

Vizos ir kalbos navigacija (VLN) sujungia vizualinį suvokimą su natūralios kalbos supratimu, kad agentai būtų nukreipti į 3D aplinką. Tikslas – leisti agentams sekti į žmones panašias instrukcijas ir efektyviai naršyti sudėtingose erdvėse. Tokios pažangos turi potencialą robotikoje, papildytoje realybėje ir išmaniųjų asistentų technologijose, kur kalbinės instrukcijos vadovauja sąveikai su fizinėmis erdvėmis.
Pagrindinė VLN tyrimų problema yra tai, kad trūksta aukštos kokybės anotuotų duomenų rinkinių, kurie susieja navigacijos trajektorijas su tiksliomis natūralios kalbos instrukcijomis. Norint komentuoti šiuos duomenų rinkinius rankiniu būdu, reikia daug išteklių, patirties ir pastangų, todėl procesas yra brangus ir reikalauja daug laiko. Be to, šios anotacijos dažnai nesuteikia kalbinio turtingumo ir tikslumo, reikalingo modeliams apibendrinti įvairiose aplinkose, o tai riboja jų veiksmingumą realiame pasaulyje.
Esami sprendimai remiasi sintetinių duomenų generavimu ir aplinkos papildymu. Sintetiniai duomenys generuojami naudojant modelius nuo trajektorijos iki komandos, o simuliatoriai paįvairina aplinką. Tačiau šie metodai dažnai turi pagerinti kokybę, todėl gaunami prastai suderinti kalbos ir navigacijos trajektorijų duomenys. Dėl šio nesutapimo agento veikimas yra neoptimalus. Problemą dar labiau apsunkina metrika, kuri netinkamai įvertina instrukcijų semantinį ir krypties suderinimą su atitinkamomis trajektorijomis, todėl kyla iššūkis kokybės kontrolei.
Tyrėjai iš Šanchajaus AI laboratorijos, UNC Chapel Hill, „Adobe Research“ ir Nankino universiteto pasiūlė savaiminio tobulinimo duomenų smagratį (SRDF), sistemą, skirtą pakartotinai tobulinti tiek duomenų rinkinį, tiek modelius bendradarbiaujant instrukcijų generatoriui ir navigatoriui. Šis visiškai automatizuotas metodas pašalina žmogaus ciklo anotacijos poreikį. Pradedant nuo mažo, aukštos kokybės žmogaus anotuoto duomenų rinkinio, SRDF sistema generuoja sintetines instrukcijas ir naudoja jas baziniam navigatoriui apmokyti. Tada navigatorius įvertina šių instrukcijų tikslumą, išfiltruodamas žemos kokybės duomenis, kad būtų parengtas geresnis generatorius vėlesnėse iteracijose. Šis kartotinis tobulinimas užtikrina nuolatinį duomenų kokybės ir modelių našumo gerinimą.
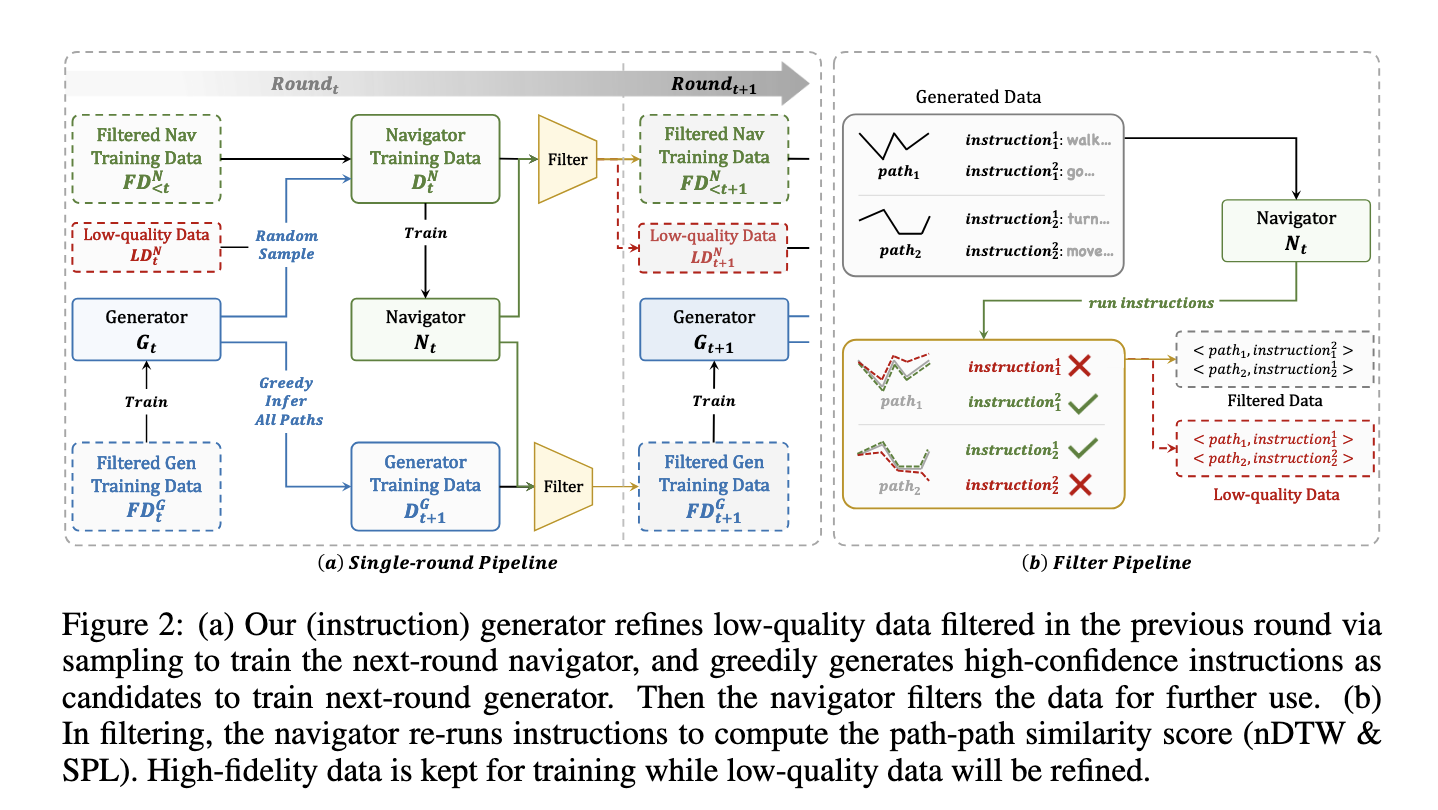
SRDF sistemą sudaro du pagrindiniai komponentai: instrukcijų generatorius ir navigatorius. Generatorius sukuria sintetines navigacijos instrukcijas iš trajektorijų, naudodamas pažangius multimodalinių kalbų modelius. Savo ruožtu navigatorius įvertina šias instrukcijas, matuodamas, kaip tiksliai jis gali sekti sugeneruotus kelius. Aukštos kokybės duomenys nustatomi remiantis griežta tikslumo metrika, pvz., sėkmę, įvertintą pagal kelio ilgį (SPL) ir normalizuotą dinaminį laiko deformavimą (nDTW). Prastos kokybės duomenys arba atkuriami, arba neįtraukiami, užtikrinant, kad mokymui būtų naudojami tik patikimi ir labai suderinti duomenys. Per tris iteracijas sistema patobulina duomenų rinkinį, kuriame galiausiai yra 20 milijonų didelio tikslumo instrukcijų ir trajektorijų porų, apimančių 860 skirtingų aplinkų.
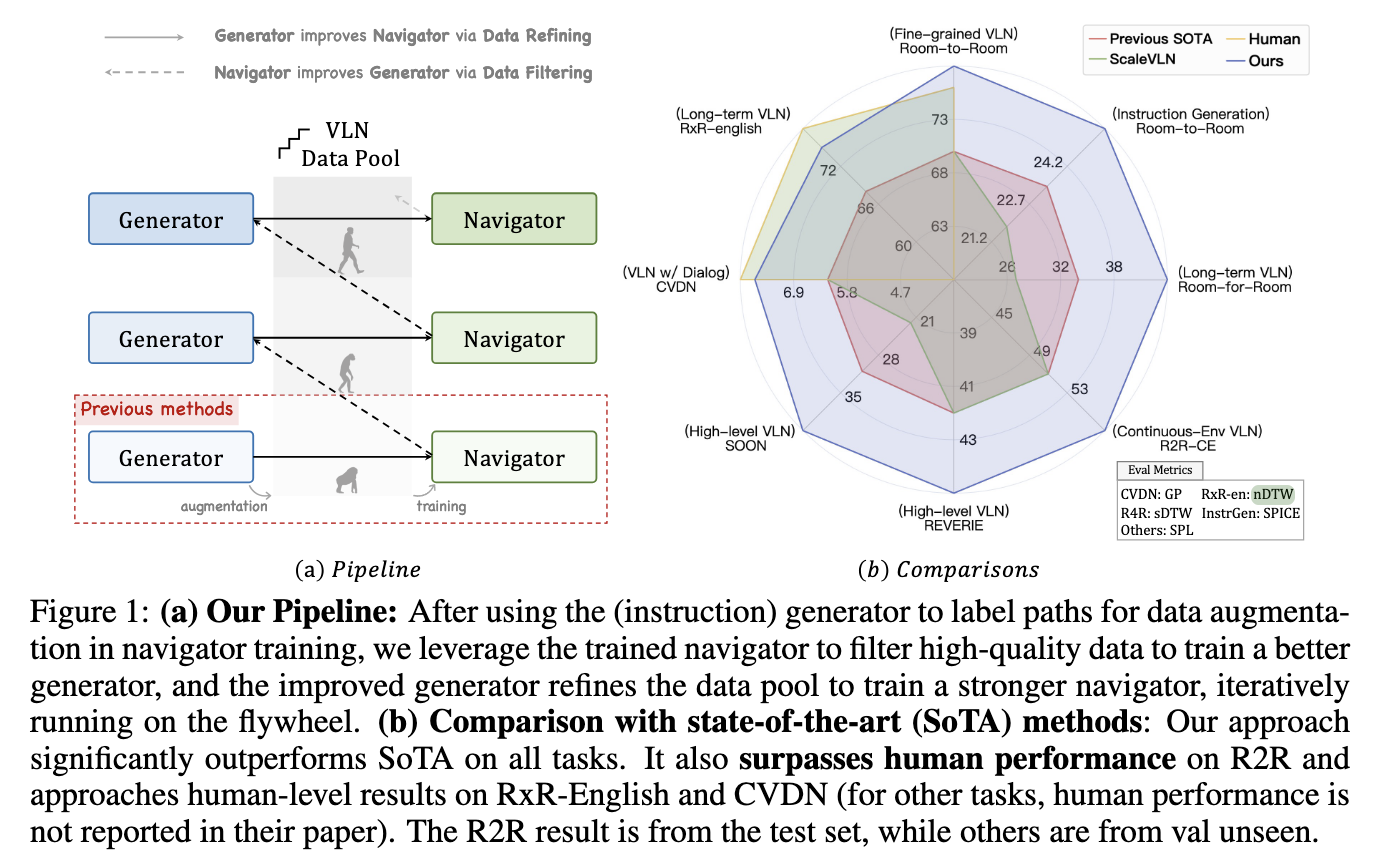
SRDF sistema parodė išskirtinius našumo patobulinimus įvairiose metrikose ir etalonuose. Duomenų rinkinyje „Kambary į kambarį“ (R2R) navigatoriaus SPL metrika pakilo nuo 70 % iki precedento neturinčių 78 %, viršydama 76 % žmogaus etaloną. Tai pirmas atvejis, kai VLN agentas viršijo žmogaus lygio navigacijos tikslumą. Instrukcijų generatorius taip pat pasiekė įspūdingų rezultatų, o SPICE balai padidėjo nuo 23,5 iki 26,2, pranokstant visus ankstesnius „Vision-and-Language Navigation“ instrukcijų generavimo metodus. Be to, SRDF sugeneruoti duomenys palengvino puikų apibendrinimą visose paskesnėse užduotyse, įskaitant ilgalaikę navigaciją (R4R) ir dialogu pagrįstą navigaciją (CVDN), todėl buvo pasiektas moderniausias visų išbandytų duomenų rinkinių našumas.
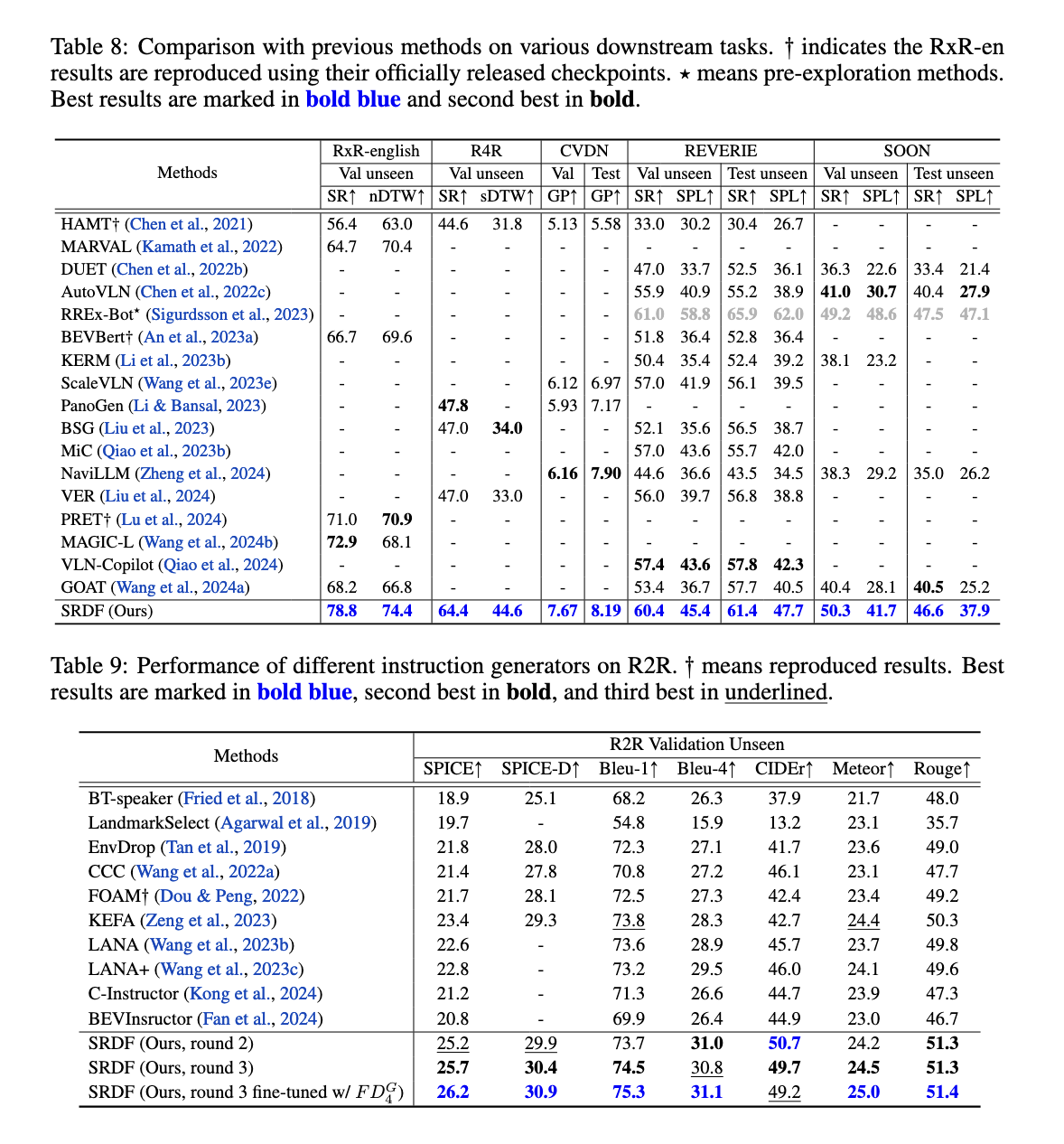
Konkrečiai, sistema pasižymėjo naršymu ilguoju horizontu, pasiekusi 16,6 % pagerėjimą R4R duomenų rinkinio sėkmės rodiklyje. CVDN duomenų rinkinys žymiai pagerino tikslo progreso metriką ir pralenkė visus ankstesnius modelius. Be to, SRDF mastelio keitimas buvo akivaizdus, nes instrukcijų generatorius nuolat tobulėjo naudojant didesnius duomenų rinkinius ir įvairias aplinkas, užtikrinant tvirtą našumą atliekant įvairias užduotis ir etalonus. Tyrėjai taip pat pranešė apie padidintą instrukcijų įvairovę ir turtingumą, nes į SRDF sugeneruotą duomenų rinkinį įtraukta daugiau nei 10 000 unikalių žodžių, sprendžiant ankstesnių duomenų rinkinių žodyno apribojimus.
SRDF metodas sprendžia ilgalaikį duomenų trūkumo VLN iššūkį automatizuodamas duomenų rinkinio tobulinimą. Iteratyvus navigatoriaus ir instrukcijų generatoriaus bendradarbiavimas užtikrina nuolatinį abiejų komponentų tobulinimą, todėl gaunami labai suderinti aukštos kokybės duomenų rinkiniai. Šis proveržio metodas nustatė naują VLN tyrimų standartą, parodantį kritinį duomenų kokybės ir derinimo vaidmenį tobulinant įkūnytą AI. Sugebėdamas pranokti žmogaus veiklą ir apibendrinti įvairias užduotis, SRDF yra pasirengusi padaryti didelę pažangą kuriant išmaniąsias navigacijos sistemas.
Patikrinkite į Popierius ir „GitHub“ puslapis. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Nikhilas yra „Marktechpost“ konsultantas. Indijos technologijos institute Charagpūre jis siekia integruoto dvigubo medžiagų studijų laipsnio. Nikhilas yra AI / ML entuziastas, kuris visada tiria pritaikymą tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagų mokslo išsilavinimą, jis tyrinėja naujus pasiekimus ir kuria galimybes prisidėti.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)




