

Sekos yra universali abstrakcija, skirta atstovauti ir apdoroti informaciją, todėl sekos modeliavimas yra pagrindinis šiuolaikinio giluminio mokymosi metu. Įrėminant skaičiavimo užduotis kaip transformacijas tarp sekų, ši perspektyva buvo išplėsta į įvairias sritis, tokias kaip NLP, kompiuterio matymas, laiko eilučių analizė ir skaičiavimo biologija. Tai paskatino įvairių sekų modelių, įskaitant transformatorius, pasikartojančius tinklus ir konvoliucinius tinklus, kūrimą, kiekvienas išskirtinus konkrečiuose kontekstuose. Tačiau šie modeliai dažnai atsiranda atliekant suskaidytus ir empiriškai pagrįstus tyrimus, todėl sunku suprasti jų projektavimo principus arba sistemingai optimizuoti jų našumą. Dėl vieningos struktūros ir nuoseklių žymėjimų nebuvimas dar labiau užtemdo pagrindines ryšius tarp šių architektūrų.
Svarbiausia, kad būtų galima susieti skirtingus sekų modelius, yra ryšys tarp jų sugebėjimo atlikti asociatyvųjį prisiminimą ir kalbų modeliavimo efektyvumą. Pavyzdžiui, tyrimai atskleidžia, kad transformatoriai naudoja tokius mechanizmus kaip indukcinės galvutės, kad būtų galima laikyti žetonų poras, ir numatyti po žetonų. Tai pabrėžia asociatyvaus prisiminimo svarbą nustatant modelio sėkmę. Kyla natūralus klausimas: kaip mes galime sąmoningai suprojektuoti architektūras, kad galėtume tobulėti asociatyviu atšaukimu? Tai galėtų paaiškinti, kodėl kai kurie modeliai pralenkia kitus, ir nukreipti į efektyvesnių ir apibendrinamų sekų modelių sukūrimą.
Stanfordo universiteto tyrėjai siūlo vienijančią sistemą, jungiančią sekos modelius su asociatyvia atmintimi per regresijos atminties korespondenciją. Jie parodo, kad įsimenant raktų vertės poras prilygsta regresijos problemos sprendimui bandymo metu, siūlant sistemingą būdą projektuoti sekų modelius. Remdamasis architektūromis kaip regresijos tikslų pasirinkimu, funkcijų klasėmis ir optimizavimo algoritmais, sistema paaiškina ir apibendrina linijinį dėmesį, būsenos ir erdvės modelius ir „SoftMax“ dėmesį. Šis požiūris panaudoja dešimtmečius trunkančią regresijos teoriją, suteikdamas aiškesnį esamų architektūrų supratimą ir vadovaujant galingesnių, teoriškai pagrįstų sekų modelių plėtrai.
Sekos modeliavimui siekiama susieti įvesties žetonus į išvesties žetonus, kur asociacinis prisiminimas yra būtinas tokioms užduotims kaip kontekstinė mokymasis. Daugelis sekų sluoksnių įvestis paverčia raktų vertės poromis ir užklausomis, tačiau sluoksnių, turinčių asociatyvią atmintį, dizainui dažnai trūksta teorinio įžeminimo. Bandymo laiko regresijos sistema tai nagrinėja, traktuojant asociatyviąją atmintį kaip regresijos problemos sprendimą, kai atminties žemėlapis apytiksliai suderina reikšmes pagal raktus. Šis pagrindas suvienodina sekos modelius, apibrėždamas jų dizainą kaip tris pasirinkimus: priskirdami svorius asociacijoms, pasirenkant regresoriaus funkcijų klasę ir pasirinkdami optimizavimo metodą. Šis sistemingas požiūris įgalina principinę architektūros dizainą.
Norint įgalinti veiksmingą asociatyvųjį prisiminimą, labai svarbu sukurti konkrečios užduoties klavišų vertės poras. Tradiciniai modeliai naudoja linijines projekcijas užklausas, raktus ir vertybes, o naujausi metodai pabrėžia „trumpus konvoliacijas“, kad būtų geresnis našumas. Vieno bandymo laiko regresijos sluoksnio su viena trumpa konvoliucija pakanka, kad būtų galima išspręsti daugialypės kvalifikacijos asociatyvaus atšaukimo (MQAR) užduotis, sudarant „Bigram“ tipo klavišų vertės poras. Atminties talpa, o ne sekos ilgis nustato modelio našumą. Linijinis dėmesys gali išspręsti MQAR su stačiakampiais įterpimais, tačiau nepageidaujami rekursiniai mažiausi kvadratai (RLS) geriau veikia su didesniais raktų vertės rinkiniais, atsižvelgiant į pagrindinį kovariaciją. Šios išvados pabrėžia atminties pajėgumų ir pagrindinių konstrukcijų vaidmenį siekiant optimalaus atšaukimo.
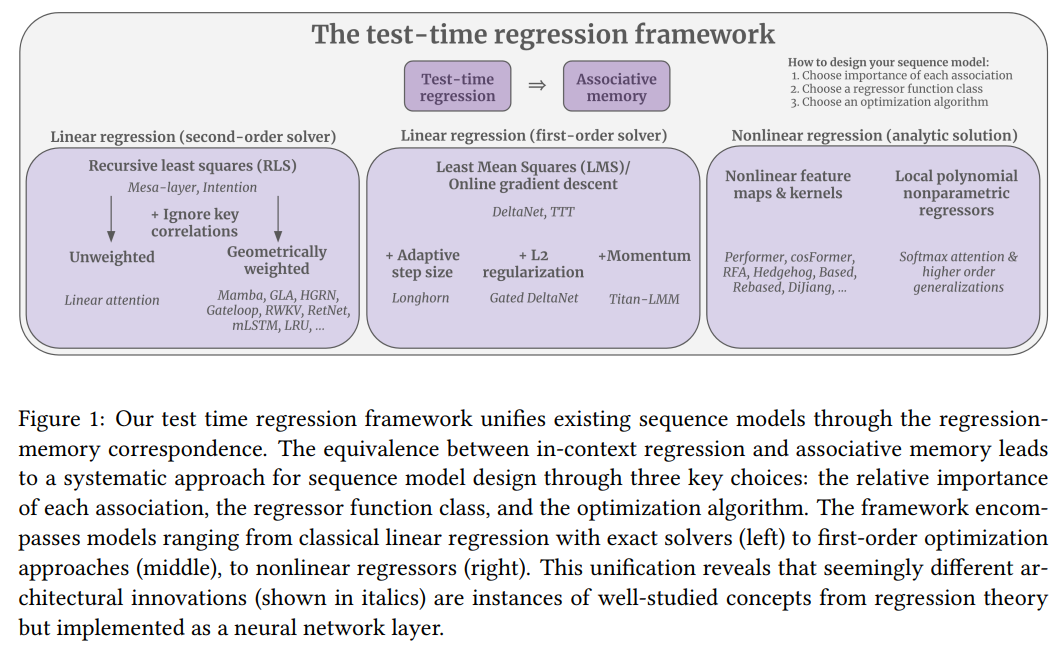
Apibendrinant, tyrime pateikiama vieninga sistema, kurioje sekos modeliai su asociatyvia atmintimi interpretuoja kaip bandymo laiko regresorius, kuriems būdingi trys komponentai: asociacijos svarba, regresoriaus funkcijų klasė ir optimizavimo algoritmas. Tai paaiškina architektūras, tokias kaip linijinis dėmesys, „SoftMax“ dėmesys ir besimokantieji internetu, įgyvendinant regresijos principus, siūlydama įžvalgas apie tokias funkcijas kaip „QKNorm“ ir aukštesnės eilės dėmesio apibendrinimai. Sistema pabrėžia vieno sluoksnio dizaino efektyvumą tokioms užduotims kaip MQAR, apeinant nereikalingų sluoksnių. Prijungiant sekų modelius prie regresijos ir optimizavimo literatūros, šis požiūris atveria būdus ateityje patobulinti adaptacinius ir efektyvius modelius, pabrėždamas asociatyvios atminties vaidmenį dinaminėje, realaus pasaulio aplinkoje.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 70K+ ml subreddit.
🚨 (Rekomenduojama skaityti) „Nebius AI Studio“ plečiasi su „Vision“ modeliais, naujais kalbų modeliais, įterpimais ir „Lora“ (Paaukštintas)
„MarktechPost“ ir „IIT Madras“ dvigubo laipsnio studentė konsultacinė Sana Hassan aistringai taiko technologijas ir AI, kad galėtų spręsti realaus pasaulio iššūkius. Turėdamas didelį susidomėjimą išspręsti praktines problemas, jis pateikia naują perspektyvą AI ir realaus gyvenimo sprendimų sankryžai.
📄





