

Hipertinklai sulaukė dėmesio dėl savo gebėjimo efektyviai pritaikyti didelius modelius arba treniruoti generatyvius neuroninių vaizdų modelius. Nepaisant jų veiksmingumo, hipertinklų mokymas dažnai reikalauja daug darbo, todėl kiekvienam duomenų pavyzdžiui reikia iš anksto apskaičiuotų optimizuotų svorių. Šis pasitikėjimas tiesos svoriais reikalauja didelių skaičiavimo išteklių, kaip matyti iš tokių metodų kaip „HyperDreamBooth“, kur mokymo duomenų paruošimas gali užtrukti daug GPU laiko. Be to, dabartiniai metodai daro prielaidą, kad įvesties mėginiai ir atitinkami optimizuoti svoriai yra susieti vienas su vienu, neatsižvelgiant į stochastinį neuroninio tinklo optimizavimo pobūdį. Šis pernelyg supaprastinimas gali apriboti hipertinklų išraiškingumą. Siekdami išspręsti šiuos iššūkius, mokslininkai siekia amortizuoti kiekvieno pavyzdžio optimizavimą į hipertinklus, apeinant būtinybę atlikti išsamų išankstinį skaičiavimą ir įgalinti greitesnį, labiau keičiamo dydžio mokymą nepakenkiant našumui.
Naujausi patobulinimai integruoja gradientu pagrįstą priežiūrą į hipertinklo treniruotes, pašalina priklausomybę nuo iš anksto apskaičiuotų svorių, išlaikant stabilumą ir mastelio keitimą. Skirtingai nuo tradicinių metodų, kurie remiasi iš anksto apskaičiuotais konkrečios užduoties svoriais, šis metodas prižiūri hipertinklus per gradientus konvergencijos kelyje, leidžiantį efektyviai išmokti svorio erdvės perėjimus. Ši idėja semiasi įkvėpimo iš generatyvių modelių, tokių kaip difuzijos modeliai, nuoseklumo modeliai ir srauto atitikimo sistemos, kurios naršo didelės dimensijos latentinėse erdvėse per gradiento valdomus kelius. Be to, išvestinėmis priemonėmis pagrįsta priežiūra, naudojama fiziškai informuotuose neuroniniuose tinkluose (PINN) ir energija pagrįstuose modeliuose (EBM), informuoja tinklą per gradiento kryptis, išvengiant aiškios išvesties priežiūros. Taikant gradientu pagrįstą priežiūrą, siūlomas metodas užtikrina tvirtą ir stabilų mokymą įvairiuose duomenų rinkiniuose, supaprastina hipertinklo mokymą ir pašalina ankstesnių metodų skaičiavimo kliūtis.
Britų Kolumbijos universiteto ir „Qualcomm AI Research“ mokslininkai siūlo naują hipertinklų mokymo metodą, nesiremiant iš anksto apskaičiuotais, kiekvienam pavyzdžiui optimizuotais svoriais. Jų požiūris įveda „hipertinklo lauką“, kuris modeliuoja visą konkrečių užduočių tinklų optimizavimo trajektoriją, o ne sutelkia dėmesį į galutinius suartintus svorius. Hipertinklas įvertina svorį bet kuriame treniruočių taško taške, įtraukdamas konvergencijos būseną kaip papildomą įvestį. Šiam procesui vadovaujamasi apskaičiuotų svorių gradientų suderinimo su pradiniais užduočių gradientais, todėl nereikia iš anksto apskaičiuotų tikslų. Jų metodas žymiai sumažina mokymo išlaidas ir pasiekia konkurencingų rezultatų atliekant tokias užduotis kaip personalizuoto vaizdo generavimas ir 3D formų atkūrimas.
„Hypernetwork Field“ sistema pristato metodą, leidžiantį modeliuoti visą specifinių užduočių neuroninių tinklų, tokių kaip „DreamBooth“, mokymo procesą, nereikalaujant iš anksto apskaičiuotų svorių. Jis naudoja hipertinklą, kuris pagal įvesties sąlygą numato konkrečios užduoties tinklo parametrus bet kuriame optimizavimo etape. Mokymas remiasi konkrečios užduoties tinklo gradientų suderinimu su hipertinklo trajektorija, todėl nereikia kartoti kiekvieno pavyzdžio optimizavimo. Šis metodas leidžia tiksliai numatyti tinklo svorį bet kuriame etape, fiksuojant visą treniruočių dinamiką. Jis yra efektyvus skaičiavimo požiūriu ir leidžia pasiekti gerų rezultatų atliekant tokias užduotis kaip suasmeninto vaizdo generavimas.
Eksperimentai demonstruoja „Hypernetwork Field“ sistemos universalumą atliekant dvi užduotis: personalizuoto vaizdo generavimą ir 3D formų rekonstrukciją. Šis metodas naudoja „DreamBooth“ kaip užduočių tinklą vaizdams generuoti, suasmeninant vaizdus iš „CelebA-HQ“ ir „AFHQ“ duomenų rinkinių naudojant kondicionavimo žetonus. Su juo pasiekiamas greitesnis mokymas ir daromos išvados, palyginti su pradinėmis linijomis, ir siūlo palyginamus arba geresnius rodiklius tokiose metrikose kaip CLIP-I ir DINO. Atkuriant 3D formą, sistema numato užimtumo tinklo svorį, naudodama pateiktus vaizdus arba 3D taškų debesis kaip įvestį, efektyviai atkartojanti visą optimizavimo trajektoriją. Šis metodas žymiai sumažina skaičiavimo išlaidas, kartu išlaikant aukštos kokybės abiejų užduočių rezultatus.
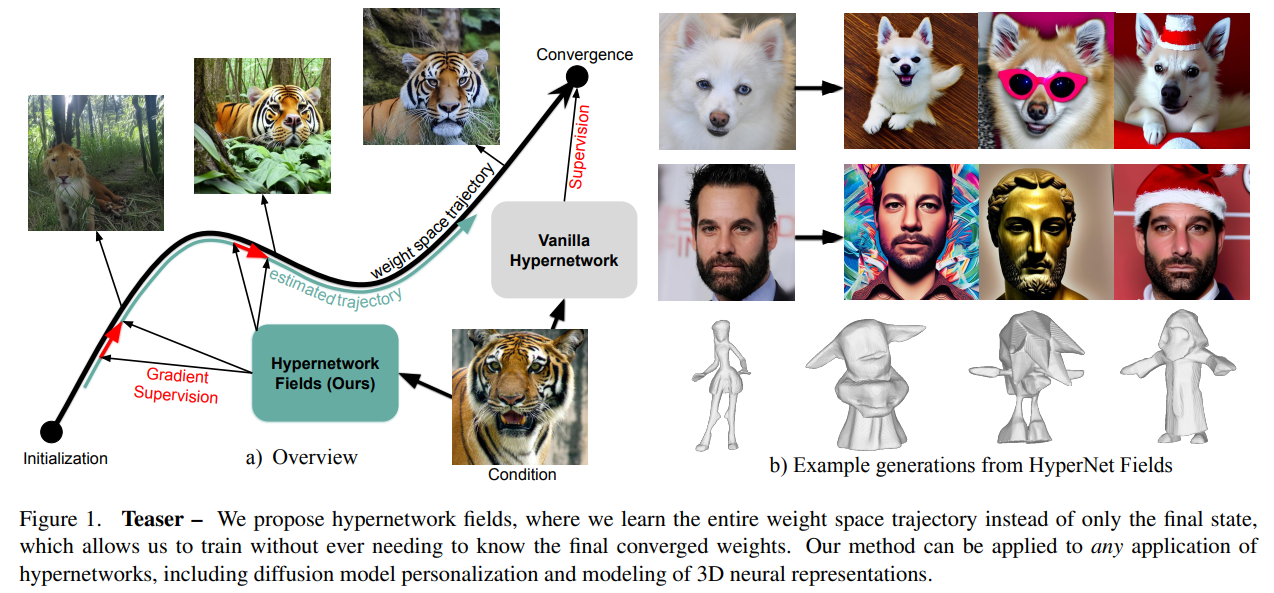
Apibendrinant, „Hypernetwork Fields“ pateikia metodą, kaip efektyviai lavinti hipertinklus. Skirtingai nuo tradicinių metodų, kuriems reikalingi iš anksto apskaičiuoti kiekvieno mėginio tiesos svoriai, ši sistema išmoksta modeliuoti visą konkrečioms užduotims skirtų tinklų optimizavimo trajektoriją. Įvesdami konvergencijos būseną kaip papildomą įvestį, „Hypernetwork Field“ įvertina treniruočių kelią, o ne tik galutinius svorius. Pagrindinė funkcija yra naudoti gradiento priežiūrą, siekiant suderinti apskaičiuotus ir užduočių tinklo gradientus, pašalinant išankstinio atrankos svorių poreikį ir išlaikant konkurencingą našumą. Šis metodas yra apibendrinamas, sumažina skaičiavimo sąnaudas ir suteikia galimybę išplėsti hipertinklus į įvairias užduotis ir didesnius duomenų rinkinius.
Patikrinkite į Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 Populiarumas: LG AI tyrimų išleidimas EXAONE 3.5: trys atvirojo kodo dvikalbiai AI lygio modeliai, teikiantys neprilygstamas instrukcijas ir ilgą konteksto supratimą, kad būtų pasaulinė lyderystė kuriant AI tobulumą….
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
🧵🧵 (Atsisiųsti) Didelių kalbų modelio pažeidžiamumo ataskaitos įvertinimas (reklamuojamas)





