

Baltymai, esminis molekulinis gyvybės mechanizmas, atlieka pagrindinį vaidmenį daugelyje biologinių procesų. Jų sudėtingos sekos, struktūros ir funkcijos (SSF) iššifravimas yra pagrindinis biochemijos, molekulinės biologijos ir vaistų kūrimo tikslas. Šių trijų aspektų sąveikos supratimas yra labai svarbus norint atskleisti gyvenimo principus molekuliniu lygmeniu. Siekiant įveikti šį iššūkį, buvo sukurti skaičiavimo įrankiai, kurių lygiavimu pagrįsti metodai, tokie kaip BLAST, MUSCLE, TM-align, MMseqs2 ir Foldseek, daro didelę pažangą. Tačiau šios priemonės dažnai teikia pirmenybę efektyvumui, sutelkdamos dėmesį į vietinį derinimą, o tai gali apriboti jų galimybes gauti pasaulines įžvalgas. Be to, jie paprastai veikia pagal vieną modalumą – seką arba struktūrą – neintegruodami kelių modalumo. Šį apribojimą apsunkina tai, kad beveik 30% „UniProt“ baltymų lieka be komentarų, nes jų sekos per daug skiriasi nuo žinomų funkcinių atitikmenų.
Naujausi neuroniniais tinklais pagrįstų įrankių pažanga leido tiksliau nurodyti funkcines baltymų anotacijas, identifikuojant atitinkamas tam tikrų sekų etiketes. Tačiau šie metodai remiasi iš anksto apibrėžtomis anotacijomis ir negali interpretuoti ar generuoti išsamių baltymų funkcijų aprašymų natūralia kalba. Tokių LLM, kaip „ChatGPT“ ir „LLaMA“ atsiradimas parodė išskirtines natūralios kalbos apdorojimo galimybes. Panašiai, baltymų kalbos modelių (PLM) atsiradimas atvėrė naujas galimybes skaičiavimo biologijoje. Remdamiesi šiais pokyčiais, mokslininkai siūlo sukurti pagrindinį baltymų modelį, kuris panaudotų pažangų kalbos modeliavimą, kad būtų galima holistiškai reprezentuoti baltymą SSF, sprendžiant dabartinių metodų apribojimus.
„ProTrek“, sukurta Westlake universiteto mokslininkų, yra pažangiausias trimodalinis PLM, integruojantis SSF. Naudodamas kontrastinį mokymąsi, jis suderina šiuos būdus, kad būtų galima greitai ir tiksliai atlikti paiešką devyniuose SSF deriniuose. „ProTrek“ pranoksta esamus įrankius, tokius kaip „Foldseek“ ir „MMseqs2“ greičiu (100 kartų) ir tikslumu, tuo pat metu pranoksta ESM-2 atliekant tolesnius numatymo darbus. Apmokytas 40 milijonų baltymų ir teksto porų, jis siūlo pasaulinio vaizdavimo mokymąsi, kad būtų galima identifikuoti baltymus, turinčius panašias funkcijas, nepaisant struktūrinių ar sekos skirtumų. „ProTrek“ nustato naujus baltymų tyrimo ir analizės etalonus, naudodamas nulinio atgavimo ir tikslaus derinimo galimybes.
Aprašomieji duomenys iš UniProt poskyrių buvo suskirstyti į sekos lygį (pvz., funkcijų aprašymus) ir likučių lygį (pvz., surišimo vietas), kad būtų sukurtos baltymų ir funkcijų poros. GPT-4 buvo naudojamas likučių lygio duomenims tvarkyti ir sekos lygio aprašymams perfrazuoti, todėl buvo gauta 14 mln. treniruočių porų iš „Swiss-Prot“. Pradinis „ProTrek“ modelis buvo iš anksto parengtas naudojant šį duomenų rinkinį, o vėliau naudojamas UniRef50 filtruoti, sukuriant galutinį 39 milijonų porų duomenų rinkinį. Mokymai apėmė InfoNCE ir MLM nuostolius, ESM-2 ir PubMedBERT kodavimo įrenginius su optimizavimo strategijomis, tokiomis kaip AdamW ir DeepSpeed. „ProTrek“ pranoko pradines lyginamąsias linijas, naudodamas 4 000 „Swiss-Prot“ baltymų ir 104 000 „UniProt“ negatyvų, įvertintus pagal tokius rodiklius kaip MAP ir tikslumas.
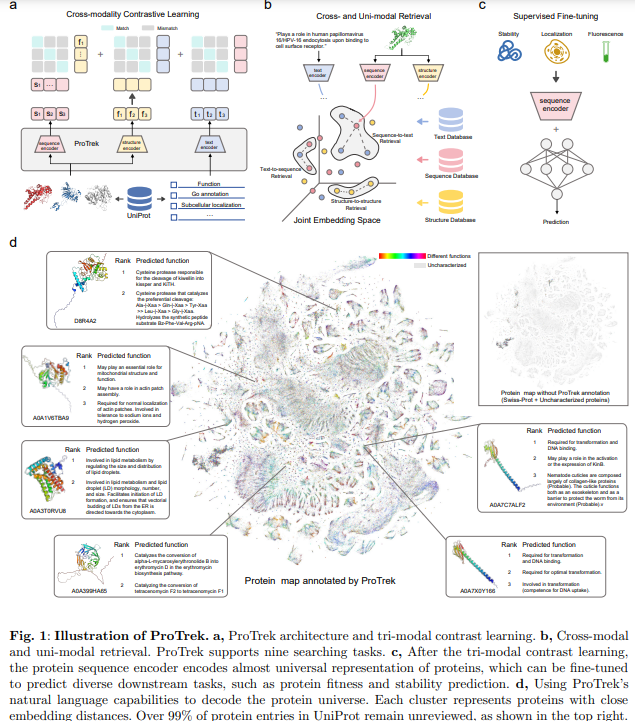
„ProTrek“ yra novatoriška baltymų tyrimo pažanga, integruojant seką, struktūrą ir natūralios kalbos funkciją (SSF) į sudėtingą trimodalinės kalbos modelį. Naudojant kontrastinį mokymąsi, panaikinama atskirtis tarp baltymų duomenų ir žmogaus interpretacijos, todėl galima labai efektyviai ieškoti devyniuose SSF porų modalumo deriniuose. „ProTrek“ siūlo transformacinius patobulinimus, ypač baltymų sekų ir funkcijų atkūrimo srityje, 30–60 kartų našiau nei ankstesni metodai. Jis taip pat pranoksta tradicinius derinimo įrankius, tokius kaip Foldseek ir MMseqs2, parodydamas daugiau nei 100 kartų greitį ir didesnį tikslumą nustatant funkciškai panašius baltymus su įvairiomis struktūromis. Be to, „ProTrek“ nuolat pranoksta moderniausią ESM-2 modelį, puikiai atlikdama 9 iš 11 tolesnių užduočių ir nustatydama naujus baltymų intelekto standartus.
Šios galimybės sukuria „ProTrek“ kaip pagrindinį baltymų tyrimų ir duomenų bazių analizės įrankį. Jo puikų našumą lemia platus mokymo duomenų rinkinys, kuris yra daug didesnis nei palyginamų modelių. Natūralios „ProTrek“ kalbos supratimo galimybės viršija įprastus raktinių žodžių derinimo metodus, leidžia atlikti kontekstą atitinkančias paieškas ir tobulinti programas, tokias kaip tekstu valdomas baltymų dizainas ir baltymams būdingos ChatGPT sistemos. „ProTrek“ suteikia tyrėjams galimybę efektyviai analizuoti didžiules baltymų duomenų bazes ir spręsti sudėtingas baltymų ir teksto sąveikas, užtikrindamas puikų greitį, tikslumą ir universalumą, atverdamas kelią reikšmingai baltymų mokslo ir inžinerijos pažangai.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 NEMOKAMAS BŪTINAS AI internetinis seminaras (2025 M. SAUSIO 15 d.): padidinkite LLM tikslumą naudodami sintetinius duomenis ir įvertinimo informaciją–Prisijunkite prie šio internetinio seminaro, kad gautumėte veiksmingų įžvalgų, kaip padidinti LLM modelio našumą ir tikslumą, kartu išsaugant duomenų privatumą.
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 Sekite mus X (Twitter), kad gautumėte reguliarius AI tyrimų ir kūrėjų atnaujinimus čia…




