Alleno AI (AI2) institutas išleido Olmoasratviro komplektas Automatinis kalbos atpažinimas (ASR) Modeliai, kurie konkuruoja su uždaro kodo sistemomis, tokiomis kaip „Openai's Whisper“. „AI2“ išleido ne tik modelio svorius, bet ir paskelbė mokymo duomenų identifikatorius, filtravimo veiksmus, mokymo receptus ir etaloninius scenarijus – neįprastai skaidrų judėjimą ASR erdvėje. Tai daro „Olmoasr“ viena iš labiausiai populiariausių ir išplėstinių kalbų atpažinimo tyrimų platformų.
Kodėl verta atidaryti automatinį kalbos atpažinimą ASR?
Daugelis šiandien prieinamų kalbų atpažinimo modelių – „Openai“, „Google“ ar „Microsoft“ – yra prieinami tik per API. Nors šios paslaugos teikia aukštą našumą, jos veikia kaip Juodosios dėžutės: Treniruočių duomenų rinkiniai yra nepermatomi, filtravimo metodai nėra dokumentų dokumentai, o vertinimo protokolai ne visada yra suderinti su tyrimų standartais.
Šis skaidrumo trūkumas kelia iššūkius atkuriamumui ir mokslinei pažangai. Tyrėjai negali patikrinti teiginių, išbandyti variantus ar pritaikyti modelius prie naujų domenų, patys nesukurdami didelių duomenų rinkinių. „Olmoasr“ išsprendžia šią problemą atidarydamas visą vamzdyną. Išleidimas nėra vien tik praktinės transkripcijos įgalinimas – tai apie Stumdomas ASR link atviresnio, mokslinio pagrindo.
Modelio architektūra ir mastelio keitimas
Olmoasr naudoja a Transformatoriaus kodavimo įrenginio – rinkos architektūradominuojanti šiuolaikinio ASR paradigma.
- kodavimo įrenginys Naudojate garso bangos formas ir sukuria paslėptas reprezentacijas.
- dekoderis generuoja teksto žetonus, kondicionuojamus kodavimo įrenginio išėjimuose.
Šis dizainas yra panašus į „Whisper“, tačiau „Olmoasr“ įgyvendinimą daro visiškai atvirą.
Modelių šeima apima šešis dydžius, visi mokomi anglų kalbos:
- Tiny.en – 39 m parametrai, skirti lengvam daryti išvadą
- bazė.en – 74 m parametrai
- mažas.en – 244 m parametrai
- vidutinis.en – 769m parametrai
- didelis.en-v1 – 1,5B parametrai, apmokyti 440 000 valandų
- didelis.en-v2 – 1,5B parametrai, apmokyti 680 000 valandų
Šis asortimentas leidžia kūrėjams atsisakyti išvadų ir tikslumo. Mažesni modeliai yra tinkami įterptiems įrenginiams ar transkripcijai realiuoju laiku, o didesni modeliai maksimaliai padidina tyrimų ar partijų darbo krūvio tikslumą.
Duomenys: nuo žiniatinklio grandymo iki kuruojamų mišinių
Vienas iš pagrindinių „Olmoasr“ indėlių yra Atidaryti mokymo duomenų rinkinių išleidimąNe tik modeliai.
Olmoasr pool (~ 3M valandos)
Šioje didžiulėje kolekcijoje yra silpnai prižiūrimos kalbos, suporuotos iš interneto išrašytų nuorašų. Tai apima aplink 3 milijonai valandų garso ir 17 milijonų teksto nuorašų. Kaip ir originalus „Whisper“ duomenų rinkinys, jis yra triukšmingas, kuriame yra netinkamai suderintos antraštės, dublikatai ir transkripcijos klaidos.
Olmoasr-Mix (~ 1m valandos)
Norėdami išspręsti kokybės problemas, AI2 taikė griežtas filtravimas:
- Suderinimo euristika Norėdami užtikrinti, kad garso ir nuorašai atitiktų
- Apytikslė dedukcija pašalinti pakartotinius ar žemo diskusijos pavyzdžius
- Valymo taisyklės Norėdami pašalinti dublikatų eilutes ir nesutvarkytą tekstą
Rezultatas yra a Aukštos kokybės, 1m valandos duomenų rinkinys Tai padidina Nulio šūvio apibendrinimas—Kritinė realaus pasaulio užduotims, kai duomenys gali skirtis nuo mokymo pasiskirstymo.
Ši dviejų pakopų duomenų strategija atspindi praktiką didelio masto kalbų modelyje išankstiniu būdu: naudokite didžiulę triukšmingą korporaciją skalei, tada patikrinkite su filtruotais pogrupiais, kad pagerintumėte kokybę.
Našumo etalonai
AI2 etaloniniai olmoasr prieš šnabždesį per trumpos ir ilgos formos kalbos užduotis, naudojant duomenų rinkinius, pavyzdžiui, „LibrisPeech“, „Ted-Lium3“, „Switchboard“, „AMI“ ir „Voxpopuli“.
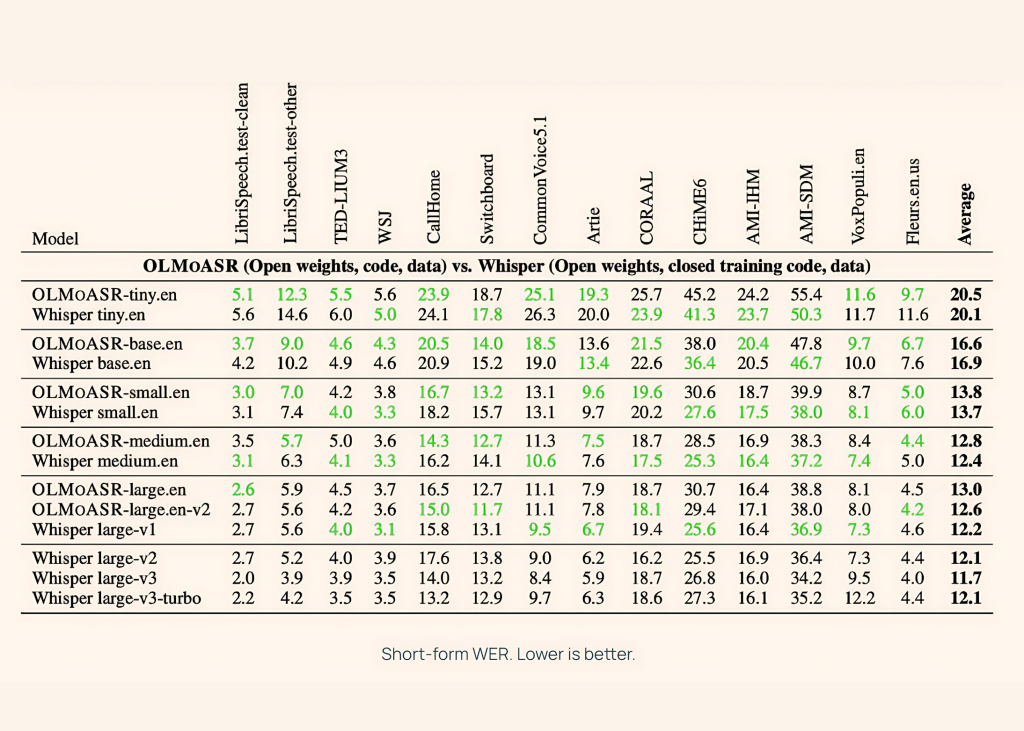
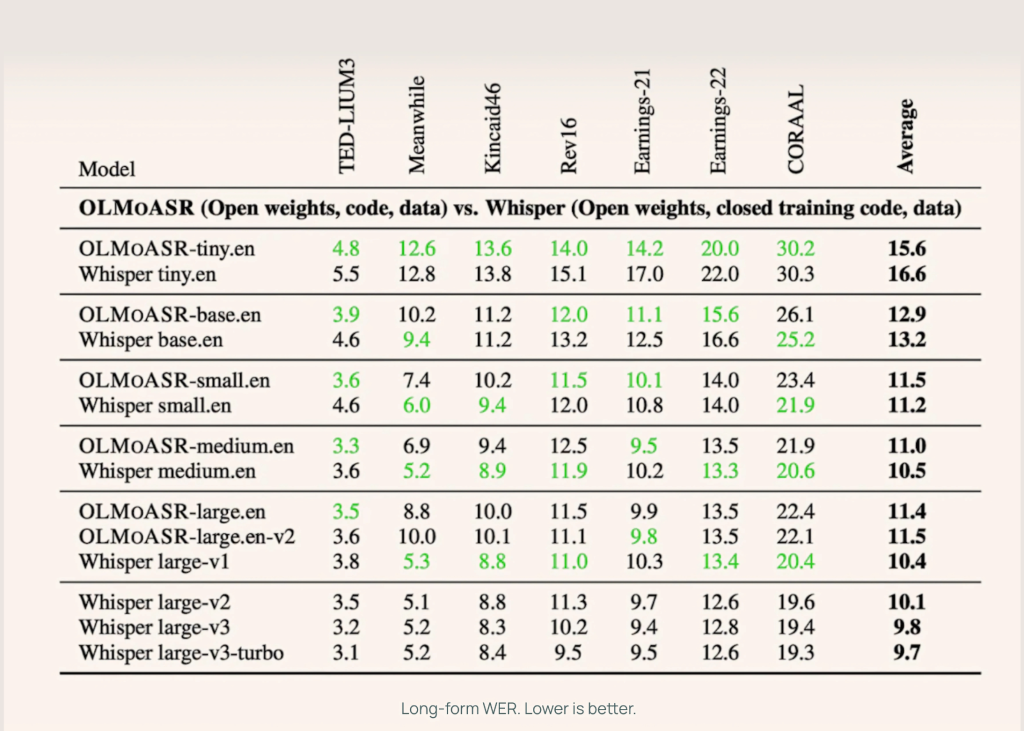
Vidutinis modelis (769m)
- 12,8% (žodžio klaidų lygis) trumpos formos kalboje
- 11,0% apie ilgos formos kalbą
Tai beveik sutampa su šnabždesiu.en, kuris pasiekia 12,4% ir 10,5% atitinkamai.
Dideli modeliai (1,5b)
- Didelis.en-V1 (440K valandos): 13,0% su trumpos formos ir „Whisper Big-V1“, esant 12,2%
- didelis.en-v2 (680K valandos): 12,6 proc.
Mažesni modeliai
Net mažytė ir bazė Versijos veikia konkurencingai:
- Tiny.en: ~ 20,5% su trumpos formos, ~ 15,6%, su ilga forma
- bazė.en: ~ 16,6% su trumpos formos, ~ 12,9%, su ilga forma
Tai suteikia kūrėjams lankstumo pasirinkti modelius, atsižvelgiant į skaičiavimo ir latencijos reikalavimus.
Kaip naudoti?
Garso perrašymas užima tik keletą kodo eilučių:
import olmoasr
model = olmoasr.load_model("medium", inference=True)
result = model.transcribe("audio.mp3")
print(result)
Išėjimas apima ir transkripciją, ir Laiku suderinti segmentaitodėl tai yra naudinga antraštėms, transkripcijos įvykdymui ar pasroviui NLP vamzdynams.
Tikslinimas ir domeno adaptacija
Kadangi AI2 pateikia visą mokymo kodą ir receptus, „Olmoasr“ gali būti Patobulinta specializuotiems domenams:
- Medicinos kalbos pripažinimas -pritaikyti modelius duomenų rinkiniuose, tokiuose kaip „Mimic-III“ ar patentuotų ligoninių įrašų
- Teisinė transkripcija – Teismo salės garso ar teismo proceso mokymai
- Mažo išteklių akcentai -Tinkamas tarmių derinimas, nelabai uždengtas „Olmoasr-Mix“
Šis pritaikomumas yra labai svarbus: ASR našumas dažnai sumažėja, kai modeliai naudojami specializuotuose domenuose su domeno specifiniu žargonu. Atviros vamzdynai domenų adaptaciją daro tiesmukiškai.
Paraiškos
„Olmoasr“ atveria įdomias galimybes akademinių tyrimų metu ir realaus pasaulio AI plėtrai:
- Edukaciniai tyrimai: Tyrėjai gali ištirti sudėtingus ryšius tarp modelio architektūros, duomenų rinkinio kokybės ir filtravimo metodų, kad suprastų jų poveikį kalbos atpažinimo rezultatams.
- Žmogaus ir kompiuterio sąveika: Kūrėjai įgyja laisvę tiesiogiai įterpti kalbos atpažinimo galimybes tiesiogiai į pokalbių AI sistemas, realiojo laiko susitikimų transkripcijos platformas ir prieinamumo programas-visa tai be priklausomybės nuo patentuotų API ar išorinių paslaugų.
- Multimodalinė AI plėtra: Derinant su dideliais kalbų modeliais, „Olmoasr“ suteikia galimybę sukurti pažangius multimodalinius padėjėjus, kurie galėtų sklandžiai apdoroti kalbėtą įvestį ir generuoti intelektualius, kontekstines sąmoningus atsakymus.
- Tyrimų lyginamoji analizė: Atviras mokymo duomenų ir vertinimo metrikos galimybes OLMOASR yra standartizuotas atskaitos taškas, leidžiantis tyrėjams palyginti naujus metodus su nuosekliu, atkuriamu pradine padėtimi ateityje ASR tyrimuose.
Išvada
„Olmoasr“ išleidimas atneša aukštos kokybės kalbos atpažinimą ir išleidžiamas taip, kad būtų prioritetas skaidrumas ir atkuriamumas. Nors modeliai šiuo metu apsiriboja anglų kalba ir vis dar reikalauja reikšmingo skaičiavimo mokymui, jie suteikia tvirtą pagrindą adaptacijai ir pratęsimui. Šis leidimas nustato aiškų būsimo darbo „Open ASR“ atskaitos tašką ir palengvina tyrinėtojus ir kūrėjus mokytis, lyginti ir pritaikyti kalbos atpažinimo modelius skirtingose srityse.
Peržiūrėkite Apkabinimo veido modelis, „GitHub“ puslapis ir Techninė informacija. Nesivaržykite patikrinti mūsų „GitHub“ puslapis, skirtas vadovėliams, kodams ir užrašų knygelėms. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 100K+ ml subreddit ir užsiprenumeruokite Mūsų informacinis biuletenis.
Asif Razzaq yra „MarkTechPost Media Inc“ generalinis direktorius. Kaip vizionierius verslininkas ir inžinierius, ASIF yra įsipareigojęs išnaudoti dirbtinio intelekto potencialą socialiniam gėrybei. Naujausias jo siekis yra dirbtinio intelekto žiniasklaidos platformos „MarkTechPost“, kuri išsiskiria išsamia mašininio mokymosi ir giluminio mokymosi naujienų, kuri yra techniškai pagrįsta, ir lengvai suprantama plačiai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonai mėnesinių peržiūrų, parodydama jos populiarumą tarp auditorijos.