

Dabartinis priežastinių kalbų modelių, tokių kaip GPT, dizainas iš esmės yra apsunkintas semantinės darnos iššūkiu ilgesniais atkarpomis, nes jų numatymas yra vienu žetonu į priekį. Tai įgalino reikšmingą generatyvų AI vystymąsi, bet dažnai sukelia „temų nukrypimą“, kai sukuriamos ilgesnės sekos, nes kiekvienas numatomas prieigos raktas priklauso tik nuo ankstesnių žetonų buvimo, o ne iš platesnės perspektyvos. Tai susiaurina šių modelių praktinį naudingumą sudėtingose realaus pasaulio programose, kuriose griežtai laikomasi temų, pvz., naratyvo generavimo, turinio kūrimo ir kodavimo užduotyse. Įveikus šį iššūkį įjungus kelių žetonų numatymą, dabartinių generatyvinės kalbos modelių sugeneruotų sekų semantinis tęstinumas, tikslumas ir nuoseklumas labai pagerėtų.
Daugelio žetonų numatymas buvo sprendžiamas įvairiais būdais, kurių kiekvienas turi skirtingus apribojimus. Modeliai, kuriais siekiama numatyti kelių prieigos raktų skaičių skaidydami įterpimus arba turintys kelias kalbų galvutes, reikalauja daug skaičiavimo ir dažnai neveikia gerai. „Seq2Seq“ modeliams kodavimo ir dekoderio rinkiniuose, nors tai leidžia numatyti kelių žetonų skaičių, jie nesugeba užfiksuoti praeities kontekstų į vieną įterpimą; taigi, atsiranda daug neefektyvumo. Nors BERT ir kiti užmaskuotų kalbų modeliai gali numatyti kelis užmaskuotus sekos žetonus, jie nepavyksta generuojant iš kairės į dešinę, todėl ribojamas jų naudojimas nuosekliam teksto numatymui. Kita vertus, ProphetNet naudoja n-gramų numatymo strategiją; nepaisant to, tai nėra lanksti įvairiems duomenų tipams. Pagrindiniai minėtų metodų trūkumai yra mastelio keitimo problemos, skaičiavimo švaistymas ir apskritai neįspūdingi rezultatai generuojant aukštos kokybės prognozes dėl ilgo konteksto problemų.
Tyrėjai iš EPFL pristato ateities žetonų numatymo modelį, atspindintį naują architektūrą, skirtą sukurti platesnio konteksto žetonų įterpimus. Tai leis sklandžiai prognozuoti kelių žetonų skaičių, kai, priešingai nei standartiniai modeliai, įterpimas iš viršutinių sluoksnių naudojamas transformatoriaus kodavimo įrenginiu, kad būtų sukurtos „pseudo sekos“, kurias kryžmiškai valdo mažas transformatoriaus dekoderis, kad būtų galima nuspėti kitą žetoną. Tokiu būdu modelis išnaudoja tokią FTP kodavimo ir dekodavimo funkciją, kad būtų išsaugota konteksto informacija iš ankstesnės istorijos žetonų, kad būtų sklandesni perėjimai ir išlaikoma temos nuoseklumas kelių žetonų prognozėse. Su plačiau paplitusiu sekos kontekstu, užkoduotu jo įterptuose, FTP užtikrina stipresnį generuojamų sekų tęstinumą ir tapo vienu geriausių turinio generavimo ir kitų programų, kurioms reikalinga ilgos formos semantinė darna, būdų.

FTP modelyje naudojama modifikuota GPT-2 architektūra, sudaryta iš 12 sluoksnių koduotuvo su 3 sluoksnių dekoderiu. Jo koduotuvas generuoja žetonų įterpimus, kurie tiesiškai projektuojami į aukštesnį matmenį į 12 dimensijų pseudo seką, kurią dekoderis kryžmiškai dalyvauja, kad suprastų sekos kontekstą. Jis dalijasi įterpimo svoriais tarp koduotuvo ir dekoderio; jis yra apmokytas OpenWebText duomenimis ir naudoja GPT-2 prieigos raktą. Tuo tarpu optimizavimą atlieka „AdamW“, kurio partijos dydis yra 500, o mokymosi greitis yra 4e–4. Šiame modelyje gama parametras nustatytas į 0,8, kad ateityje būtų palaipsniui mažinamas dėmesys, skiriamas žetonams, kad tiesioginės prognozės išliktų labai tikslios. Tokiu būdu FTP modelis sugeba išlaikyti semantinę darną be didelių skaičiavimo išlaidų ir taip randa optimalų kompromisą tarp efektyvumo ir našumo.
Šie rezultatai ir įvertinimas iš tikrųjų rodo, kad modelis, palyginti su tradiciniais GPT, žymiai pagerina daugelį pagrindinių našumo rodiklių: žymiai sumažina painiavą, geresnis nuspėjamasis tikslumas ir didesnis stabilumas atliekant ilgos sekos užduotis. Taip pat gaunami didesni atminimo, tikslumo ir F1 balai atliekant BERT pagrįstus teksto kokybės vertinimus, o tai dar labiau reikštų geresnį semantinį derinimą su faktinėmis teksto sekomis. Jis taip pat lenkia GPT modelius atliekant teksto klasifikavimo užduotis, pvz., IMDB ir „Amazon“ apžvalgas, ir visada užtikrina geresnį patvirtinimo praradimą ir didesnį tikslumą. Dar svarbiau, kad FTP nuosekliau seka sugeneruoto teksto temą, palaikoma aukštesnio kosinuso panašumo balų atliekant ilgos sekos vertinimus, o tai dar labiau sustiprina jos gebėjimą kurti nuoseklų, kontekstui tinkamą turinį įvairiose programose.
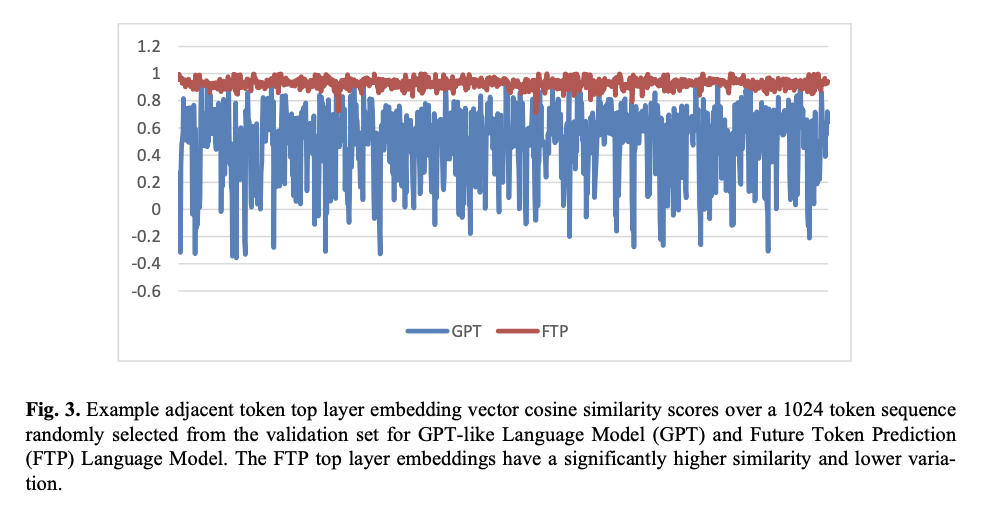
FTP modelis parodo priežastinės kalbos modeliavimo paradigmos pokytį, kuris išugdo svarbiausius klasikinių vieno žetono metodų neveiksmingumus į įterpimą, kuris palaiko platesnius ir kontekstui jautrius vaizdus, kuriant numatyti kelių žetonų prognozes. Padidinus numatymo tikslumą ir semantinę nuoseklumą, šį skirtumą pabrėžia patobulinti balai tiek sumaišties, tiek BERT pagrįstos metrikos atliekant įvairias užduotis. Šiame modelyje esantis pseudo-sekos kryžminio dėmesio mechanizmas pagerina generatyvųjį dirbtinį intelektą, sukeldamas nuoseklų pasakojimo srautą – tai svarbus reikalavimas, kad būtų užtikrinta didelė temos nuoseklios kalbos modeliavimo vertė visose programose, kurioms reikalingas semantinis vientisumas.
Patikrinkite Popierius. Visi nuopelnai už šį tyrimą tenka šio projekto tyrėjams. Taip pat nepamirškite sekti mūsų Twitter ir prisijunk prie mūsų Telegramos kanalas ir LinkedIn group. Jei jums patinka mūsų darbai, jums patiks ir mūsų darbai naujienlaiškis.. Nepamirškite prisijungti prie mūsų 55k+ ML SubReddit.
(Tendencijos) „LLMWare“ pristato „Model Depot“: platų mažų kalbų modelių (SLM) kolekciją „Intel“ kompiuteriams
Aswin AK yra MarkTechPost konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute, Kharagpur. Jis yra aistringas duomenų mokslui ir mašininiam mokymuisi, turintis tvirtą akademinį išsilavinimą ir praktinę patirtį sprendžiant realaus gyvenimo kelių sričių iššūkius.
Klausykite mūsų naujausių AI podcast'ų ir AI tyrimų vaizdo įrašų čia ➡️




