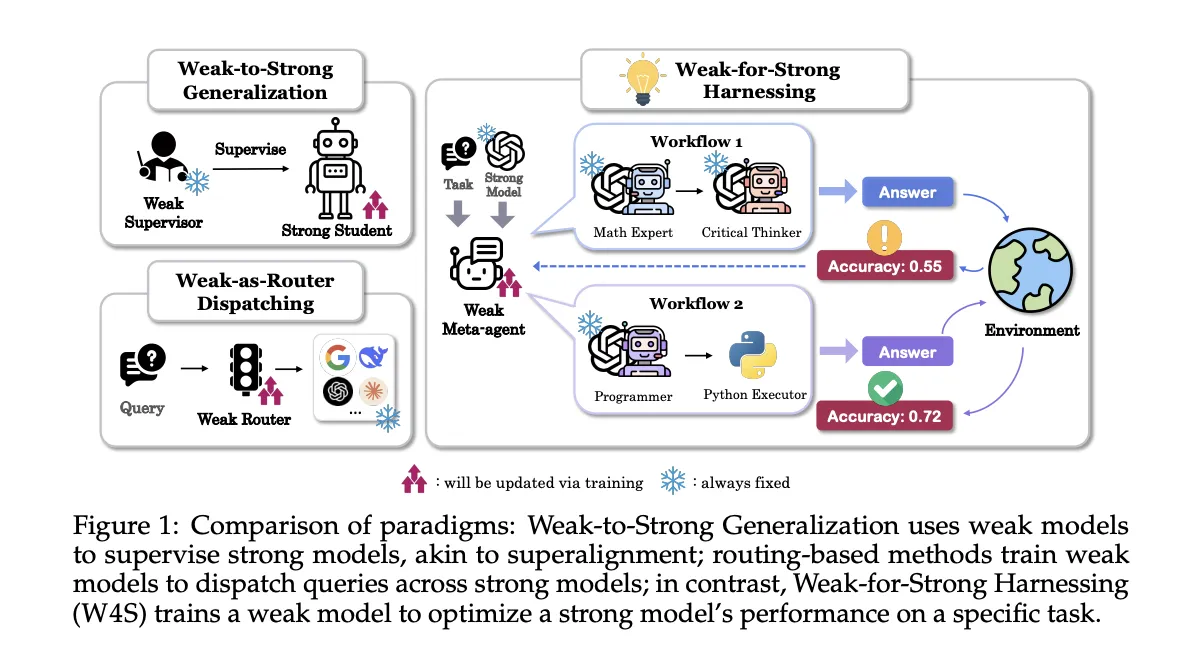
W4S veikia pakaitomis. Būsenoje yra užduočių instrukcijos, dabartinė darbo eigos programa ir atsiliepimai iš ankstesnių vykdymų. Veiksmą sudaro 2 komponentai, analizė, ką keisti, ir naujas Python darbo eigos kodas, įgyvendinantis tuos pakeitimus. Aplinka vykdo patvirtinimo elementų kodą, grąžina tikslumo ir gedimo atvejus bei pateikia naują būseną kitam posūkiui. Meta agentas gali atlikti greitą vieno pavyzdžio savitikrą, jei atsiranda klaidų, jis bando iki 3 taisyti, jei klaidos išlieka, veiksmas praleidžiamas. Ši kilpa suteikia mokymosi signalą neliesdama stipraus vykdytojo svorių.
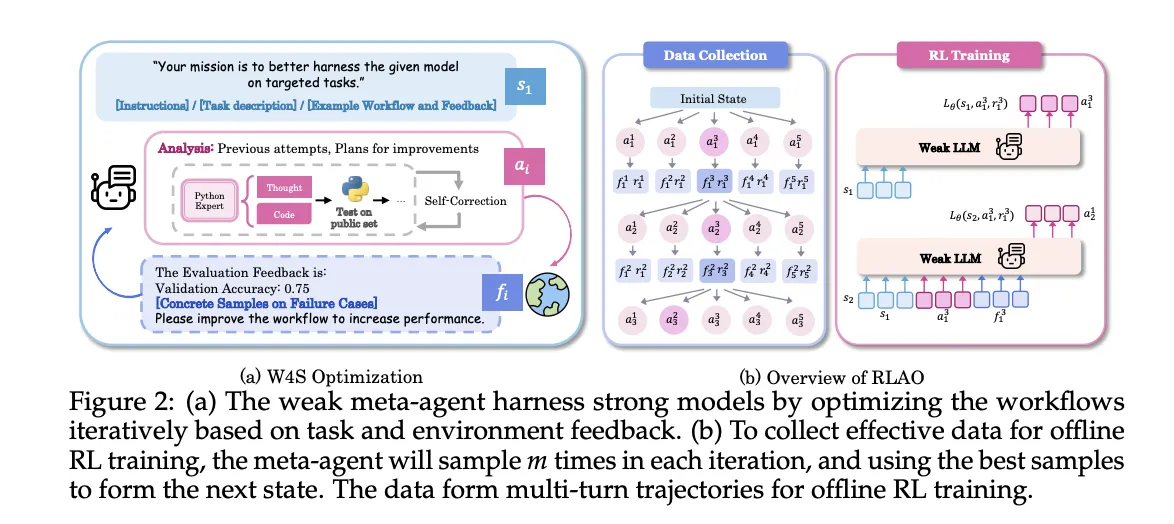
W4S veikia kaip pasikartojantis ciklas
- Darbo eigos generavimas: Silpnas meta agentas rašo naują darbo eigą, kuri naudoja stiprų modelį, išreikštą kaip vykdomąjį Python kodą.
- Vykdymas ir atsiliepimai: stiprus modelis vykdo patvirtinimo pavyzdžių darbo eigą, tada pateikia tikslumo ir klaidų atvejus kaip grįžtamąjį ryšį.
- Patikslinimas: metaagentas naudoja atsiliepimus analizei ir darbo eigai atnaujinti, tada pakartoja ciklą.
Sustiprinimo mokymasis agentų darbo eigos optimizavimui (RLAO)
RLAO yra neprisijungus naudojama sustiprinimo mokymosi procedūra kelių posūkių trajektorijomis. Kiekvienos iteracijos metu sistema atrenka kelis galimus veiksmus, išlaiko geriausiai veikiančius veiksmus, kad pagerintų būseną, o kitus išsaugo mokymui. Politika optimizuota naudojant atlygio svertinę regresiją. Atlygis yra nedidelis ir lygina dabartinį patvirtinimo tikslumą su istorija, didesnis svoris suteikiamas, kai naujas rezultatas lenkia ankstesnį geriausią, mažesnis svoris suteikiamas, kai jis įveikia paskutinę iteraciją. Šis tikslas skatina nuolatinę pažangą, tuo pačiu kontroliuojant žvalgymo išlaidas.
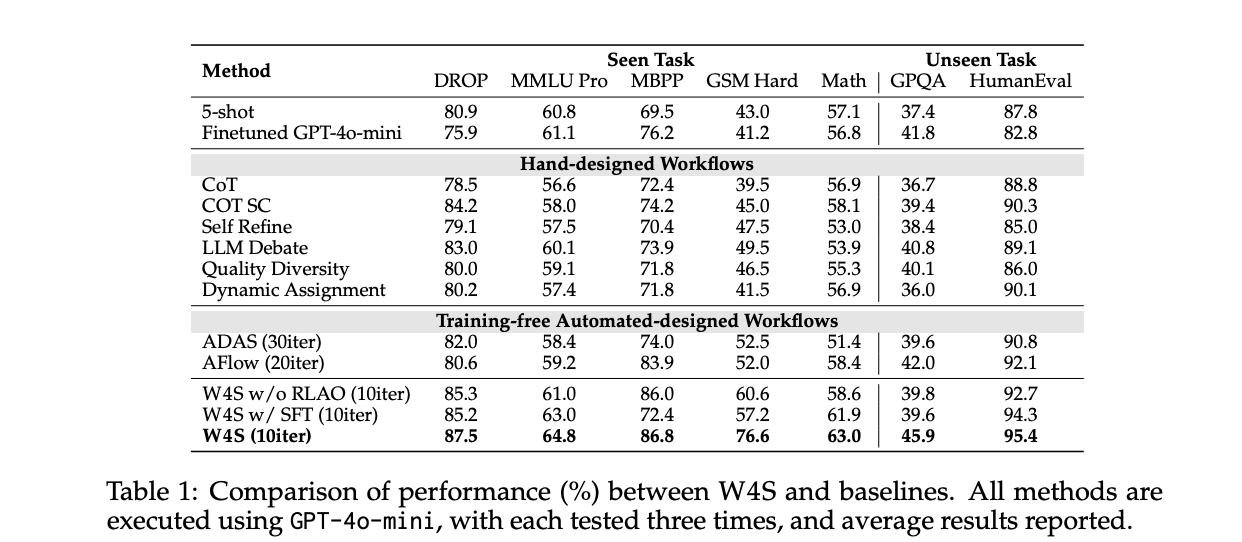
Rezultatų supratimas
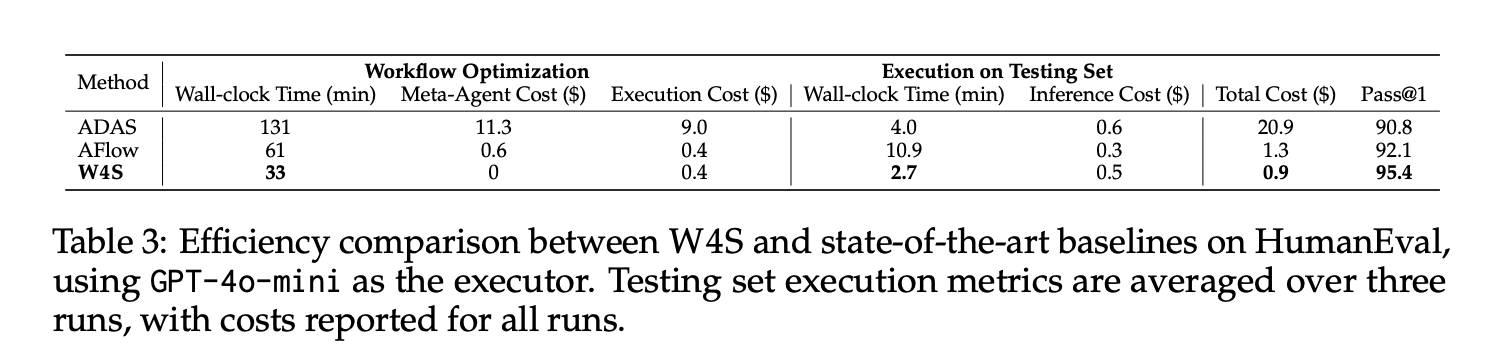
„HumanEval“, kai vykdytojas yra GPT-4o-mini, W4S pasiekia Pass@1 95,4, optimizuojant apie 33 minutes darbo eigos, nulinės metaagentės API sąnaudos, optimizavimo vykdymo sąnaudos apie 0,4 dolerio ir maždaug 2,7 minutės atlikti bandymo rinkinį, kurio kaina yra apie 0,5 USD, iš viso 9 USD. Pagal tą patį vykdytoją AFlow ir ADAS seka šį skaičių. Nurodytas vidutinis padidėjimas, palyginti su stipriausia automatizuota bazine linija, svyruoja nuo 2,9% iki 24,6% per 11 etalonų.
Matematinis perkėlimas metaagentas apmokomas GSM Plus ir MGSM su GPT-3.5-Turbo kaip vykdytojas, tada įvertinamas GSM8K, GSM Hard ir SVAMP. Straipsnyje teigiama, kad 86,5 GSM8K ir 61,8 GSM Hard, abu viršija automatines bazines linijas. Tai rodo, kad išmokta orkestruotė perkeliama į susijusias užduotis nepermokant vykdytojo.
Pagal matytas užduotis, kai vykdytojas yra GPT-4o-mini, W4S pranoksta nemokamus automatizuotus metodus, kurie neišmoksta planuotojo. Tyrimas taip pat vykdo abliacijas, kai metaagentas yra apmokomas prižiūrint koreguojant, o ne RLAO. RLAO agentas užtikrina didesnį tikslumą esant tuo pačiu skaičiavimo biudžetui. Tyrėjų grupė apima GRPO pradinį lygį pagal 7B silpną GSM Hard modelį, W4S lenkia jį esant ribotam skaičiavimui.
Iteracijos biudžetai yra svarbūs. Tyrėjų komanda nustato W4S maždaug 10 optimizavimo apsisukimų pagrindinėse lentelėse, o AFlow – apie 20, o ADAS – apie 30 apsisukimų. Nepaisant mažiau posūkių, W4S pasiekia didesnį tikslumą. Tai rodo, kad išmoktas planavimas per kodą ir patvirtinimo grįžtamasis ryšys daro paiešką veiksmingesnę.
Raktai išsinešti
- W4S apmoko 7B silpną metaagentą su RLAO, kad galėtų rašyti Python darbo eigas, kuriose naudojami stipresni vykdytojai, modeliuojami kaip kelių pasukimų MDP.
- HumanEval su GPT 4o mini kaip vykdytojas, W4S pasiekia Pass@1 iš 95,4, su maždaug 33 minučių optimizavimu ir maždaug 0,9 USD bendra kaina, pranokdama automatizuotas bazines linijas pagal tą patį vykdytoją.
- Pagal 11 etalonų W4S pagerėjo 2,9 % iki 24,6 %, palyginti su stipriausia bazine linija, tačiau išvengiama tikslaus stipraus modelio derinimo.
- Metodas vykdo kartotinę kilpą, sugeneruoja darbo eigą, vykdo ją pagal patvirtinimo duomenis, tada patikslina naudodamas grįžtamąjį ryšį.
- ADAS ir AFlow taip pat programuoja arba ieško per kodo darbo eigas, W4S skiriasi tuo, kad moko planuotoją, kuris mokosi neprisijungus.
W4S orientuojasi į orkestravimą, o ne modelio svarmenis ir apmoko 7B meta agentą programuoti darbo eigas, kurios iškviečia stipresnius vykdytojus. W4S formalizuoja darbo eigos dizainą kaip kelių eilių MDP ir optimizuoja planuotoją su RLAO, naudodamas neprisijungus naudojamas trajektorijas ir atlygio svertinę regresiją. Pateikti rezultatai rodo, kad „HumanEval“ su GPT 4o mini pasiektas 1 iš 95,4, vidutinis padidėjimas nuo 2,9% iki 24,6% per 11 etalonų ir apie 1 GPU valanda mokymo meta agentui. Kadravimas aiškiai lyginamas su ADAS ir AFlow, kuriuos paieškos agentas kuria arba koduoja grafikus, o W4S pataiso vykdytoją ir išmoksta planuotoją.
Patikrinkite Techninis popierius ir GitHub Repo. Nedvejodami peržiūrėkite mūsų „GitHub“ puslapis, skirtas mokymo priemonėms, kodams ir užrašų knygelėms. Be to, nedvejodami sekite mus Twitter ir nepamirškite prisijungti prie mūsų 100 000+ ML SubReddit ir Prenumeruoti mūsų naujienlaiškis. Palauk! ar tu telegramoje? dabar galite prisijungti prie mūsų ir per telegramą.

Michal Sutter yra duomenų mokslo profesionalas, Paduvos universiteto duomenų mokslo magistro laipsnis. Turėdamas tvirtą statistinės analizės, mašininio mokymosi ir duomenų inžinerijos pagrindą, Michal puikiai sugeba sudėtingus duomenų rinkinius paversti įgyvendinamomis įžvalgomis.
🙌 Sekite MARKTECHPOST: pridėkite mus kaip pageidaujamą „Google“ šaltinį.




