Retrieval-Augmented Generation (RAG) yra sistema, kuri pagerina kalbos modelius, sujungdama du pagrindinius komponentus: retriverį ir generatorių. RAG dujotiekis sujungia retriverį ir generatorių kartotiniame procese ir yra plačiai naudojamas atviro domeno klausimų ir atsakymų, žiniomis pagrįstų pokalbių robotų ir specializuotų informacijos paieškos užduotyse, kur labai svarbus realaus pasaulio duomenų tikslumas ir tinkamumas. Nepaisant to, kad yra įvairių RAG vamzdynų ir modulių, sunku pasirinkti, kuris dujotiekis puikiai tinka savo duomenims ir savo naudojimo atvejams“. Be to, visų RAG modulių gamyba ir įvertinimas yra labai daug laiko ir sunkiai atliekama, tačiau be jo sunku žinoti, kuris RAG dujotiekis yra geriausias savarankiškam naudojimui.
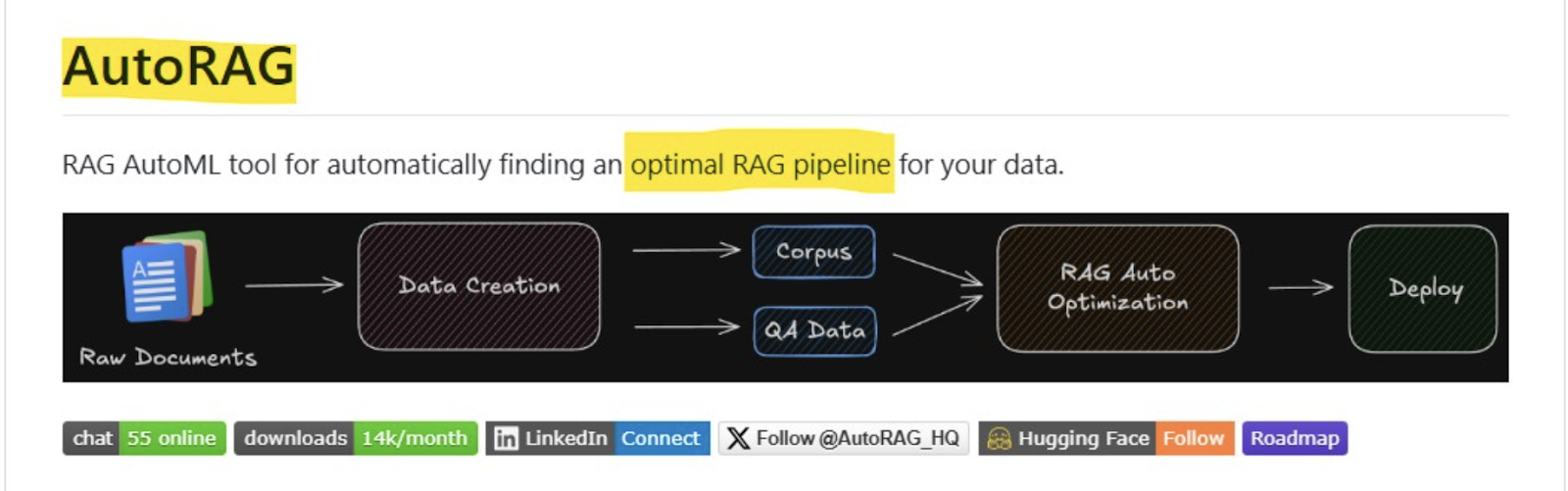
AutoRAG (𝐑𝐀𝐆 𝐀𝐮𝐭𝐨𝐌𝐋 𝐓𝐨𝐨𝐥) yra įrankis, leidžiantis rasti optimalų RAG dujotiekį „savęs duomenims“. Tai padeda automatiškai įvertinti įvairius RAG modulius su savianalizės duomenimis ir rasti geriausią RAG vamzdyną savarankiško naudojimo atvejams. AutoRAG palaiko:
- Duomenų kūrimas: kurkite RAG vertinimo duomenis naudodami neapdorotus dokumentus.
- Optimizavimas: automatiškai vykdykite eksperimentus, kad rastumėte geriausią duomenų RAG dujotiekį.
- Diegimas: įdiekite geriausią RAG dujotiekį su vienu YAML failu ir taip pat palaikykite „Flask“ serverį.
Optimizuojant RAG dujotiekį, mazgas reiškia konkrečią funkciją, o kiekvieno mazgo rezultatas perduodamas kitam mazgui. Pagrindiniai veiksmingo RAG dujotiekio mazgai yra paėmimas, greitųjų programų kūrėjas ir generatorius, o našumui pagerinti yra papildomų mazgų. AutoRAG Optimizavimas pasiekiamas kurdamas visas įmanomas modulių ir parametrų kombinacijas kiekviename mazge, vykdydamas konvejerį su kiekviena konfigūracija ir pasirinkdamas optimalų rezultatą pagal iš anksto nustatytas strategijas. Tada pasirinktas rezultatas iš ankstesnio mazgo tampa kito įvestis, o tai reiškia, kad kiekvienas mazgas veikia remdamasis geriausiu pirmtako rezultatu. Kiekvienas mazgas veikia nepriklausomai nuo to, kaip sukuriamas įvesties rezultatas, panašiai kaip Markovo grandinėje, kur kitai būsenai sugeneruoti reikalinga tik ankstesnė būsena, nežinant apie visą konvejerį ar ankstesnius veiksmus.

RAG modeliams įvertinti reikalingi duomenys, tačiau daugeliu atvejų tinkamų duomenų yra mažai arba jų visai nėra. Tačiau atsiradus dideliems kalbos modeliams (LLM), sintetinių duomenų generavimas tapo veiksmingas šio iššūkio sprendimas. Šiame vadove aprašoma, kaip naudoti LLM kuriant duomenis formatu, suderinamu su AutoRAG:
- Analizuojama: nustatykite YAML failą ir pradėkite analizuoti. Čia neapdorotus dokumentus galima išanalizuoti naudojant tik kelias kodo eilutes, kad būtų galima paruošti duomenis.
- Susmulkinti: Pradinėms kokybės užtikrinimo poroms sukurti naudojamas vienas korpusas, po kurio likęs korpusas susiejamas su kokybės užtikrinimo duomenimis.
- QA kūrimas: Kiekvienam korpusui reikalingas atitinkamas kokybės užtikrinimo duomenų rinkinys, jei keli korpusai generuojami skirtingais grupavimo metodais.
- QA-Corpus Mapping: kelių korpusų atveju likusieji korpuso duomenys gali būti susieti su kokybės užtikrinimo duomenų rinkiniu. Siekiant optimizuoti suskirstymą, RAG našumą galima įvertinti naudojant įvairius korpuso duomenis.
Tam tikri mazgai, pvz užklausos_išplėtimas arba prompt_makernegalima tiesiogiai įvertinti. Norint įvertinti šiuos mazgus, būtina nustatyti pagrindines tiesos vertes, tokias kaip „išplėstinės užklausos pagrindinė tiesa“ arba „pagrindinė užklausos tiesa“. Taikant šį metodą, dokumentai yra nuskaitomi vertinimo proceso metu naudojant tam skirtus modulius, o užklausos_išplėtimo mazgas įvertinamas pagal šiuos gautus dokumentus. Panašus požiūris taikomas ir prompt_maker ir generavimo mazgams, kur prompt_maker mazgas įvertinamas naudojant generavimo mazgo rezultatus. „AutoRAG“ šiuo metu yra alfa fazėje ir turi daugybę optimizavimo galimybių ateityje.
Apibendrinant galima pasakyti, kad AutoRAG yra automatizuotas įrankis, skirtas nustatyti optimalų RAG dujotiekį konkretiems duomenų rinkiniams ir naudojimo atvejams. Ji automatizuoja įvairių RAG modulių vertinimą naudodama savianalizės duomenis, palaikydama duomenų kūrimą, optimizavimą ir diegimą. Be to, „AutoRAG“ suskirsto dujotiekį į tarpusavyje sujungtus mazgus (pagrindą, greitųjų kūrimo ir generatorių) ir įvertina modulių ir parametrų derinius, kad surastų geriausią konfigūraciją. Sintetiniai LLM duomenys pagerina vertinimą. Šiuo metu alfa fazėje „AutoRAG“ siūlo didelį potencialą tolesniam RAG dujotiekio parinkimo ir diegimo optimizavimui ir plėtrai.
Patikrinkite GitHub Repo. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Tendencijos) „LLMWare“ pristato „Model Depot“: platų mažų kalbų modelių (SLM) kolekciją „Intel“ kompiuteriams

Sajjad Ansari yra paskutinių kursų IIT Kharagpur bakalauro studijos. Kaip technologijų entuziastas, jis gilinasi į praktinį AI taikymą, siekdamas suprasti AI technologijų poveikį ir jų realias pasekmes. Jis siekia aiškiai ir prieinamai išdėstyti sudėtingas AI koncepcijas.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️