

Naujausios diskusijos dėl AI saugos vis labiau susieja egzistencinę riziką, kurią kelia pažengusiųjų AI, ir tai rodo, kad saugumo sprendimas iš prigimties apima katastrofiškų scenarijų svarstymą. Tačiau ši perspektyva turi trūkumų: ji gali pašalinti tyrėjus, turinčius skirtingą požiūrį, suklaidinti visuomenę galvoti apie AI saugumą tik dėl egzistencinių grėsmių ir sukurti atsparumą skeptikams. AI sparčiai tobulėjant, politikos formuotojai turi nustatyti reguliavimo sistemas ir saugos standartus. Nors dabartiniame diskurse dominuoja egzistencinė rizika, ankstesnės technologinės saugos sritys, tokios kaip aviacija, vaistai ir kibernetinis saugumas, sukūrė tvirtą inžinerijos ir valdymo praktiką. Šios sistemos galėtų informuoti AI saugą, užtikrinant patikimą ir atsakingą sistemos diegimą.
Edinburgo universiteto ir Carnegie Mellon universiteto tyrėjai pabrėžia, kad AI saugos diskusijose dažnai dėmesio skiriama egzistencinei rizikai, kuri gali neįtraukti įvairių perspektyvų ir klaidinti visuomenės suvokimą. Jų sisteminė recenzuojamų tyrimų apžvalga atskleidžia platų saugos problemų spektrą, įskaitant prieštaringą tvirtumą ir aiškumą, suderinant su tradicine sistemos saugos praktika. Tyrime siūloma integruoti artimiausio laikotarpio ir ilgalaikę riziką, o ne prioritetą teikti egzistencinėms grėsmėms. Nors AI saugos tyrimai greitai vystosi, atitinkamų tyrimų fiksavimas išlieka sudėtingas. Išplečiant diskursą, įtraukiant nustatytus inžinerinių saugos principus, galite padėti veiksmingai išspręsti neatidėliotiną ir būsimą AI riziką.
Tyrėjai sistemingai apžvelgė AI saugos literatūrą, naudodami struktūrizuotą metodiką, pagrįstą „Kitchenham“ ir „Charters“ gairėmis, kurias papildo sniego gniūžtės atranka, kad būtų galima užfiksuoti kylančius tyrimus. Jie sutelkė dėmesį į du pagrindinius tyrimų klausimus: nustatyti riziką visame AI sistemos gyvavimo cikle ir įvertinti siūlomas švelninimo strategijas. Jų paieškos procesas apėmė užklausą dėl mokslo interneto (WOS) ir SCOPUS duomenų bazių, tobulinant rezultatus per hierarchinius filtrus ir papildant išvadas su įtakingais sėklų dokumentais. Peržiūros procesą apėmė 2666 duomenų bazės dokumentų ir 117 atranką iš sniego gniūžtės mėginių ėmimo, galiausiai 383 pasirinkus analizę. Straipsniai buvo anotuoti su metaduomenimis, tokiais kaip autorių priklausomybės, publikavimo metai ir citavimo skaičius, ir buvo suskirstyti į kategorijas pagal metodinius metodus, konkrečias nagrinėjamas saugos problemas ir rizikos mažinimo strategijas.
Tyrimo bibliometrinė analizė atskleidė stabilų AI saugos tyrimų padidėjimą nuo 2016 m., Kurią lėmė giluminio mokymosi pažanga. Žodžių debesies analizė išryškino pagrindines temas, tokias kaip saugaus stiprinimo mokymasis, prieštaringų tvirtumas ir domenų adaptacija. Bendrame abstrakčių terminų grafike buvo nustatytos keturios pagrindinės tyrimų grupės: (1) AI žmogaus ir visuomenės padariniai, daugiausia dėmesio skiriant pasitikėjimui, atskaitomybe ir saugumo užtikrinimui; (2) saugus sustiprinimo mokymasis, pabrėžiant tvirtą agento kontrolę neaiškioje aplinkoje; (3) prižiūrimas mokymasis, ypač atliekant klasifikavimo užduotis, daugiausia dėmesio skiriant tvirtumui, apibendrinimui ir tikslumui; ir (4) prieštaringos atakos ir gynybos strategijos giluminio mokymosi modeliuose. Rezultatai rodo, kad AI saugos tyrimai suderinami su tradiciniais saugos inžinerijos principais, integruojant patikimumo inžinerijos aspektus, kontrolės teoriją ir kibernetinį saugumą, kad būtų užtikrinta, jog AI sistemos yra veiksmingos ir saugios.
AI saugos tyrimai suskirstė riziką į aštuonis tipus: triukšmą, stebėjimo trūkumą, klaidingą sistemos sistemą ir prieštarines atakas. Daugelyje tyrimų nagrinėjamos problemos, susijusios su triukšmu ir pašaliniais asmenimis, turinčiais įtakos modelio tvirtumui ir apibendrinimui. Didelis dėmesys taip pat sutelktas į nesėkmių stebėjimą, sistemos klaidų specifikacijas ir kontrolės vykdymo spragas. Tyrimo metodai apima taikomuosius algoritmus, imituotus agentus, analizės sistemas ir mechaninį aiškumą. Nors teoriniai darbai siūlo koncepcinius modelius, taikomieji tyrimai sukuria praktinius algoritmus. Naujausiose pastangose pabrėžiamas sustiprinimo mokymosi sauga, prieštaringas tvirtumas ir paaiškinimas. Laukas yra lygiagretus tradicinei inžinerijos saugai, integruojant patikros metodus, siekiant pagerinti AI patikimumą ir sušvelninti galimą riziką.
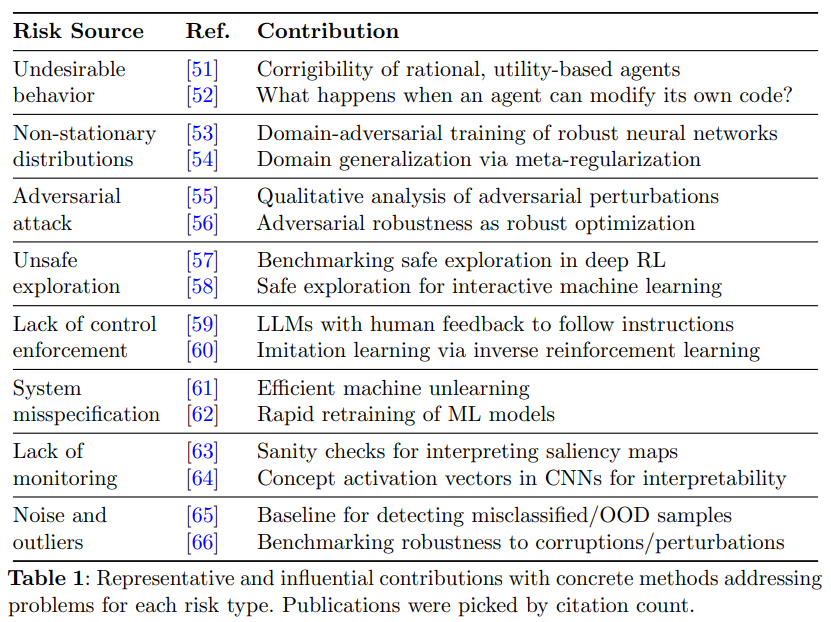
Apibendrinant, tyrimas sistemingai apžvelgė recenzuojamą literatūrą, siekiant ištirti AI saugos iššūkius. Rezultatai pabrėžia įvairius motyvus ir tyrimų rezultatus, kuriais siekiama užtikrinti AI sistemas patikimos ir naudingos. PG saugos tyrimai apima įvairią riziką, įskaitant projektavimo trūkumus, tvirtumo problemas, netinkamą stebėjimą ir įterptą šališkumą. Tyrimas pasisako už PG saugos įrėminimo platesnę technologinę saugą, plečiant suinteresuotųjų šalių įsitraukimą ir įtraukiančių tyrimų skatinimą. Nors egzistencinė rizika išlieka aktuali, platesnė perspektyva skatina produktyvų diskursą. Būsimi tyrimai turėtų ištirti sociotechninę AI saugą ir įtraukti ne apžvelgiamus šaltinius, kad būtų galima išsamiai suprasti, užtikrinant, kad PG sauga išliks besivystanti, įtraukianti ir daugiadalykinė sritis.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama „Read-LG AI Research“ išleidžia „Nexus“: pažangių sistemos integracinių agentų AI sistemos ir duomenų atitikties standartų, skirtų teisiniams klausimams spręsti AI duomenų rinkiniuose
„MarktechPost“ ir „IIT Madras“ dvigubo laipsnio studentė konsultacinė Sana Hassan aistringai taiko technologijas ir AI, kad galėtų spręsti realaus pasaulio iššūkius. Turėdamas didelį susidomėjimą išspręsti praktines problemas, jis pateikia naują perspektyvą AI ir realaus gyvenimo sprendimų sankryžai.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (reklamuojama)




