

LLM pademonstravo įspūdingus gebėjimus tiksliai atsakyti į medicininius klausimus, netgi pralenkdami vidutinius žmogaus balus kai kuriose medicininėse apžiūrose. Tačiau jų pritaikymas atliekant medicininės dokumentacijos užduotis, pvz., klinikinių pastabų generavimą, susiduria su iššūkiais, nes kyla pavojus, kad bus sukurta neteisinga arba nenuosekli informacija. Tyrimai rodo, kad 20% pacientų, skaitančių klinikinius užrašus, nustatė klaidas, o 40% mano, kad jos yra rimtos, dažnai susijusios su klaidingomis diagnozėmis. Tai kelia didelį susirūpinimą, ypač todėl, kad LLM vis dažniau remia medicininės dokumentacijos užduotis. Nors šie modeliai puikiai tinka atsakant į medicininio patikrinimo klausimus ir imituojant klinikinius samprotavimus, jie linkę sukelti haliucinacijas ir potencialiai žalingą turinį, o tai gali neigiamai paveikti klinikinių sprendimų priėmimą. Tai pabrėžia esminį tvirtų patvirtinimo sistemų poreikį, siekiant užtikrinti LLM sukurto medicininio turinio tikslumą ir saugumą.
Pastaruoju metu buvo ištirtos nuoseklumo vertinimo gairės bendrosiose srityse, tokiose kaip semantinis, loginis ir faktinis nuoseklumas, tačiau šie metodai dažnai neužtikrina patikimumo visais bandomaisiais atvejais. Nors modeliai, tokie kaip ChatGPT ir GPT-4, pasižymi geresniu samprotavimu ir kalbos supratimu, tyrimai rodo, kad jiems sunku išlaikyti loginį nuoseklumą. Medicinos srityje LLM, pvz., ChatGPT ir GPT-4, vertinimai parodė tikslius struktūrinių medicininių tyrimų, pvz., USMLE, rezultatus. Tačiau sprendžiant sudėtingas medicinines užklausas atsiranda apribojimų, o LLM sukurti juodraščiai bendraujant su pacientais parodė galimą riziką, įskaitant didelę žalą, jei klaidos lieka neištaisytos. Nepaisant pažangos, viešai prieinamų gairių, skirtų LLM sukurtų medicininių tekstų teisingumui ir nuoseklumui patvirtinti, trūkumas pabrėžia patikimų automatizuotų patvirtinimo sistemų poreikį, kad būtų galima veiksmingai spręsti šiuos iššūkius.
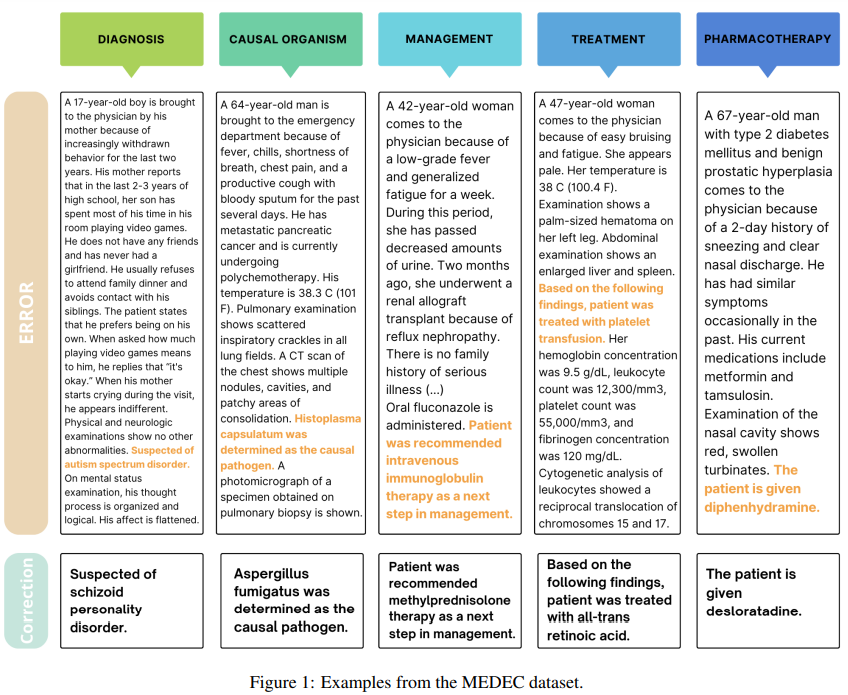
„Microsoft“ ir Vašingtono universiteto mokslininkai sukūrė MEDEC – pirmąjį viešai prieinamą etaloną, leidžiantį aptikti ir ištaisyti medicinines klaidas klinikinėse pastabose. MEDEC apima 3848 klinikinius tekstus, apimančius penkis klaidų tipus: diagnozę, valdymą, gydymą, farmakoterapiją ir priežastinį organizmą. Įvertinimai naudojant pažangias LLM, tokias kaip GPT-4 ir Claude 3.5 Sonnetas, atskleidė jų gebėjimą atlikti šias užduotis, tačiau žmonių medicinos ekspertai jas lenkia. Šis etalonas pabrėžia klinikinių tekstų patvirtinimo ir taisymo iššūkius, pabrėžiant modelių su tvirtais medicininiais argumentais poreikį. Šių eksperimentų įžvalgos pateikia gaires, kaip tobulinti būsimas klaidų aptikimo sistemas.
MEDEC duomenų rinkinyje yra 3848 klinikiniai tekstai, pažymėti penkiais klaidų tipais: diagnozė, valdymas, gydymas, farmakoterapija ir priežastinis organizmas. Klaidos buvo įvestos naudojant medicininės komisijos egzaminus (MS) ir pakeitus tikrus klinikinius pranešimus iš Vašingtono universiteto ligoninių (UW). Anotatoriai rankiniu būdu sukūrė klaidų, į tekstą įterpdami neteisingus medicininius objektus, užtikrindami nuoseklumą su kitomis pastabos dalimis. MEDEC skirtas įvertinti klaidų aptikimo ir taisymo modelius, suskirstytus į klaidų numatymą, klaidų sakinių identifikavimą ir pataisymų generavimą.
Eksperimentuose buvo naudojami įvairūs maži ir LLM, įskaitant „Phi-3-7B“, „Claude 3.5 Sonnet“, „Gemini 2.0 Flash“ ir „OpenAI“ GPT-4 seriją, siekiant įvertinti jų našumą atliekant medicininių klaidų aptikimo ir taisymo užduotis. Šie modeliai buvo išbandyti atliekant tokias papildomas užduotis kaip klaidų nustatymas, klaidingų sakinių nustatymas ir pataisymų generavimas. Jų galimybėms įvertinti buvo naudojamos tokios metrikos kaip tikslumas, atšaukimas, ROUGE-1, BLEURT ir BERTScore, kartu su bendru balu, apjungiančiu šias korekcijos kokybės metrikas. Claude 3.5 Sonnetas pasiekė didžiausią tikslumą aptikdamas klaidų vėliavėles (70,16 %) ir sakinius (65,62 %), o o1 peržiūra puikiai ištaisė klaidas ir surinko 0,698 balo. Palyginus su ekspertų medicininėmis anotacijomis, paaiškėjo, kad nors LLM veikė gerai, gydytojai juos vis tiek pranoko aptikimo ir korekcijos užduotyse.
Veiklos atotrūkis greičiausiai atsirado dėl riboto su klaidomis susijusių medicininių duomenų prieinamumo LLM išankstinio mokymo metu ir iššūkio analizuoti jau esamus klinikinius tekstus, o ne generuoti atsakymus. Tarp modelių o1 peržiūra parodė puikų visų tipų klaidų prisiminimą, tačiau buvo sunku atlikti tikslumą, dažnai pervertinant klaidų atvejus, palyginti su medicinos ekspertais. Šis tikslumo trūkumas, kartu su modelių priklausomybe nuo viešųjų duomenų rinkinių, lėmė pogrupių našumo skirtumus, o modeliai veikė geriau viešuosiuose duomenų rinkiniuose (pvz., MEDEC-MS) nei privačiose kolekcijose, tokiose kaip MEDEC-UW.
Patikrinkite į Popierius ir „GitHub“ puslapis. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 NEMOKAMAS BŪTINAS AI internetinis seminaras (2025 M. SAUSIO 15 d.): padidinkite LLM tikslumą naudodami sintetinius duomenis ir įvertinimo informaciją–Prisijunkite prie šio internetinio seminaro, kad gautumėte veiksmingų įžvalgų, kaip padidinti LLM modelio našumą ir tikslumą, kartu išsaugant duomenų privatumą.
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)




