

Matematiniai didelių kalbos modeliai (LLM) parodė stiprias problemų sprendimo galimybes, tačiau jų samprotavimo galimybes dažnai riboja modelio atpažinimas, o ne tikras konceptualus supratimas. Dabartiniai modeliai labai grindžiami panašių įrodymų poveikiu, kaip jų mokymo dalis, o jų ekstrapoliacija reiškia naujas matematines problemas. Šis suvaržymas neleidžia LLMS įsitraukti į pažangias matematinius samprotavimus, ypač problemoms, reikalaujančioms diferenciacijos tarp glaudžiai susijusių matematinių koncepcijų. Pažangi samprotavimo strategija, paprastai trūksta LLMS, yra „CookeSample“ įrodymas – pagrindinis klaidingų matematinių teiginių paneigimo būdas. Tai, kad nepakankamai gaminamas ir įdarbinti „Counterexamples“, trukdo LLMS konceptualiems pažengusios matematikos samprotavimams, taigi sumažėja jų patikimumas formalioje teoremos patikrinime ir matematiniame tyrinėjime.
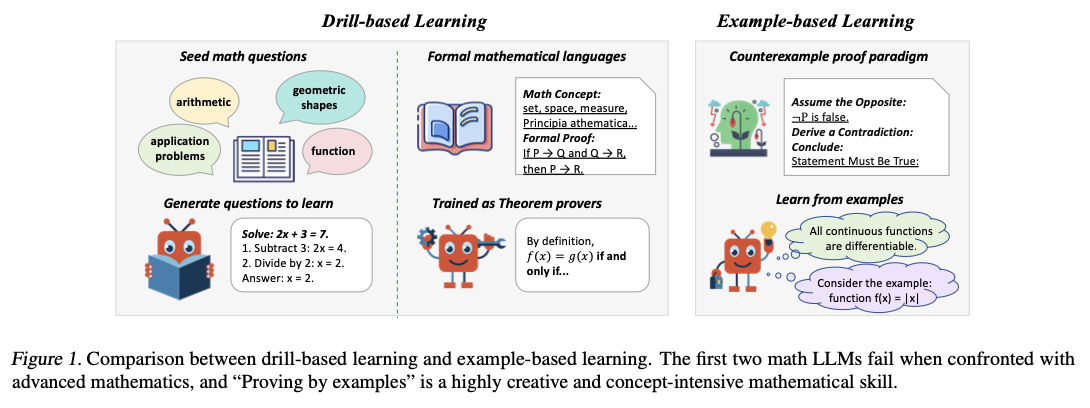
Ankstesni bandymai pagerinti matematinius samprotavimus LLM buvo suskirstyti į du bendrus metodus. Pirmasis požiūris, sintetinės problemos generavimas, moko LLMS dideliuose duomenų rinkiniuose, susidarančiuose iš sėklų matematikos problemų. Pavyzdžiui, „WizardMath“ naudoja GPT-3,5, kad sukeltų skirtingo sunkumo lygio problemas. Antrasis požiūris, oficiali teorema, įrodanti, moko modelius dirbti su tokiomis įrodinėjimo sistemomis kaip „Lean 4“, kaip ir skandalininko ir „Lean-Star“, kurie padeda LLMS struktūrizuotai teoremai įrodyti. Nors šie požiūriai turi didesnį problemų sprendimo galimybes, jie turi sunkių apribojimų. Sintetiniai klausimų generavimas sukelia įsimenimą, o ne iš tikrųjų supranta, todėl modeliai yra pažeidžiami nesėkmių susidūręs su naujomis problemomis. Kita vertus, oficialios teoremos teikimo metodai yra ribojami tuo, kad yra pagrįsti struktūrizuotomis matematinėmis kalbomis, kurios riboja jų pritaikymą įvairiems matematiniams kontekstams. Šie apribojimai pabrėžia alternatyvios paradigmos poreikį – paradigmą, susijusią su konceptualiu supratimu, o ne modelio atpažinimu.
Norint išspręsti šiuos apribojimus, pristatomas į pavyzdį skatinamas matematinių samprotavimų etalonas, žinomas kaip „Countermath“. Etalonas yra specialiai sukurtas įvertinti ir sustiprinti LLMS naudojimą „Counterexamples“ įrodymuose. Naujovės apima aukštos kokybės etaloną, duomenų inžinerijos procesą ir išsamų modelio vertinimą. Kovos su 1 216 matematiniais teiginiais sudaro 1 216, kurių kiekvienam reikia paneigti. Problemos yra rankomis iš universiteto vadovėlių ir plačiai patvirtina ekspertai. Norint patobulinti LLMS pavyzdžių pagrindu pagrįstus pagrindus, įgyvendinamas automatizuotas duomenų rinkimo procesas, filtruojant ir tobulinant matematinius įrodymų duomenis, kad būtų galima gauti pavyzdžių pagrindu pagrįstus samprotavimo pavyzdžius. Šiuolaikinio matematinių LLM, pavyzdžiui, Openai O1 modelis ir tiksliai sureguliuoti atvirojo kodo variantai, veiksmingumas yra griežtai tiriamas priešpriešinį. Šis metodas nukreipdamas dėmesį į pagrindus pagrįstus samprotavimus iš išskirtinės teoremos pateikimo, šis metodas inicijuoja naują ir nepakankamai ištirtą kelią į matematinių LLM mokymą.

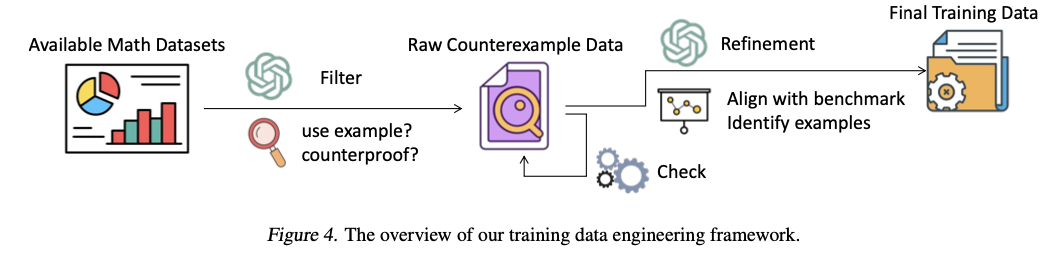
Kovos su keturiomis pagrindinėmis matematinėmis disciplinomis sudaromas: algebra, topologija, tikroji analizė ir funkcinė analizė. Duomenys yra sukurti kelių žingsnių procese. Pirmiausia matematiniai teiginiai renkami iš vadovėlių ir paverčiami į struktūrizuotus duomenis per OCR. Tada matematikai peržiūri ir komentuoja kiekvieną loginio nuoseklumo ir tikslumo problemą. Profesionalūs vertimai atliekami kaip originalūs duomenys kinų, o po to – papildomus patikrinimus. Taip pat pateikiama duomenų inžinerijos inžinerijos sistema, skirta automatiškai nuskaityti mokymo duomenis, susijusius su pagrindu pagrįstais pavyzdžiais. Šioje sistemoje naudojami GPT-4o filtravimo ir tobulinimo metodai, skirti išgauti svarbius įrodymus iš išorinių šaltinių, tokių kaip „ProofNET“ ir „NaturalProfer“. Patobulinimas atliekamas siekiant užtikrinti, kad kiekvienas įrodymas aiškiai parodytų „Counterexamples“, kad LLM galėtų efektyviau išmokti samprotavimus, pagrįstus vaizdais.
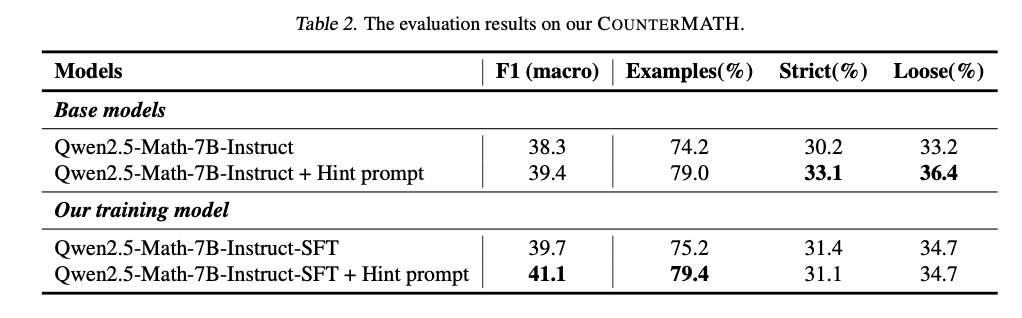
Apie moderniausių matematinių LLM įvertinimą, susijusį su kontratvatu, atskleidžia reikšmingus pagrindų pavyzdžius pagrįstų samprotavimų spragas. Didžioji dalis modelių nepriima sprendimo, ar teiginys yra teisingas, ar klaidingas naudojant „Counterexamples“, atspindėdami gilų konceptualų silpnumą. Našumas taip pat yra nevienodos matematinėse srityse, o algebra ir funkcinė analizė veikia geriau, o topologija ir tikroji analizė vis dar yra labai sudėtinga dėl jų abstraktaus pobūdžio. Atvirojo kodo modeliai veikia blogiau nei patentuotų modelių, tik keli turi vidutinio sunkumo konceptualius samprotavimus. Vis dėlto patobulinimas su pavyzdžiu pagrįstais duomenimis žymiai padidina našumą, geresnį sprendimo tikslumą ir pagrindu pagrįstus samprotavimus. Tinkamai suderintas modelis, turintis tik 1 025 mokymo pavyzdžius paremtus pavyzdžiu, veikia žymiai geriau nei jo pradinės versijos ir turi stiprią apibendrinimą dėl nepaskirstymo matematinių testų. Išsamus 1 lentelėje pateiktas vertinimas parodytas našumo palyginimai, pagrįsti F1 balais ir samprotavimo nuoseklumo metriku. „Qwen2.5-Math-72B-Instruct“ veikia geriausiai (41,8 F1) tarp atvirojo kodo modelių, tačiau atsilieka nuo patentuotų modelių, tokių kaip GPT-4O (59,0 F1) ir „Openai O1“ (60,1 F1). Tinkamas derinimas lemia didelę naudą: „QWEN2.5-Math-7B-Instruct-Sft + Hint“ ragina pasiekti 41,1 F1, patvirtindamas mokymo pavyzdžiu veiksmingumą.

Šis siūlomas metodas pateikia „Countermath“-tai pavyzdžiu pagrįstų samprotavimo etalonų, skirtų pagerinti LLMS koncepcinius matematinius sugebėjimus. Gerai sukuriamų problemų rinkinių panaudojimas ir automatizuotas duomenų tobulinimo procesas rodo, kad esamos LLM neturi gilių matematinių samprotavimų, tačiau juos galima žymiai patobulinti mokant į pavyzdį. Šie rezultatai rodo, kad būsimi AI tyrimai turi būti sutelkti į konceptualaus supratimo, o ne ekspozicijos pagrindu mokymosi gerinimą. „CoundExample“ samprotavimai yra ne tik matematikos, bet ir logikos, mokslinio tyrimo ir oficialaus patikrinimo, todėl šis metodas gali būti išplėstas į įvairias AI pagrįstų analitinių užduočių įvairovę.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama „Read-LG AI Research“ išleidžia „Nexus“: pažangių sistemos integracinių agentų AI sistemos ir duomenų atitikties standartų, skirtų teisiniams klausimams spręsti AI duomenų rinkiniuose
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.





