

Baltymai, esminės molekulinės mašinos, išsivystė per milijardus metų, atlieka svarbias gyvybei palaikančias funkcijas, užkoduotas jų sekose ir atskleistas per jų 3D struktūras. Nepaisant eksperimentinių ir skaičiavimo priemonių pažangos, jų funkcinių mechanizmų dekodavimas išlieka pagrindiniu biologijos iššūkiu. Nors AlphaFold ir panašūs modeliai sukėlė revoliuciją struktūros numatymui, atotrūkis tarp struktūrinių žinių ir funkcinio supratimo išlieka, o tai dar labiau padidina nepasakotų baltymų sekų augimą. Tradiciniai įrankiai remiasi evoliuciniais panašumais, ribojančiais jų taikymo sritį. Nauji baltymų kalbos modeliai siūlo daug žadą, pasitelkdami gilų mokymąsi, kad iššifruotų baltymų „kalbą“, tačiau riboti, įvairūs ir daug konteksto mokymosi duomenys riboja jų efektyvumą.
Tyrėjai iš Westlake universiteto ir Nankų universiteto sukūrė Evola, 80 milijardų parametrų multimodalinį baltymų kalbos modelį, skirtą interpretuoti molekulinius baltymų mechanizmus per natūralios kalbos dialogą. „Evola“ integruoja baltymų kalbos modelį (PLM) kaip kodavimo įrenginį, LLM kaip dekoderį ir derinimo modulį, leidžiantį tiksliai numatyti baltymų funkcijas. Išmokyta naudoti precedento neturintį 546 milijonų baltymų, klausimų ir atsakymų porų ir 150 milijardų žetonų duomenų rinkinį, „Evola“ naudoja paieškos papildytą generavimą (RAG) ir tiesioginį pirmenybių optimizavimą (DPO), kad pagerintų atsakymo svarbą ir kokybę. „Evola“, įvertinta naudojant naują „Instructional Response Space“ (IRS) sistemą, pateikia ekspertų lygio įžvalgas, patobulindama proteomikos tyrimus.
„Evola“ yra daugiarūšis generacinis modelis, skirtas atsakyti į funkcinių baltymų klausimus. Jis sujungia su baltymais susijusias žinias su LLM, kad būtų galima tiksliai ir atsižvelgiant į kontekstą atsakyti. „Evola“ turi šaldytų baltymų kodavimo įrenginį, treniruojamą sekos kompresorių ir lygintuvą bei iš anksto paruoštą LLM dekoderį. Jame naudojamas DPO koregavimui, pagrįstam GPT įvertintomis nuostatomis ir RAG, kad padidintų atsakymo tikslumą naudojant Swiss-Prot ir ProTrek duomenų rinkinius. Taikymas apima baltymų funkcijos anotaciją, fermentų klasifikaciją, genų ontologiją, tarpląstelinę lokalizaciją ir ligų susiejimą. „Evola“ yra dviejų versijų: 10B parametrų modelis ir 80B parametrų modelis, vis dar mokomas.
Tyrimas pristato „Evola“ – pažangų 80 milijardų parametrų multimodalinį baltymų kalbos modelį, skirtą baltymų funkcijoms interpretuoti per natūralios kalbos dialogą. „Evola“ integruoja baltymų kalbos modelį kaip kodavimo įrenginį, didelės kalbos modelį kaip dekoderį ir tarpinį glaudinimo ir derinimo modulį. Jis naudoja RAG, kad įtrauktų išorines žinias ir DPO, kad pagerintų atsako kokybę ir patobulintų išvestį, pagrįstą pirmenybės signalais. Įvertinimas naudojant IRS sistemą parodo „Evola“ gebėjimą generuoti tikslias ir kontekstui svarbias įžvalgas apie baltymų funkcijas, taip skatinant proteomikos ir funkcinės genomikos tyrimus.
Rezultatai rodo, kad Evola pranoksta esamus modelius baltymų funkcijų numatymo ir natūralios kalbos dialogo užduotyse. „Evola“ buvo įvertinta naudojant įvairius duomenų rinkinius ir pasiekė naujausių rezultatų generuojant tikslius, kontekstui jautrius atsakymus į su baltymais susijusius klausimus. Lyginamoji analizė su IRS sistema atskleidė jos didelį tikslumą, aiškinamumą ir atsako tinkamumą. Kokybinė analizė išryškino „Evola“ gebėjimą atsakyti į niuansuotas funkcines užklausas ir generuoti baltymų anotacijas, panašias į ekspertų kuruojamas žinias. Be to, abliacijos tyrimai patvirtino jo mokymo strategijų, įskaitant paieškos papildytą generavimą ir tiesioginį pirmenybių optimizavimą, veiksmingumą gerinant atsako kokybę ir suderinimą su biologiniais kontekstais. Tai patvirtina, kad „Evola“ yra patikima proteomikos priemonė.
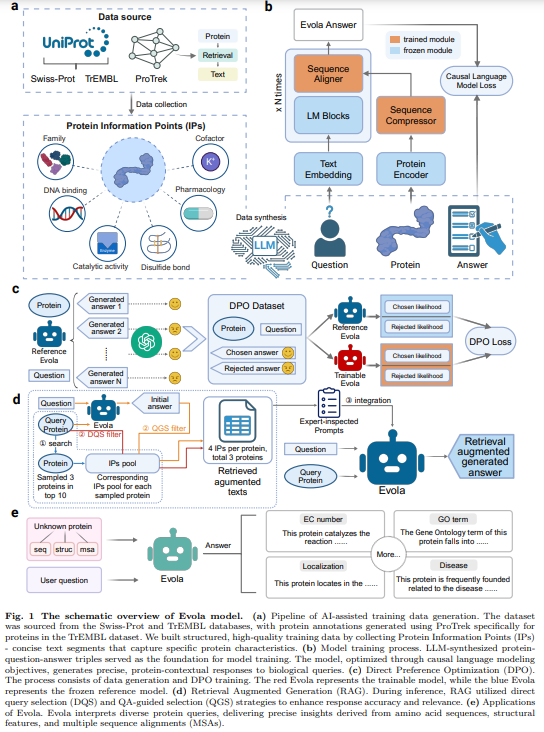
Apibendrinant galima pasakyti, kad „Evola“ yra 80 milijardų parametrų generatyvus baltymų kalbos modelis, skirtas iššifruoti baltymų molekulinę kalbą. Naudodamas natūralios kalbos dialogą, jis sujungia baltymų sekas, struktūras ir biologines funkcijas. „Evola“ naujovė slypi jos mokymuose apie dirbtinio intelekto sintezuotą 546 milijonų baltymų klausimų ir atsakymų porų duomenų rinkinį, apimantį 150 milijardų žetonų – precedento neturinčio masto. Naudodamas DAP ir RAG, jis tobulina atsako kokybę ir integruoja išorines žinias. Įvertinta naudojant IRS, „Evola“ pateikia ekspertų lygio įžvalgas, patobulindama proteomiką ir funkcinę genomiką, kartu pasiūlydama galingą įrankį baltymų molekuliniam sudėtingumui ir jų biologiniam vaidmeniui išsiaiškinti.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Nepamirškite prisijungti prie mūsų 60k+ ML SubReddit.
🚨 NEMOKAMAS BŪTINAS AI internetinis seminaras (2025 M. SAUSIO 15 d.): padidinkite LLM tikslumą naudodami sintetinius duomenis ir įvertinimo informaciją–Prisijunkite prie šio internetinio seminaro, kad gautumėte veiksmingų įžvalgų, kaip padidinti LLM modelio našumą ir tikslumą, kartu išsaugant duomenų privatumą.
Sana Hassan, „Marktechpost“ konsultacinė praktikantė ir „IIT Madras“ dviejų laipsnių studentė, aistringai taiko technologijas ir dirbtinį intelektą sprendžiant realaus pasaulio iššūkius. Labai domisi praktinių problemų sprendimu, jis atneša naują požiūrį į AI ir realaus gyvenimo sprendimų sankirtą.
✅ (Rekomenduojama skaityti) „Nebius AI Studio“ plečiasi regėjimo modeliais, naujais kalbos modeliais, įterpimais ir LoRA (reklamuojama)





