

Stiprinimo mokymasis (RL) moko agentus priimti nuoseklius sprendimus, maksimaliai padidindamas kaupiamąjį atlygį. Jis turi įvairių programų, įskaitant robotiką, žaidimus ir automatizavimą, kai agentai sąveikauja su aplinka, kad išmoktų optimalų elgesį. Tradiciniai RL metodai skirstomi į dvi kategorijas: be modelių ir modeliais pagrįstų metodų. Modeliai be modelių teikia pirmenybę paprastumui, tačiau reikalauja išsamių mokymo duomenų, o modeliais pagrįsti metodai įveda struktūrizuotą mokymąsi, tačiau yra skaičiuojami. Auganti tyrimų sritis siekiama panaikinti šiuos metodus ir sukurti universalias RL sistemas, kurios efektyviai veikia skirtingose srityse.
Nuolatinis iššūkis RL yra universalus algoritmas, galintis nuosekliai atlikti įvairiose aplinkose be išsamaus parametrų derinimo. Daugelis RL algoritmų yra skirti konkrečioms programoms, todėl reikia koreguoti veiksmingai veikiant naujuose nustatymuose. Modeliais pagrįsti RL metodai paprastai rodo puikų apibendrinimą, tačiau didesnio sudėtingumo ir lėtesnio vykdymo greičio kainą. Kita vertus, metodus be modelių yra lengviau įgyvendinti, tačiau dažnai jų nėra, kai jie taikomi nepažįstamoms užduotims. Pagrindinis tyrimo tikslas išlieka RL sistemos sukūrimas, kuris integruoja abiejų metodų stipriąsias puses, nepakenkiant skaičiavimo galimybėms.
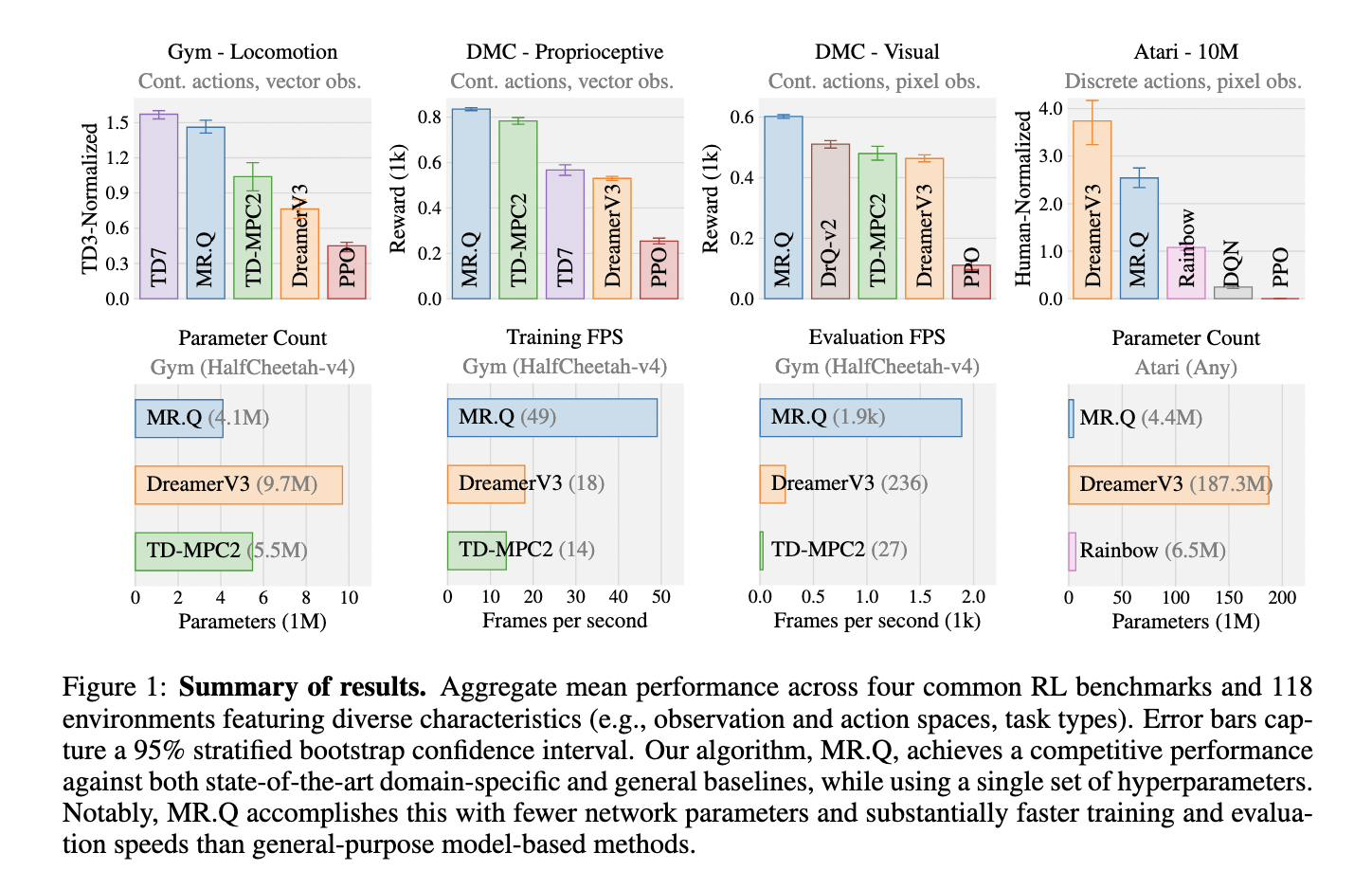
Atsirado keletas RL metodikų, kurių kiekviena turi kompromisą tarp našumo ir efektyvumo. Modeliais pagrįsti sprendimai, tokie kaip „Dreamerv3“ ir „TD-MPC2“, pasiekė esminių rezultatų atliekant skirtingas užduotis, tačiau labai priklauso nuo sudėtingų planavimo mechanizmų ir didelio masto modeliavimo. Alternatyvos be modelių, įskaitant TD3 ir PPO, siūlo mažesnius skaičiavimo poreikius, tačiau reikalauja konkrečios srities derinimo. Šis skirtumas pabrėžia RL algoritmo, kuris derina pritaikomumą ir efektyvumą, poreikį, leidžiantį sklandų taikymą įvairiose užduotyse ir aplinkose.
Tyrimų komanda iš „Meta Fair“ pristatė Mr.Q, be modelio RL algoritmą, kuriame pateikiami modeliais pagrįstos reprezentacijos, siekiant pagerinti mokymosi efektyvumą ir apibendrinimą. Skirtingai nuo tradicinių metodų be modelių, Mr.Q pasitelkia reprezentacinio mokymosi etapą, įkvėptą modeliais pagrįstų tikslų, leidžiančių algoritmui efektyviai veikti skirtinguose RL etalonuose su minimaliu derinimu. Šis metodas leidžia Mr.Q pasinaudoti struktūrizuotais modeliais pagrįstų metodų mokymosi signalais, vengiant skaičiavimo pridėtinių išlaidų, susijusių su viso masto planavimu ir imituojamais diegimais.
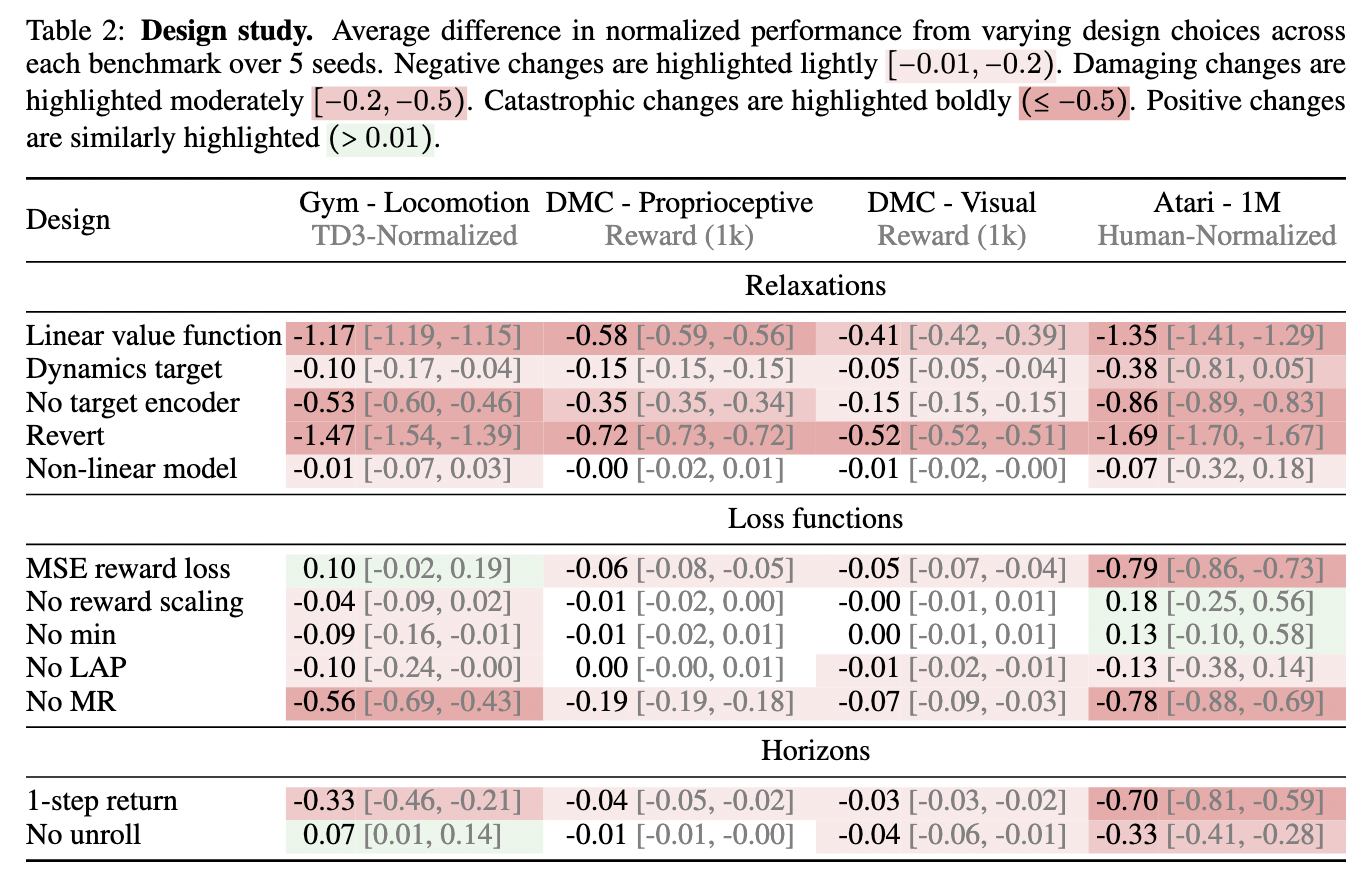
„Mr.Q Framework“ susiejo valstybės veiksmo poras į įterptuves, kurios palaiko maždaug linijinį ryšį su vertės funkcija. Tada šie įterpimai apdorojami netiesine funkcija, kad būtų išlaikyta nuoseklumas įvairiose aplinkose. Sistema integruoja kodavimo įrenginį, kuris išgauna svarbias savybes iš būsenos ir veiksmų įvesties, padidindama mokymosi stabilumą. Be to, Mr.Q naudoja prioritetinę imčių ėmimo techniką ir atlygio mastelio mechanizmą, kad pagerintų treniruočių efektyvumą. Algoritmas pasiekia patikimą našumą keliuose RL etalonuose, išlaikydamas skaičiavimo efektyvumą, sutelkiant dėmesį į optimizuotą mokymosi strategiją.
Eksperimentai, atlikti atliekant keturis RL etalonus – „Gym Locomotion“ užduotis, „Deepmind Control Suite“ ir „Atari“ – nurodo, kad Mr.Q pasiekia stiprių rezultatų su vienu hiperparametrų rinkiniu. Algoritmas pralenkia įprastus bazinius bazinius linijas, tokias kaip PPO ir DQN, išlaikydamas palyginamą našumą su „Dreamerv3“ ir „TD-MPC2“. Mr.Q pasiekia konkurencinių rezultatų, tuo pačiu panaudodamas žymiai mažiau skaičiavimo išteklių, todėl tai yra praktiškas pasirinkimas realaus pasaulio programoms. „Atari“ etalone Mr.Q ypač gerai veikia diskretinio veiksmo erdvėse, pranokdamas esamus metodus. Mr.Q demonstruoja stiprią veikimą nuolatinėje kontrolės aplinkoje, viršijant bazines linijas be modelių, tokių kaip PPO ir DQN, išlaikant konkurencinius rezultatus, palyginti su „Dreamerv3“ ir „TD-MPC2“. Algoritmas pasiekia reikšmingą efektyvumo pagerėjimą visuose etalonuose, nereikalaujant išsamaus skirtingų užduočių pertvarkymo. Vertinimas dar labiau pabrėžia Mr.Q sugebėjimą efektyviai apibendrinti, nereikalaujant didelės naujų užduočių pertvarkymo.
Tyrimas pabrėžia modeliais pagrįstų reprezentacijų į RL algoritmų įtraukimo į modelius pranašumus. Mr.Q žymi žingsnį siekiant sukurti tikrai universalią RL sistemą, padidindamas efektyvumą ir pritaikomumą. Būsimi pažanga galėtų patobulinti savo požiūrį į iššūkius, tokius kaip sunkių tyrinėjimų problemos ir ne Markovijos aplinka. Rezultatai prisideda prie platesnio tikslo padaryti RL metodus prieinamesnius ir veiksmingesnius daugeliui programų, o M.Q nurodo kaip perspektyvų įrankį tyrėjams ir praktikams, ieškantiems patikimų RL sprendimų.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 70K+ ml subreddit.
🚨 Susipažinkite su „Intellagent“: atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą (Paaukštintas)
Nikhil yra „MarkTechPost“ stažuotės konsultantas. Jis siekia integruoto dvigubo laipsnio medžiagų Indijos technologijos institute, Kharagpur mieste. „Nikhil“ yra AI/ML entuziastas, kuris visada tiria programas tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagos mokslo patirtį, jis tyrinėja naujus pasiekimus ir sukuria galimybes prisidėti.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo





