

Atnaujintos kartos (RAG) sistemos sujungia paieškos ir generavimo procesus, kad išspręstų sudėtingus atsakymus į atvirus, daugiamačius klausimus. Pasiekę atitinkamus dokumentus ir žinias, RAG pagrįsti modeliai generuoja atsakymus su papildomu kontekstu ir suteikia daugiau įžvalgų nei tik generaciniai modeliai. Šis metodas yra naudingas srityse, kuriose atsakymai turi atspindėti plačią žinių bazę, pavyzdžiui, teisiniai tyrimai ir akademinė analizė. RAG sistemos nuskaito tikslinius duomenis ir sujungia juos į išsamius atsakymus, o tai ypač naudinga situacijose, kuriose reikia įvairių perspektyvų ar gilaus konteksto.
Vertinant RAG sistemų efektyvumą, kyla unikalių iššūkių, nes jose dažnai reikia atsakyti į ne faktinius klausimus, į kuriuos reikia daugiau nei vieno galutinio atsakymo. Tradicinės vertinimo metrikos, tokios kaip tinkamumas ir ištikimybė, turi visiškai užfiksuoti, kaip šios sistemos apima tokių sudėtingų, daugiasluoksnių klausimų potemes. Realiose programose klausimai dažnai apima pagrindinius užklausas, paremtas papildomais kontekstiniais arba tiriamaisiais elementais, kurie sudaro visapusiškesnį atsakymą. Esami įrankiai ir modeliai visų pirma orientuoti į paviršiaus lygmens priemones, paliekant spragą suprasti RAG atsakymų išsamumą.
Dauguma dabartinių RAG sistemų veikia pagal bendruosius kokybės rodiklius, kurie tik iš dalies patenkina vartotojų poreikius, kad būtų užtikrinta visapusiška aprėptis. Įrankiai ir sistemos dažnai apima papildomų klausimų užuominas, tačiau reikia pagalbos, kad klausimas būtų visiškai suskaidytas į išsamias potemes, turinčias įtakos vartotojų pasitenkinimui. Siekiant aiškumo, sudėtingoms užklausoms gali prireikti atsakymų, apimančių ne tik tiesioginius atsakymus, bet ir pagrindinę bei tolesnę informaciją. Kadangi reikia atlikti išsamų aprėpties įvertinimą, šios sistemos dažnai nepastebi arba netinkamai integruoja esminę informaciją į savo sugeneruotus atsakymus.
Džordžijos technologijos instituto ir „Salesforce AI“ tyrimų tyrėjai pristato naują RAG sistemų vertinimo sistemą, pagrįstą metrika, vadinama „antrinių klausimų aprėptis“. Vietoj bendrų tinkamumo balų tyrėjai siūlo išskaidyti klausimą į konkrečius pokalbius, suskirstytus į pagrindinius, pagrindinius ar tolesnius veiksmus. Šis metodas leidžia niuansuotai įvertinti atsakymų kokybę, nagrinėjant, kaip gerai sprendžiamas kiekvienas papildomas klausimas. Komanda pritaikė savo sistemą trims plačiai naudojamoms RAG sistemoms – You.com, Perplexity AI ir Bing Chat, atskleisdama skirtingus įvairių antrinių klausimų tvarkymo modelius. Tyrėjai galėjo tiksliai nustatyti spragas, kuriose kiekviena sistema nesugebėjo pateikti išsamių atsakymų, įvertindami šių kategorijų aprėptį.
Kurdami sistemą, mokslininkai taikė dviejų etapų metodą:
- Pirma, jie suskirstė sudėtingus klausimus į antrinius klausimus, kurių vaidmenys buvo suskirstyti į pagrindinius (esminius pagrindiniam klausimui), pagrindinius (suteikiančius reikiamą kontekstą) arba tolesnius veiksmus (neesminius, bet vertingus tolesnei įžvalgai).
- Tada jie išbandė, kaip gerai RAG sistemos nuskaito atitinkamą kiekvienos kategorijos turinį ir kaip efektyviai jis buvo įtrauktas į galutinius atsakymus. Pavyzdžiui, kiekvienos sistemos paieškos galimybės buvo išnagrinėtos atsižvelgiant į pagrindinius antrinius klausimus, kur tinkama aprėptis dažnai numato bendrą atsakymo sėkmę.
Šio proceso metu sukurtos metrikos suteikia tikslių įžvalgų apie RAG sistemų stipriąsias ir ribotas puses, todėl galima tikslingai tobulinti.
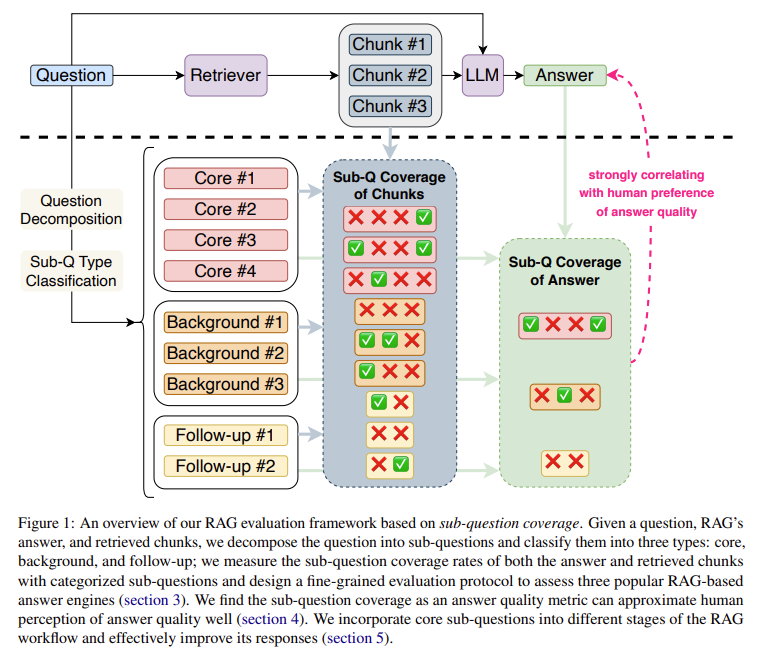
Rezultatai atskleidė reikšmingas sistemų tendencijas, išryškindamos jų privalumus ir trūkumus. Nors kiekviena RAG sistema pirmenybę teikė pagrindiniams daliniams klausimams, nė viena nepasiekė visiškos aprėpties, o spragų liko net kritinėse srityse. Svetainėje You.com pagrindinių klausimų aprėptis buvo 42%, o „Perplexity AI“ veikė geriau ir pasiekė 54% aprėptį. „Bing Chat“ rodiklis buvo šiek tiek mažesnis – 49%, nors ir puikiai sutvarkė informaciją nuosekliai. Tačiau foninių antrinių klausimų aprėptis visose sistemose buvo ypač žema – 20 % You.com ir Perplexity AI ir tik 14 % Bing Chat. Šis skirtumas atskleidžia, kad nors pagrindinis turinys yra prioritetinis, sistemos dažnai turi daugiau dėmesio skirti papildomai informacijai, kuri turi įtakos vartotojų suvokiamai atsako kokybei. Be to, tyrėjai pažymėjo, kad „Perplexity AI“ puikiai susiejo paieškos ir generavimo etapus ir pasiekė 71 % tikslumą derinant pagrindinius antrinius klausimus, o You.com atsiliko 51 %.
Šiame tyrime pabrėžiama, kad vertinant RAG sistemas reikia pereiti nuo įprastų metodų prie į klausimus orientuotų metrikų, kurios įvertina paieškos tikslumą ir atsakymo kokybę. Integruodama poklausimų klasifikavimą į RAG procesus, sistema padeda užpildyti esamų sistemų spragas, didinant jų gebėjimą pateikti išsamius atsakymus. Rezultatai rodo, kad pasinaudojant pagrindiniais antriniais klausimais gavimo metu galima žymiai pagerinti atsakymų kokybę, o „Perplexity AI“ laimėjimo rodiklis yra 74 %, palyginti su pradiniu lygiu, neįtraukiant antrinių klausimų. Svarbu tai, kad tyrime buvo nustatytos tobulintinos sritys, pvz., „Bing Chat“ poreikis padidinti pagrindinės ir foninės informacijos derinimo nuoseklumą.

Pagrindinės šio tyrimo išvados pabrėžia papildomų klausimų klasifikavimo svarbą siekiant pagerinti RAG našumą:
- Pagrindinis papildomo klausimo aprėptis: Vidutiniškai RAG sistemos praleido apie 50 % pagrindinių klausimų, o tai rodo aiškią tobulinimo sritį.
- Sistemos tikslumas: Perplexity AI pirmavo 71 % tikslumu susiedamas gautą turinį su atsakymais, palyginti su You.com 51 % ir Bing Chat 63 % tikslumu.
- Pagrindinės informacijos svarba: Fono antrinių klausimų aprėptis visose sistemose buvo mažesnė – svyravo nuo 14 % iki 20 %, o tai rodo, kad kontekstinis atsakymų palaikymas trūko.
- Našumo reitingai: „Perplexity AI“ užėmė aukščiausią įvertinimą: „Bing Chat“ puikiai struktūrizuoja atsakymus, o „You.com“ parodė didelius apribojimus.
- Tobulėjimo potencialas: Visose RAG sistemose buvo daug galimybių patobulinti pagrindinių papildomų klausimų paiešką, o atsakymo kokybė turėtų padidėti net 45%.

Apibendrinant, šiame tyrime iš naujo apibrėžiama, kaip vertinamos RAG sistemos, pabrėžiant klausimų aprėptį kaip pagrindinį sėkmės rodiklį. Analizuojant konkrečius atsakymų antrinių klausimų tipus, tyrimas atskleidžia dabartinių RAG sistemų apribojimus ir siūlo būdą pagerinti atsakymų kokybę. Išvadose pabrėžiamas tikslinio paieškos papildymo poreikis ir nurodomi praktiniai žingsniai, kurie galėtų padaryti RAG sistemas tvirtesnes sudėtingoms, daug žinių reikalaujančioms užduotims atlikti. Tyrimas sudaro pagrindą būsimiems atsako generavimo technologijos patobulinimams taikant šį niuansuotą vertinimo metodą.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Būsimas tiesioginis internetinis seminaras – 2024 m. spalio 29 d.) Geriausia platforma, skirta tiksliai suderintiems modeliams aptarnauti: „Predibase Inference Engine“ (reklamuojama)
Asif Razzaq yra „Marktechpost Media Inc.“ generalinis direktorius. Kaip verslininkas ir inžinierius, Asif yra įsipareigojęs panaudoti dirbtinio intelekto potencialą socialinei gerovei. Naujausias jo siekis yra dirbtinio intelekto medijos platformos „Marktechpost“ paleidimas, kuri išsiskiria išsamia mašininio mokymosi ir gilaus mokymosi naujienomis, kurios yra techniškai pagrįstos ir lengvai suprantamos plačiajai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonais peržiūrų per mėnesį, o tai rodo jos populiarumą tarp auditorijos.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️





